幸田露伴の長篇未完小説『天うつ浪』につき、その『縦組みupLaTeX』化につき別項で大変お世話になりました。投稿の皆様に御礼申し上げます。投稿のテーマはこの小説にでてくる「御神籤(おみくじ)」を『縦組みupLaTeX』で、どう書いたら美しく初稿のように再現できるでしょうか……という事でしたが、これはお陰様で目的通り達成出來ました。その後、このように長篇小説は公表されている「青空文庫」に収録されているものであれば、text fileでも入手できるので、これを基に『縦組みupLaTeX』化すれば、美しく組版することは、きわめて容易です。私は今までにこの方法で、長篇では漱石『吾輩は猫である』、中編では芥川龍之介や幸田露伴からそれぞれ15編程度を、『讀みやすく、見て美し』くpdfにし、それらをハードカバーの「上製本」にし楽しんできました。ところが露伴の『天うつ浪』のように、「青空文庫」に収録されていないものは、可成りの「骨折り」となりますし、その課程は余り「意味ある骨折り」とはならないのではないか、と考えるようになりました。
ですのでもし『省力化』が図ることが可能であれば、TeX活用の有用な方法となるかもしれない、と思います。
既にこの小説(初版本では三分冊、岩波文庫では二分冊)のうち、「初稿の再現」を目ざす私は、「第一」は『手入力』が完了し、目下「第二」のうち60%位が完了している状態ですので、此の侭時間はかかるものの「第三」まで完了させる積もりです。そしてこの場をお借りして、未熟さ露呈にも拘わらず公開させていただこうと考えます。
一方で、text fileでは入手できないけれども、画像fileとしては、あるいはpdf fileとしてなら入手可能な文献は、もしtext file抽出が可能であれば、TeX化も容易となります。そうすれば、文芸作品のみならず論文などにも応用でき、役に立つのではないかと考えます。投稿にも、OCRからtext file抽出可能な方法につき、ご提案をいただきましたが、私がもともとtexnicianでない上に、80歳超という老齢で、技術対応は不可能と思います。幸いそうした事情をご存じかどうか分かりませんが、和田さんが、tryしようと動き始めるようなので、大いに心強く思つています。
それでは、小説『天うつ浪』の『第一』の完成したものは既に一度公開していますが、此に『柱』をつけ、ノンブルの位置を少し変えたもの(といっても、美文書の指定どおり、に過ぎない)を再公開させていただきます。
図書館から岩波文庫の方の後編を駆り出してきました。岩波文庫版の初刷りのようです。
春陽堂の初版本と比較してみました。
1) 総ルビではない
2) ところどころ長いルビの時、前後に空白が入っている
長くても入っていないものもある
3)一行が長い
4) 段落開始部分が字下がりしている
5) 「其XX」の番号は前編後編を通して採番(春陽堂のは巻毎)
6) ところどころ「其XX」の後に「セクション名」のような説明が付与されている
7) 会話文?引用文?の『「』が省略されるなど校正作業が行われている
8) 春陽堂版は 「其四十九」までだが、岩波の方は p-217 から 141 から 156 が追加されている
讀賣新聞には掲載されたものの「本」化?されなかったものかしら?
今日試したこと
1) 国会図書館の画像イメージを Google Drive で開いてテキスト化してみたけどあまり思わしくない
2) 同じものを iPad iPhone のファイルアプリで開きテキスト化してみたけどこれもあまり思わしくない
3) 借りてきた岩波文庫の門を Google レンズや iPad iPhone の同類アプリで試みたけど、
光源の影響か上部の一部を文字として認識できず
光源や原稿の置き方などの工夫が必要かも?
明日以降は tesseract をコマンドでできるか再挑戦
個人的には同音異義の問題はあるけれど、
最近の若者がスマフォで入り入りなテキストを書いているのを見習って
スマフォなどで音声入力が一番ストレスがないのではと考えています。
字が小さいので目が痛い :-(
春陽堂の初版本と比較してみました。
1) 総ルビではない
2) ところどころ長いルビの時、前後に空白が入っている
長くても入っていないものもある
3)一行が長い
4) 段落開始部分が字下がりしている
5) 「其XX」の番号は前編後編を通して採番(春陽堂のは巻毎)
6) ところどころ「其XX」の後に「セクション名」のような説明が付与されている
7) 会話文?引用文?の『「』が省略されるなど校正作業が行われている
8) 春陽堂版は 「其四十九」までだが、岩波の方は p-217 から 141 から 156 が追加されている
讀賣新聞には掲載されたものの「本」化?されなかったものかしら?
今日試したこと
1) 国会図書館の画像イメージを Google Drive で開いてテキスト化してみたけどあまり思わしくない
2) 同じものを iPad iPhone のファイルアプリで開きテキスト化してみたけどこれもあまり思わしくない
3) 借りてきた岩波文庫の門を Google レンズや iPad iPhone の同類アプリで試みたけど、
光源の影響か上部の一部を文字として認識できず
光源や原稿の置き方などの工夫が必要かも?
明日以降は tesseract をコマンドでできるか再挑戦
個人的には同音異義の問題はあるけれど、
最近の若者がスマフォで入り入りなテキストを書いているのを見習って
スマフォなどで音声入力が一番ストレスがないのではと考えています。
字が小さいので目が痛い :-(
和田さん、まことに有り難うございました。画像データのテキスト化といっても、なかなか手強いようですね。スマフォでの「読み上げ」による音声入力が最も近道ではないかしら、と和田さんのtry結果を読みながら思いました。いずれの方法でも大幅な編集作業が必要なことは、見えてきましたね。それでもスクラッチで一から入力するよりは『ラク』であれば、意味ある試みだと存じます。岩波文庫版の字が大きく読みやすかつたら、初稿版がノイズ少なく文字も鮮明であつたなら、『なにも苦勞してTeXでPDF化なぞいたしません』。そうでないから意味あいがあるのではと思います。私のような暇でボケかかっている老人に、お忙しい和田さんの貴重な時間を投入させて申し訳ないと思いつつ、誰かのお役に立つこともあろう事を期待して、コツコツ一文字ずつ吟味しながら入力しています。さっぱり生産性は向上しませんが……。でも和田さんのご努力に期待していますよ。
奥村さんの紹介されていたものはすごいですね。
これは後で試してみますが ... ちょっと朗報
岩波文庫の方を iPad(一眼) や iPhone(三ガン) のカメラアプリで撮影
したものからテキストを取り出すと Google レンズより認識が良いようです。
カメラアプリの中でもテキストは抽出できますが、
内容確認のため画像を取得して、それを ファイルアプリ で開いて
テキスト抽出し、誤認識やルビの補正作業が行えそうです。
mr2h さん今後編の何ページくらいまで進んでいますか?
とりあえずその先を今夜撮影しまくって、
明日の昼休み、ひたすらテキスト抽出とメモ帳貼り付け作業ができたらと思います。
ページ番号まで読み取っているので、画像との付き合わせもできやすいかと考えています。
これが一段落したら半自動化を考えたらなと思います。
これは後で試してみますが ... ちょっと朗報
岩波文庫の方を iPad(一眼) や iPhone(三ガン) のカメラアプリで撮影
したものからテキストを取り出すと Google レンズより認識が良いようです。
カメラアプリの中でもテキストは抽出できますが、
内容確認のため画像を取得して、それを ファイルアプリ で開いて
テキスト抽出し、誤認識やルビの補正作業が行えそうです。
mr2h さん今後編の何ページくらいまで進んでいますか?
とりあえずその先を今夜撮影しまくって、
明日の昼休み、ひたすらテキスト抽出とメモ帳貼り付け作業ができたらと思います。
ページ番号まで読み取っているので、画像との付き合わせもできやすいかと考えています。
これが一段落したら半自動化を考えたらなと思います。
和田さん、あまり進んでいなくて春陽堂の初稿で、第二の『其三十四』の途中、この初稿のページでいうと、107ページまで入力(pdf化)が完了しています。TeXの原稿でいうと、
------------------------------------------------------------------------------------------------------------------------------------------
『アッハヽハヽ、\ruby{甚}{ひど}い\ruby{氣焰}{き|\GWI{u1b001}ん}だナ、\ruby{怪人}{くわい|じん}の\ruby{怪語}{くわい|ご}だ。\ruby{皮肉}{ひ|にく}も\ruby{其}{それ}までになると\ruby{愛嬌}{あい|けう}が\ruby{出}{で}て\ruby{面白}{おも|しろ}い。アヽ\ruby{愉快}{ゆ|くわい}だ\ruby{大笑}{おほ|わら}ひに\ruby{笑}{わら}つたので\ruby{馬鹿}{ば|か}に\ruby{醉}{よ}つた。\ruby{久}{ひさ}しぶりで\ruby{一}{ひと}ッ\ruby{朗吟}{ろう|ぎん}をやるぞ。』
『\ruby{宣}{よ}からう。\ruby{長}{なが}い\ruby{事汝}{こと|きさま}の\ruby{怒鳴}{ど|な}るのも\ruby{聞}{き}かなかつたナア。』
----------------------------------------------------------------------------------------------------------------------------------------------------------
と、云つたところまでです。
------------------------------------------------------------------------------------------------------------------------------------------
『アッハヽハヽ、\ruby{甚}{ひど}い\ruby{氣焰}{き|\GWI{u1b001}ん}だナ、\ruby{怪人}{くわい|じん}の\ruby{怪語}{くわい|ご}だ。\ruby{皮肉}{ひ|にく}も\ruby{其}{それ}までになると\ruby{愛嬌}{あい|けう}が\ruby{出}{で}て\ruby{面白}{おも|しろ}い。アヽ\ruby{愉快}{ゆ|くわい}だ\ruby{大笑}{おほ|わら}ひに\ruby{笑}{わら}つたので\ruby{馬鹿}{ば|か}に\ruby{醉}{よ}つた。\ruby{久}{ひさ}しぶりで\ruby{一}{ひと}ッ\ruby{朗吟}{ろう|ぎん}をやるぞ。』
『\ruby{宣}{よ}からう。\ruby{長}{なが}い\ruby{事汝}{こと|きさま}の\ruby{怒鳴}{ど|な}るのも\ruby{聞}{き}かなかつたナア。』
----------------------------------------------------------------------------------------------------------------------------------------------------------
と、云つたところまでです。
続いてテキストデータ(1つにまとめたもの)
第3巻のもの同様に手動での作業によるミスがあるかもしれません。
第3巻のもの同様に手動での作業によるミスがあるかもしれません。
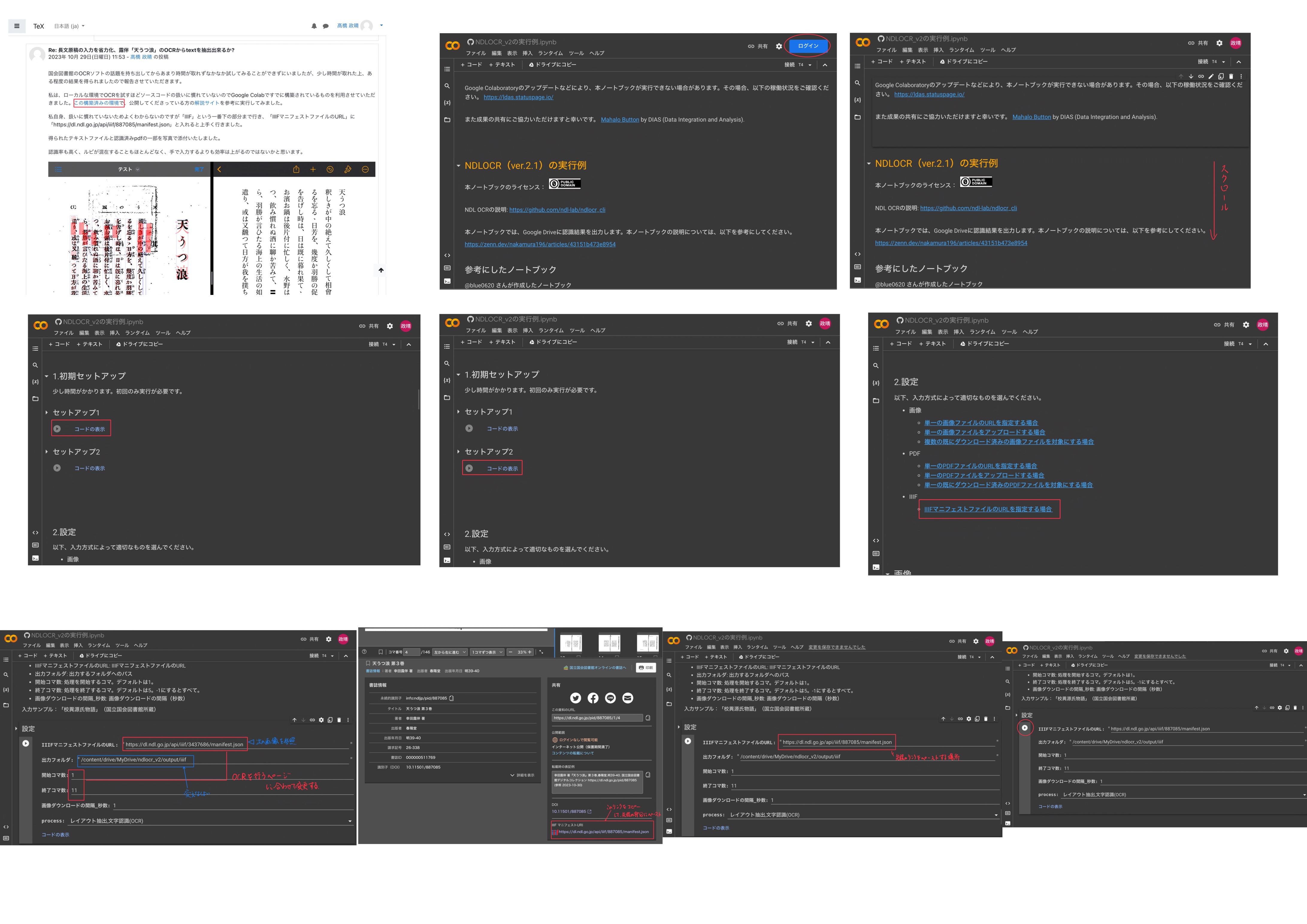
国会図書館のOCRソフトの話題を持ち出してからあまり時間が取れずなかなか試してみることができずにいましたが、少し時間が取れた上、ある程度の結果を得られましたので報告させていただきます。
私は、ローカルな環境でOCRを試すほどソースコードの扱いに慣れていないのでGoogle Colabですでに構築されているものを利用させていただきました。この構築済みの環境で、公開してくださっている方の解説サイトを参考に実行してみました。
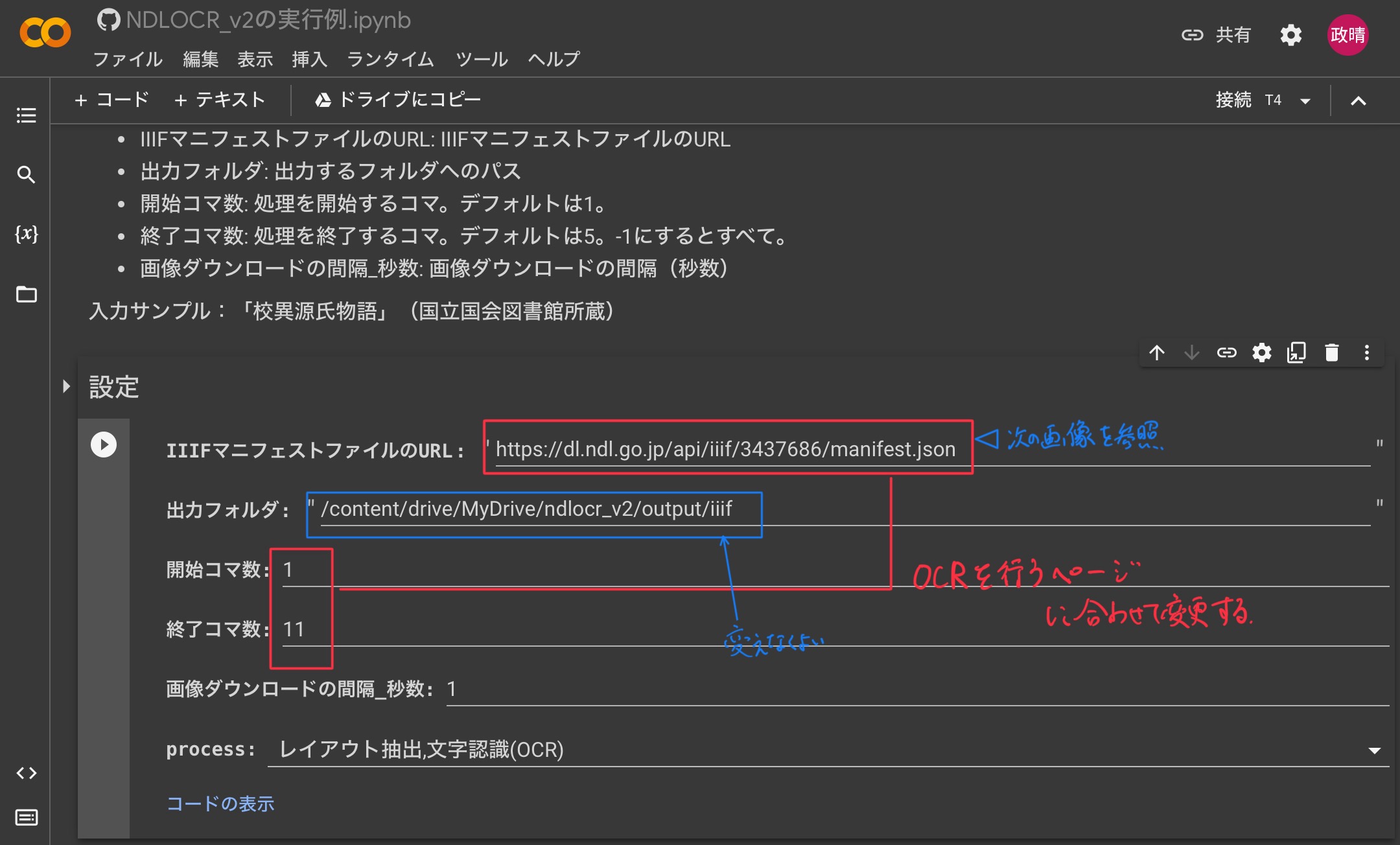
私自身、扱いに慣れていないためよくわからないのですが「IIIF」という一番下の部分まで行き、「IIIFマニフェストファイルのURL」に「https://dl.ndl.go.jp/api/iiif/887085/manifest.json」と入れると上手く行きました。
得られたテキストファイルと認識済みpdfの一部を写真で添付いたしました。
認識率も高く、ルビが混在することもほとんどなく、手で入力するよりも効率は上がるのではないかと思います。

せっかくなので第3巻の全てのページで、先ほどの構築されている環境を利用させていただいてOCRを実行してみました。
まずPDFを添付しておきます(改行、誤字訂正等をしておりません。また、139個のテキストファイルを手動で1つのテキストファイルにコピペしたので、二重でコピペしてしまったり、飛ばしてしまったページがあるかもしれません)。
まずPDFを添付しておきます(改行、誤字訂正等をしておりません。また、139個のテキストファイルを手動で1つのテキストファイルにコピペしたので、二重でコピペしてしまったり、飛ばしてしまったページがあるかもしれません)。
7月頃に改修されたロジックはよくなったのでしょうね。
認識度合いがよいので私の出番は今回は不要かな?
mr2hさんへ
とはいえ、春陽堂の初稿で掲載されてなくて岩波文庫のみのものとその巻末の解説を
iPad IPhone のカメラで撮影しテキスト抽出を試みます。
それから髙橋さんのを暫定で総ルビ化するのは割と手早く対応できますので、必要でしたら申しつけてください。
その際、 「公開版幸田露伴『天うつ浪』第一」「 天うつ浪第二改改」を参考にする予定です。
呟き ...
nvidia GPU 搭載マシンを入手するか、Amazon にキャッシュカード番号を教えるかすれば対応できそうだけど・・・
Linux でも対応してるのだから mac でも対応できるようにしたいな
奥村さんが紹介してくれた国文学研究館の精細な画像だと 「notcopy」になっているようでコピペはできないのですが、
iOS の写真アプリで撮影したものからは結構な認識をして手軽にテキストを取り出せます。
Google レンズは文字を認識時点でかなり認識できない箇所があり、今回は使用を断念なのは変わりないです。
認識度合いがよいので私の出番は今回は不要かな?
mr2hさんへ
とはいえ、春陽堂の初稿で掲載されてなくて岩波文庫のみのものとその巻末の解説を
iPad IPhone のカメラで撮影しテキスト抽出を試みます。
それから髙橋さんのを暫定で総ルビ化するのは割と手早く対応できますので、必要でしたら申しつけてください。
その際、 「公開版幸田露伴『天うつ浪』第一」「 天うつ浪第二改改」を参考にする予定です。
呟き ...
nvidia GPU 搭載マシンを入手するか、Amazon にキャッシュカード番号を教えるかすれば対応できそうだけど・・・
Linux でも対応してるのだから mac でも対応できるようにしたいな
奥村さんが紹介してくれた国文学研究館の精細な画像だと 「notcopy」になっているようでコピペはできないのですが、
iOS の写真アプリで撮影したものからは結構な認識をして手軽にテキストを取り出せます。
Google レンズは文字を認識時点でかなり認識できない箇所があり、今回は使用を断念なのは変わりないです。
高橋さんの*,txtをもとに、試しに「第二」の『其三十五』を、このsectionだけ組版してみました。たしかに地の文がtext化されたことによる省力効果は大きいです。ただrubyが消えましたので、これを挿入する作業は、かなりのものでした。他方で、OCRの読違い修正箇所は可成り少ないようで、これに要した手間はさほど多くはありませんでした。
そこで、和田さんにお願いしてよければ、「第二」の『其三十八』以降の総ルビ化です。『其三十七』までは、『其三十五』と同様に仕上げるつもりです。『第三』については、text k化を高橋さんに、甘え序でにお願いしようかと考えています。
そこで、和田さんにお願いしてよければ、「第二」の『其三十八』以降の総ルビ化です。『其三十七』までは、『其三十五』と同様に仕上げるつもりです。『第三』については、text k化を高橋さんに、甘え序でにお願いしようかと考えています。
総ルビ化作業は、今まで mr2h さんが作業されていた情報が必要です。
先日アップされた第一巻は「其一.tex」から「其四十.tex」はあるのですが、
第二巻のは「天うつ浪第二改改」に含まれている「2-其二十三.tex」のみなので
第二巻の「其一.tex」から今できている「其三十七.tex」までを見せていただけませんか?
そのほか総ルビ化作業を行う上で以下の作業を行います。
- 2文字以上の漢字が、行跨りになっているケースを考慮し、基本的に改行コードを一旦削除します
- これでは一行が長すぎるので、「句読点(含む閉じ鍵かっこ類)」で改行を入れます。
- 今までの第一巻、第二巻の其三十七の ルビ情報から作成した変換テーブルで一気に変換します。
- 余裕があれば 「其XX」単位にファイル化も考えています。
- 以上の作業はスプリプトベースで行いますが、その処理結果のみをお渡しした方が良いですか?
先日アップされた第一巻は「其一.tex」から「其四十.tex」はあるのですが、
第二巻のは「天うつ浪第二改改」に含まれている「2-其二十三.tex」のみなので
第二巻の「其一.tex」から今できている「其三十七.tex」までを見せていただけませんか?
そのほか総ルビ化作業を行う上で以下の作業を行います。
- 2文字以上の漢字が、行跨りになっているケースを考慮し、基本的に改行コードを一旦削除します
- これでは一行が長すぎるので、「句読点(含む閉じ鍵かっこ類)」で改行を入れます。
- 今までの第一巻、第二巻の其三十七の ルビ情報から作成した変換テーブルで一気に変換します。
- 余裕があれば 「其XX」単位にファイル化も考えています。
- 以上の作業はスプリプトベースで行いますが、その処理結果のみをお渡しした方が良いですか?
今できている「其三十七.tex」-----------とありますが、既に出來て居るのは「其三十五.tex」までです。なのでこれをお送りします。
ルビ情報抜き出し作業は終わりました。
おおよそ4300種の漢字文字列があり
ルビベースで数えるとおおよそ 5300種。
同じ漢字に複数の読みがあっても良いのですが、
どうみてもおかしな情報がありましたので、
私の作業が終わるまで、添付したファイルを参考にして
今まで入力したものを検討しておいてください。
おかしな例の一部(前のスレッドで話題になっていたものの残骸?)
1 突立 つゝ|た \ruby{突立}{つゝ|た}
1 突立 つヽ|た \ruby{突立}{つヽ|た}
1 響 どよみ \ruby[g]{響}{どよみ}
3 響 ひび \ruby{響}{ひび}
1 響 ひゝ \ruby{響}{ひゝ}
5 響 ひゞ \ruby{響}{ひゞ}
2 響 ひゞき \ruby{響}{ひゞき}
なお、このように複数の読みがある場合は、
編集時に選べるように縦に並べて出力するよう検討中。
おおよそ4300種の漢字文字列があり
ルビベースで数えるとおおよそ 5300種。
同じ漢字に複数の読みがあっても良いのですが、
どうみてもおかしな情報がありましたので、
私の作業が終わるまで、添付したファイルを参考にして
今まで入力したものを検討しておいてください。
おかしな例の一部(前のスレッドで話題になっていたものの残骸?)
1 突立 つゝ|た \ruby{突立}{つゝ|た}
1 突立 つヽ|た \ruby{突立}{つヽ|た}
1 響 どよみ \ruby[g]{響}{どよみ}
3 響 ひび \ruby{響}{ひび}
1 響 ひゝ \ruby{響}{ひゝ}
5 響 ひゞ \ruby{響}{ひゞ}
2 響 ひゞき \ruby{響}{ひゞき}
なお、このように複数の読みがある場合は、
編集時に選べるように縦に並べて出力するよう検討中。
自分の投稿に、自分で『呟き』です。私は全くの文系人間で、systemの「シ」の字も知らなかつた者です(キーボードを目にするとアレルギー)が、それでも時代の流れで、ワープロを使いたくなり当時流行っていたPC-98で、やっとこ60歳近い身で、ms-dosを始めましたがむずかしかつたですね。とくに マクロ・アセンブラあたりはとてもハードな世界でした。そこで和田さんの今回の『総ルビ化』のところで思い出したのが、『見当外れかもしれませんが』60歳近くで既に腦力(誤字ではありませんぞ)低下ぎみで讀んだので、よくは理解できなかつた次の Termです。「コンパイラ・コンパイラ、構文解析、トークン、……」などなど。もう書名も忘れたし、当然内容理解には程遠い、その程度の「おはなし」なのですが、やはり、見当外れなのでしょうネ。とんだ脱線でしたが、チョッヨつぶやきたかつたもので。失礼!!
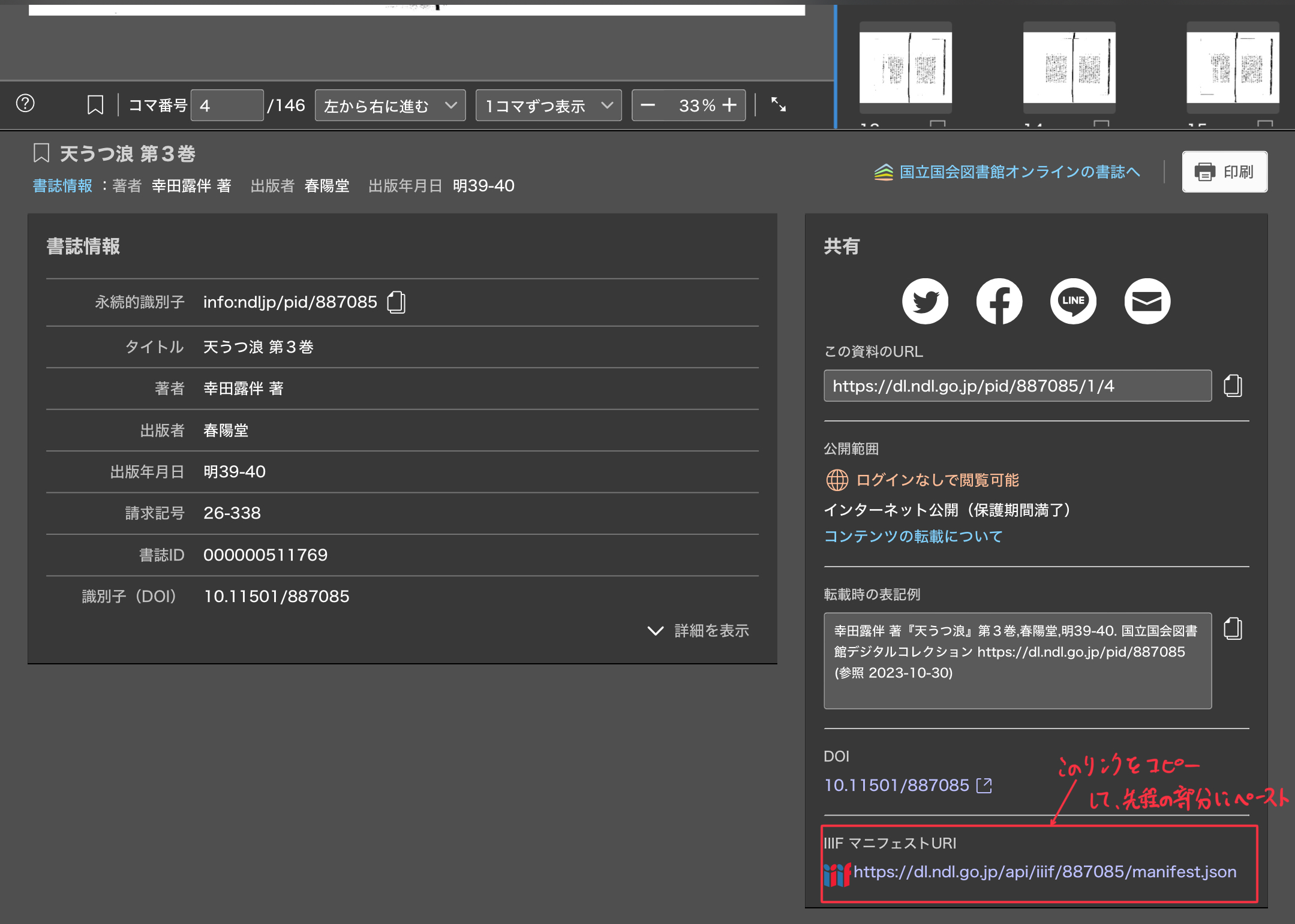
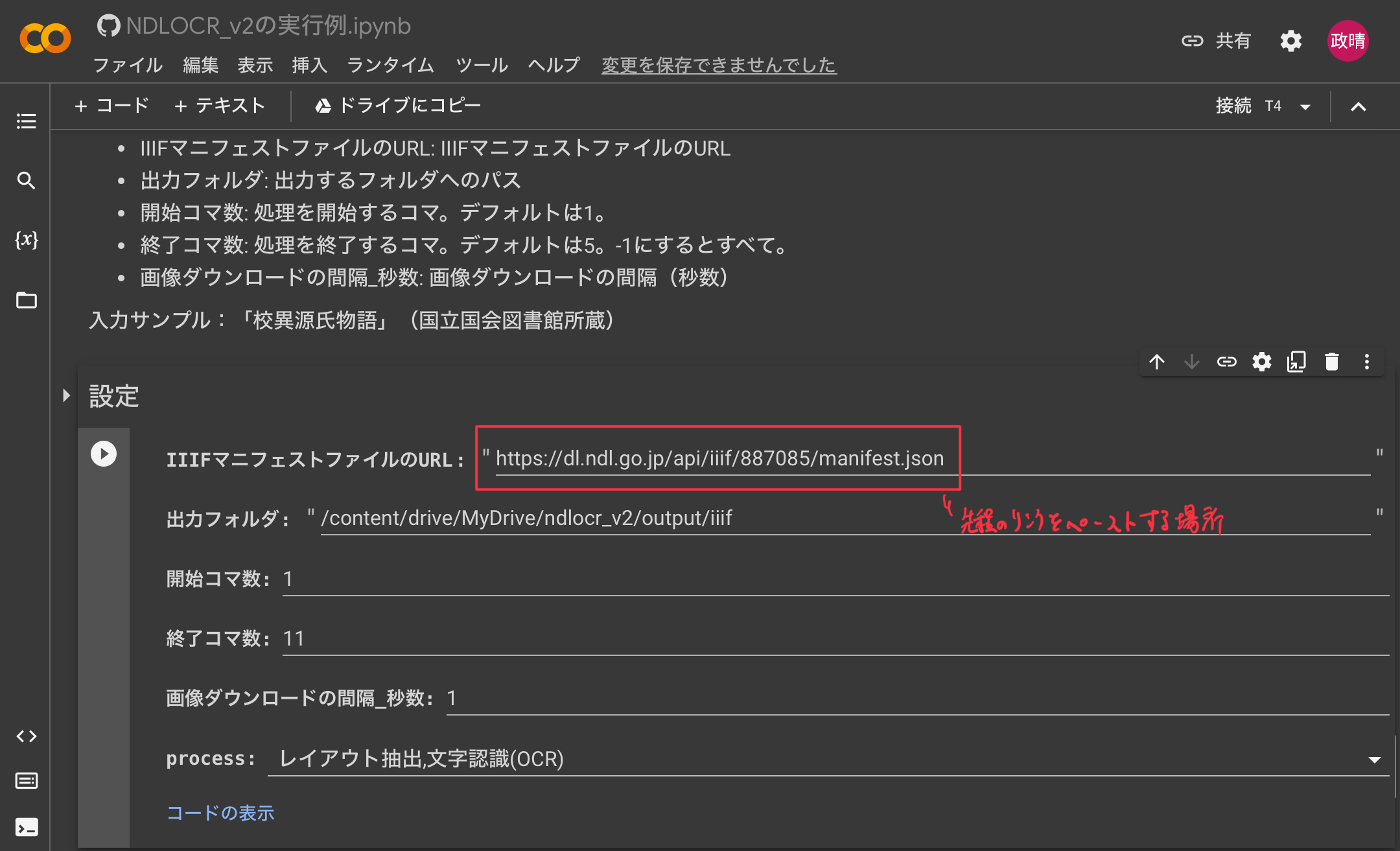
色々データが錯綜しているので、私が総ルビ化作業で参考にする情報をまとめておきます。
1) 髙橋さんの OCR 結果
第2巻(其三十四以降)
- 2023年 10月 29日(日曜日) 23:22 - 髙橋 政晴 の投稿
- https://okumuralab.org/tex/mod/forum/discuss.php?d=3656#p22751
- https://okumuralab.org/tex/pluginfile.php/6/mod_forum/attachment/22751/第2巻%E3%80%80其三十四以降(修正なしOCRテキストデータ).txt?forcedownload=1
第3巻
- 2023年 10月 30日(月曜日) 21:41 - 髙橋 政晴 の投稿
- https://okumuralab.org/tex/mod/forum/discuss.php?d=3656#p22782
- https://okumuralab.org/tex/pluginfile.php/6/mod_forum/attachment/22782/第3巻.txt?forcedownload=1
2) mr2h さんの TeX 化済み == 総ルビ化材料
第1巻
- 2023年 10月 28日(土曜日) 08:53 - mr2h の投稿
- https://okumuralab.org/tex/mod/forum/discuss.php?d=3656#p22735
- https://okumuralab.org/tex/pluginfile.php/6/mod_forum/attachment/22735/公開版幸田露伴『天うつ浪』第一.zip?forcedownload=1
第2巻(其三十五まで)
- 2023年 10月 30日(月曜日) 20:46 - mr2h の投稿
- https://okumuralab.org/tex/mod/forum/discuss.php?d=3656#p22780
- https://okumuralab.org/tex/pluginfile.php/6/mod_forum/attachment/22780/天うつ浪第二.zip?forcedownload=1
3) 参考画像イメージ
国立国会図書館デジタルコレクション ... ある程度検索できるので探しやすい
- 第1巻 https://dl.ndl.go.jp/pid/887083
- 第2巻 https://dl.ndl.go.jp/pid/887084
- 第3巻 https://dl.ndl.go.jp/pid/887085
国文学研究資料館 ... 大きな画面で目視で比較チェックの時便利かな
- 第1巻 https://school.nijl.ac.jp/kindai/CKMR/CKMR-00910#1
- 第2巻 https://school.nijl.ac.jp/kindai/CKMR/CKMR-00911#1
- 第3巻 https://school.nijl.ac.jp/kindai/CKMR/CKMR-00912#1
現役退いているのでプログラミングがなかなか捗らなくてようやっとお渡しできるものができました。
どんなふうにできたかは添付のファイルをみてくだ区こととして..
全体的には、句読点とそれに続く」または』単位に改行を入れていますが ...
第一巻及び第二巻までの途中までで、同じ漢字に複数のルビを振っている場合は
二つ目以降を改行してタブで字下げしていますので、適宜選択等してください。
初めて出てきた漢字には \ruby{丈夫}{??ルビ??} としていますので
適宜加筆してください。
\ruby{叔母}{を|ば}
\ruby{叔母}{お|ば}
はただ\ruby{堅人}{かた|じん}を\ruby{丈夫}{??ルビ??}に
\ruby{有}{あ}
\ruby{有}{\ あ}
\ruby{有}{も}
\ruby{有}{ゐ}
ファイル分割はしてありますが、
OCR で解析?した際にうまく処理できなかったもの等がありました。
たとえば第三巻では以下のようなケースがあり、
コメントのように処理しておきました。
\section*{其十}
\section*{其十一六} ← これは 其十一 だと思いますが 其十一六 に出力
\section*{其十二}
\section*{其十} ←多分 其十三 だと思いますが 其十 に追記しています。
\section*{其十四}
PS
今ひとつデバッグしきれなかったのですが、
ところどころ余分な改行が混入しています。
適宜調整してください。
どんなふうにできたかは添付のファイルをみてくだ区こととして..
全体的には、句読点とそれに続く」または』単位に改行を入れていますが ...
第一巻及び第二巻までの途中までで、同じ漢字に複数のルビを振っている場合は
二つ目以降を改行してタブで字下げしていますので、適宜選択等してください。
初めて出てきた漢字には \ruby{丈夫}{??ルビ??} としていますので
適宜加筆してください。
\ruby{叔母}{を|ば}
\ruby{叔母}{お|ば}
はただ\ruby{堅人}{かた|じん}を\ruby{丈夫}{??ルビ??}に
\ruby{有}{あ}
\ruby{有}{\ あ}
\ruby{有}{も}
\ruby{有}{ゐ}
ファイル分割はしてありますが、
OCR で解析?した際にうまく処理できなかったもの等がありました。
たとえば第三巻では以下のようなケースがあり、
コメントのように処理しておきました。
\section*{其十}
\section*{其十一六} ← これは 其十一 だと思いますが 其十一六 に出力
\section*{其十二}
\section*{其十} ←多分 其十三 だと思いますが 其十 に追記しています。
\section*{其十四}
PS
今ひとつデバッグしきれなかったのですが、
ところどころ余分な改行が混入しています。
適宜調整してください。
現役退いているのでプログラミングがなかなか捗らなくてようやっとお渡しできるものができました。
どんなふうにできたかは添付のファイルをみてくだくこととして..
全体的には、句読点とそれに続く 」または 』単位に改行を入れていますが ...
第一巻及び第二巻までの途中までで、同じ漢字に複数のルビを振っている場合は
二つ目以降を改行してタブで字下げしていますので、適宜選択等してください。
初めて出てきた漢字には \ruby{丈夫}{??ルビ??} としていますので
適宜加筆してください。
\ruby{叔母}{を|ば}
\ruby{叔母}{お|ば}
はただ\ruby{堅人}{かた|じん}を\ruby{丈夫}{??ルビ??}に
\ruby{有}{あ}
\ruby{有}{\ あ}
\ruby{有}{も}
\ruby{有}{ゐ}
ファイル分割はしてありますが、
OCR で解析?した際にうまく処理できなかったもの等がありました。
たとえば第三巻では以下のようなケースがあり、
コメントのように処理しておきました。
\section*{其十}
\section*{其十一六} ← これは 其十一 だと思いますが 其十一六 に出力
\section*{其十二}
\section*{其十} ←多分 其十三 だと思いますが 其十 に追記しています。
\section*{其十四}
PS
今ひとつデバッグしきれなかったのですが、
ところどころ余分な改行が混入しています。
適宜調整してください。
どんなふうにできたかは添付のファイルをみてくだくこととして..
全体的には、句読点とそれに続く 」または 』単位に改行を入れていますが ...
第一巻及び第二巻までの途中までで、同じ漢字に複数のルビを振っている場合は
二つ目以降を改行してタブで字下げしていますので、適宜選択等してください。
初めて出てきた漢字には \ruby{丈夫}{??ルビ??} としていますので
適宜加筆してください。
\ruby{叔母}{を|ば}
\ruby{叔母}{お|ば}
はただ\ruby{堅人}{かた|じん}を\ruby{丈夫}{??ルビ??}に
\ruby{有}{あ}
\ruby{有}{\ あ}
\ruby{有}{も}
\ruby{有}{ゐ}
ファイル分割はしてありますが、
OCR で解析?した際にうまく処理できなかったもの等がありました。
たとえば第三巻では以下のようなケースがあり、
コメントのように処理しておきました。
\section*{其十}
\section*{其十一六} ← これは 其十一 だと思いますが 其十一六 に出力
\section*{其十二}
\section*{其十} ←多分 其十三 だと思いますが 其十 に追記しています。
\section*{其十四}
PS
今ひとつデバッグしきれなかったのですが、
ところどころ余分な改行が混入しています。
適宜調整してください。
失礼しました。
前回は zip コマンドで圧縮しましたが
mac の Fiinder で圧縮し直しました。
ついでなので
nkf --overwrite -Lw で CRLF ファイルに、
第3巻の「其十一六」は「其十一」と「六」の分離するようにしたので
「其十一.tex」に直しておきました。
PS
Windows 環境では試してみてはいませんが
7zip (コマンド名は 7z) だとうまく対応してくれるように見えます。
コンテンツ内容をリスト
7z l アーカイブ名.zip
コンテンツ内容を展開
7z x アーカイブ名.zip
前回は zip コマンドで圧縮しましたが
mac の Fiinder で圧縮し直しました。
ついでなので
nkf --overwrite -Lw で CRLF ファイルに、
第3巻の「其十一六」は「其十一」と「六」の分離するようにしたので
「其十一.tex」に直しておきました。
PS
Windows 環境では試してみてはいませんが
7zip (コマンド名は 7z) だとうまく対応してくれるように見えます。
コンテンツ内容をリスト
7z l アーカイブ名.zip
コンテンツ内容を展開
7z x アーカイブ名.zip
mr2h さんに余力があればですが、
今回ルビ情報が付与されなかった漢字ですが、
添付のファイルに空白を区切りに読みを入れていただければ、
今回の処理に反映させることが可能ですので検討してください。
なお、各行の左端の数値は、出現頻度ですので、
複数の場合はそれを参考に複数の読みになるよう複数行で表してください。
例
2 可能
→ 2 可能 かのう
2 可能 できる
今回ルビ情報が付与されなかった漢字ですが、
添付のファイルに空白を区切りに読みを入れていただければ、
今回の処理に反映させることが可能ですので検討してください。
なお、各行の左端の数値は、出現頻度ですので、
複数の場合はそれを参考に複数の読みになるよう複数行で表してください。
例
2 可能
→ 2 可能 かのう
2 可能 できる
「ルビ情報が付与されなかった漢字」については、私も、この小説を読んで、その箇所に出遭つて「へえ、こういう読み方も明治の頃には、或は幸田露伴の場合には、あるんだ!」という状況なので、和田さんの狙いは理解しますが、お役に立ちそうもありません。私は国文学者ではないものですから。つまり、ある「讀み」について『読み方=ルビ』を「ひとつ」知つていたとしても、「他に」どんな読み方があるのかについては知らないのです。
それから、直前の課題であるfolder, subfolderの「文字化け」により読めない問題ですが、其の爲に、この分割文書が『其**』になるのか分りませんので、TeX文書の冒頭部分を読んだうえで、初稿を探し出す・・・という「情けない」事情により折角の和田さんの労作が活用しにくいのです。
以前おこなっていた圧縮方法で、再度送り直していただけないでしょうか?
それから、直前の課題であるfolder, subfolderの「文字化け」により読めない問題ですが、其の爲に、この分割文書が『其**』になるのか分りませんので、TeX文書の冒頭部分を読んだうえで、初稿を探し出す・・・という「情けない」事情により折角の和田さんの労作が活用しにくいのです。
以前おこなっていた圧縮方法で、再度送り直していただけないでしょうか?
システムコードが 65001 vs 932 の問題かなとおのっていたのですが 7zip のバージョンですか
私は scoop で導入していますので ...
scoop info 7zip
Name : 7zip
Description : A multi-format file archiver with high compression ratios
Version : 22.01 (Update to 23.01 available)
Bucket : main
Website : https://www.7-zip.org
License : LGPL-2.1-or-later
Updated at : 2023/06/27 11:55:54
Updated by : Joost-Wim Boekesteijn
Installed : 22.01
Binaries : 7z.exe | 7zFM.exe | 7zG.exe
Shortcuts : 7-Zip
Notes : Add 7-Zip as a context menu option by running: "\install-context.reg"
私は scoop で導入していますので ...
scoop info 7zip
Name : 7zip
Description : A multi-format file archiver with high compression ratios
Version : 22.01 (Update to 23.01 available)
Bucket : main
Website : https://www.7-zip.org
License : LGPL-2.1-or-later
Updated at : 2023/06/27 11:55:54
Updated by : Joost-Wim Boekesteijn
Installed : 22.01
Binaries : 7z.exe | 7zFM.exe | 7zG.exe
Shortcuts : 7-Zip
Notes : Add 7-Zip as a context menu option by running: "\install-context.reg"
前半部分へのリプライです。
国文学者でなくともできる作業があります。
現在、我々は国立国会図書館、国文学研究資料館、Kindle などなどデジタルメディアを通して作品を目にすることができます。
おそらく mr2h さんは、髙橋さんが OCR でテキスト化しそれを私が総ルビ化の補助情報を組み込んだものを元に、
上記デジタルメディアと見比べ、
OCR での誤認識部分の補正
ルビの補正(選択・修正・加筆)
〓文字部分を初めとする通常のフォントでは表示できない部分の GWI 化
などなどの校正作業をおこなうものだとおもいます。
ということで、ルビ情報はデジタルメディアで容易に得られるのでは
とかんがえていました。
時間的余裕があれば、この作業を代行できるのですが、
岩波文庫のみ掲載文のテキスト化作業が終わってから
対応できればと考えています。
国文学者でなくともできる作業があります。
現在、我々は国立国会図書館、国文学研究資料館、Kindle などなどデジタルメディアを通して作品を目にすることができます。
おそらく mr2h さんは、髙橋さんが OCR でテキスト化しそれを私が総ルビ化の補助情報を組み込んだものを元に、
上記デジタルメディアと見比べ、
OCR での誤認識部分の補正
ルビの補正(選択・修正・加筆)
〓文字部分を初めとする通常のフォントでは表示できない部分の GWI 化
などなどの校正作業をおこなうものだとおもいます。
ということで、ルビ情報はデジタルメディアで容易に得られるのでは
とかんがえていました。
時間的余裕があれば、この作業を代行できるのですが、
岩波文庫のみ掲載文のテキスト化作業が終わってから
対応できればと考えています。
和田さんの『総ルビ対応』は、使つていて、とても使いやすいです。まづ周囲の空白が多いので、見やすく入力間違いがすくなくなります。今までは、原稿を見ていてこの空白がないので、一旦目を離し再び作業するときに、原稿の見間違いで数行抜いたり、逆にダブつたりと、間違いやすかつた。ただ、ルビの選択作業が中心となりますので、入力終つた後に、餘計な全角半角の空白文字を混入させていないか、チェック爲る必要があります。たしかに作業性は飛躍的に向上しているのですが、だからといって入力に要する時間が大幅に短縮されたかといへば、さほどでもない感じがします。それだけ『総ルビ』が手間の掛る作業だからでしょう。明治のころの、出版社が活字で組叛した「苦勞」が偲ばれるというものですね。
私の想定した対応をされているとのこと、少々嬉しいです。
私個人としては、TeX の原稿で一行が異様に長いのはあまり好きではありません。
なので、良く「句点」で改行し、長ければ「読点」で改行を入れるようにしています。
今回はルビ対応部分により長くなりやすいので一律句読点で改行を加えました。
なので「空白」が目立つのだと思います。
diff や git で差分を表示するとき、短いと違いが比較的一目でわかるのではと思います。
さて総ルビ対応で複数選択の場合の私の一番のおすすめは vi エディタですね。
検索パターンを ruby にしておき、「n」で検索し「D」か「dd」で削除できるので。
vscode にはこれに相応するマクロ等があるかもしれませんが。
また、今回 section (其XX)単位に分割しましたが、
もし mr2h さんの活動に賛同される方がいらっしゃれば、git で管理し、
各 section 単位に
- ルビのチェック
- OCR での文字誤認識部分の是正
- mr2h さんにようる校正
みたいなことをやれれば良いかなと思っています。
賛同者がいらっしゃれば git で管理できるよう手配します。
私個人としては、TeX の原稿で一行が異様に長いのはあまり好きではありません。
なので、良く「句点」で改行し、長ければ「読点」で改行を入れるようにしています。
今回はルビ対応部分により長くなりやすいので一律句読点で改行を加えました。
なので「空白」が目立つのだと思います。
diff や git で差分を表示するとき、短いと違いが比較的一目でわかるのではと思います。
さて総ルビ対応で複数選択の場合の私の一番のおすすめは vi エディタですね。
検索パターンを ruby にしておき、「n」で検索し「D」か「dd」で削除できるので。
vscode にはこれに相応するマクロ等があるかもしれませんが。
また、今回 section (其XX)単位に分割しましたが、
もし mr2h さんの活動に賛同される方がいらっしゃれば、git で管理し、
各 section 単位に
- ルビのチェック
- OCR での文字誤認識部分の是正
- mr2h さんにようる校正
みたいなことをやれれば良いかなと思っています。
賛同者がいらっしゃれば git で管理できるよう手配します。
大變遲くなりましたが、皆様の扶けを借りまして、やっとこ『天うつ浪』第二の一応の入力が出來ましたので、ここに、お約束通り公開致します。正直疲れました。皆様のお目に触れることによつて、更に「間違い」の校正が、ご指摘戴くことによつて可能となれば、嬉しいです。この後の「第三」は来年櫻が楽しめる頃までに出來上がれば、いいな、などと考えています。どうか、この『第二』について、ご指摘を賜りたく、よろしくお願い致します。
> ... 更に「間違い」の校正 ...
ちらっと拝見させていただきましたが、
旧字/旧かななどで表記の揺れが散見されますので、
国立国会図書館デジタルコレクションや
国文学研究資料館の資料を
可能な限り校正作業を行えればと思います。
とりあえず、
- 一行が長いので、句読点や \ruby 単位に改行
- 連続する空行の削除
- ファイル名が「一」「七」「三」「九」...「四」
だと作業が面倒なので半角数字を前置して
順番になるよう rename
など修正作業の差分が明瞭になるよう前処理をしてみました。
どなたか一緒にやっても良いという方がいらっしゃれば
git で共同で校正作業ができる環境を構築・提供も検討します。
PS
大きな活字を所望しているのは mr2h さんだけではないようですね。
先日 2023/11/4 か 5 の天声人語に豊島区立中央図書館での出来事で
視覚障害のある男の子が本を一心に見つめニコニコ云々
というのが紹介されていました。
mr2h さんの活動がそんな人たちに役立てられたらなという思いで
校正作業をしていこうと思います。
ちらっと拝見させていただきましたが、
旧字/旧かななどで表記の揺れが散見されますので、
国立国会図書館デジタルコレクションや
国文学研究資料館の資料を
可能な限り校正作業を行えればと思います。
とりあえず、
- 一行が長いので、句読点や \ruby 単位に改行
- 連続する空行の削除
- ファイル名が「一」「七」「三」「九」...「四」
だと作業が面倒なので半角数字を前置して
順番になるよう rename
など修正作業の差分が明瞭になるよう前処理をしてみました。
どなたか一緒にやっても良いという方がいらっしゃれば
git で共同で校正作業ができる環境を構築・提供も検討します。
PS
大きな活字を所望しているのは mr2h さんだけではないようですね。
先日 2023/11/4 か 5 の天声人語に豊島区立中央図書館での出来事で
視覚障害のある男の子が本を一心に見つめニコニコ云々
というのが紹介されていました。
mr2h さんの活動がそんな人たちに役立てられたらなという思いで
校正作業をしていこうと思います。
今回は一巻も 1-xx にするようにしていたので
ファイルリストを作り、手作業で並べ替え、
shell script で行番号情報をもとに nn-1-xx-其xx に
なるように rename 情報を作成して変更しました。
なおついでに 上下巻で通番の岩波文庫版の参照もできるように
さらに三桁の岩波文庫用のも前置しています。
三巻も同様にとご希望なら、perl スクリプトを用意しますが ...
対応は夕方になると思います。
そうそう、pdf 化するとき、一行の長さを春陽堂のと同じになるよう
3文字少なくするとpdf と国会図書館などを参考にする際、利便性が上がると思います。
ファイルリストを作り、手作業で並べ替え、
shell script で行番号情報をもとに nn-1-xx-其xx に
なるように rename 情報を作成して変更しました。
なおついでに 上下巻で通番の岩波文庫版の参照もできるように
さらに三桁の岩波文庫用のも前置しています。
三巻も同様にとご希望なら、perl スクリプトを用意しますが ...
対応は夕方になると思います。
そうそう、pdf 化するとき、一行の長さを春陽堂のと同じになるよう
3文字少なくするとpdf と国会図書館などを参考にする際、利便性が上がると思います。
perl でリネームの情報は作成できたのですが、
Windows でテストでファイル名の文字コードの扱いに難航のため
cmd プロンプト用として添付ファイルのバッチスクリプトを提供することにしました。
「公開版幸田露伴『天うつ浪』第一」「公開版幸田露伴『天うつ浪』第二」
の二つのディレクトリがあるところに添付ファイルを置き
コマンドプロンプト を起動して「 renames.bat 」を実行してください。
第三巻の方は今夜帰宅してから投稿する予定です。
Windows でテストでファイル名の文字コードの扱いに難航のため
cmd プロンプト用として添付ファイルのバッチスクリプトを提供することにしました。
「公開版幸田露伴『天うつ浪』第一」「公開版幸田露伴『天うつ浪』第二」
の二つのディレクトリがあるところに添付ファイルを置き
コマンドプロンプト を起動して「 renames.bat 」を実行してください。
第三巻の方は今夜帰宅してから投稿する予定です。
第三巻用のファイル名の漢数字部分の情報から算用数字を前置するように
ファイル名を変更するコマンドバッチスクリプトです。
第三巻用の保存ディレクトリが不明ですのでこちらでは試していないので、
1) 一旦、第三巻部分を適当なディレクトリにコピーし、 ← ここ重要
2) 添付の rename-3.bat をそのディレクトリに配置し、
3) コマンドプロンプトで rename-3.bat を実行してください。
うまくいったら、元のディレクトリにコピーなどしてください。
ファイル名を変更するコマンドバッチスクリプトです。
第三巻用の保存ディレクトリが不明ですのでこちらでは試していないので、
1) 一旦、第三巻部分を適当なディレクトリにコピーし、 ← ここ重要
2) 添付の rename-3.bat をそのディレクトリに配置し、
3) コマンドプロンプトで rename-3.bat を実行してください。
うまくいったら、元のディレクトリにコピーなどしてください。
和田 勇様 mr2h様
漢字が大好きなので調べてみました。
諸橋轍次 他共著
『新漢和辞典』(改訂版)大修館書店、1982年4月1日には
「そうりょう」は「爽涼」と書かれています。
追伸
脱線させて申し訳御座いませんが
露伴の「風流仏」には、今は使われない「紀念」(かたみ)などが有り
記念の字に慣れている今日では少々戸惑ってしまう用語も御座います。
また「差別」も。わざわざ呉音の古い正しい発音の「しゃべつ」とルビを
添えたりもしている様です。
(尤も、「風流仏」と言うタイトルなので仏教の用語を意識して書かれている?のかも知れませんが)
「諸の仏菩薩は他心智を以って十方の無量無数の有情の心の差別を智る。」などの経典を意識か?
漢字が大好きなので調べてみました。
諸橋轍次 他共著
『新漢和辞典』(改訂版)大修館書店、1982年4月1日には
「そうりょう」は「爽涼」と書かれています。
追伸
脱線させて申し訳御座いませんが
露伴の「風流仏」には、今は使われない「紀念」(かたみ)などが有り
記念の字に慣れている今日では少々戸惑ってしまう用語も御座います。
また「差別」も。わざわざ呉音の古い正しい発音の「しゃべつ」とルビを
添えたりもしている様です。
(尤も、「風流仏」と言うタイトルなので仏教の用語を意識して書かれている?のかも知れませんが)
「諸の仏菩薩は他心智を以って十方の無量無数の有情の心の差別を智る。」などの経典を意識か?
難しい問題ですね。因みに「にすい」と「さんずい」の凉の違いは?とググってみましたら、
==========================================================
以前の漢字文化資料館で掲載していた記事です。2008 年以前の古い記事のため、ご留意ください。
Q0169
「凉」と「涼」は、同じ漢字でしょうか? それとも、別の漢字でしょうか?
A
この2つの漢字について漢和辞典を調べてみると、両者は異体字の関係にある、ということで諸書一致しています。つまり、読みも意味も同じである、ということです。一般によくつかわれるのは「さんずい」の方の「涼」ですから、「にすい」の「凉」はその俗字にあたる、という言い方もよくされます。
「さんずい」と「にすい」は、形もよく似ているので、よく混同されます。しかし、意味の上から厳密に考えると、もともとは違う意味のことが多いのです。たとえば「清」という漢字の「にすい」バージョンもありますが、そちらは「すずしい」とか「つめたい」とかいう意味で、「きよらか」とはちょっと違います。また、「冷」という漢字の「さんずい」バージョンもあるのですが、これは「澄む」という意味で、「つめたい」とはだいぶ違います。これらから推測すると「凉」と「涼」の間にも意味の違いがありそうなものですが、これは両者とも「すずしい」という意味で、全く同じと考えてよい、珍しい例だといえそうです。
しかし、だからといって「凉」と「涼」が「同じ漢字」なのかというと、問題は少しむずかしくなります。つまり「同じ漢字」とは何なのか、という問題があるのです。見かけが少しでも違えば「別の漢字」だ、という立場に厳密に立つと、手書きで漢字を書く場合、なぞらない限り完璧に同じ形の字を書くことは非常に困難ですから、「別の漢字」だらけになってしまいます。そこで、見かけがどこまで違うと「別の漢字」だと認定するのか、という線引きの必要が出てきます。このあたり、考え始めるとドツボにはまってしまう、頭のイタ~イ問題です。
ドツボは回避するとして、「凉」と「涼」の場合に限って考えてみると、これらは「にすい」と「さんずい」という、明らかに違う要素を含んでいますから、「読みも意味も同じだけれど別の漢字」としておくのがよいのではないかと思います。
=========================================================
と、ありました、
今回はこの問題には触れずに、『初稿版』に随いたいと思います。
==========================================================
以前の漢字文化資料館で掲載していた記事です。2008 年以前の古い記事のため、ご留意ください。
Q0169
「凉」と「涼」は、同じ漢字でしょうか? それとも、別の漢字でしょうか?
A
この2つの漢字について漢和辞典を調べてみると、両者は異体字の関係にある、ということで諸書一致しています。つまり、読みも意味も同じである、ということです。一般によくつかわれるのは「さんずい」の方の「涼」ですから、「にすい」の「凉」はその俗字にあたる、という言い方もよくされます。
「さんずい」と「にすい」は、形もよく似ているので、よく混同されます。しかし、意味の上から厳密に考えると、もともとは違う意味のことが多いのです。たとえば「清」という漢字の「にすい」バージョンもありますが、そちらは「すずしい」とか「つめたい」とかいう意味で、「きよらか」とはちょっと違います。また、「冷」という漢字の「さんずい」バージョンもあるのですが、これは「澄む」という意味で、「つめたい」とはだいぶ違います。これらから推測すると「凉」と「涼」の間にも意味の違いがありそうなものですが、これは両者とも「すずしい」という意味で、全く同じと考えてよい、珍しい例だといえそうです。
しかし、だからといって「凉」と「涼」が「同じ漢字」なのかというと、問題は少しむずかしくなります。つまり「同じ漢字」とは何なのか、という問題があるのです。見かけが少しでも違えば「別の漢字」だ、という立場に厳密に立つと、手書きで漢字を書く場合、なぞらない限り完璧に同じ形の字を書くことは非常に困難ですから、「別の漢字」だらけになってしまいます。そこで、見かけがどこまで違うと「別の漢字」だと認定するのか、という線引きの必要が出てきます。このあたり、考え始めるとドツボにはまってしまう、頭のイタ~イ問題です。
ドツボは回避するとして、「凉」と「涼」の場合に限って考えてみると、これらは「にすい」と「さんずい」という、明らかに違う要素を含んでいますから、「読みも意味も同じだけれど別の漢字」としておくのがよいのではないかと思います。
=========================================================
と、ありました、
今回はこの問題には触れずに、『初稿版』に随いたいと思います。
本日、やつと『天うつ浪』春陽堂版(初版本)の入力が一応終わりましたので、纏めてご報告いたします。ご協力眞に有り難うございました。ただ、内容てきには、未完の小説であり其の意味で物足りなさはありますが、致し方ありません。岩波版では、この後若干の補充があるようなので、今しばらく作業は続きそうです。でも和田さんが校正およびこの部分はやっていただけるようなので、しばらくは様子見です。美文書第9版本日入手しました。奥村先生ありがとうございます。
まずは、入力作業ご苦労様でした。
来年3月頃、入力終了予定とのことと思っていたので、
実際のところ
- github へ登録
- git で扱い易くするため CR/LF や長い一行を \ruby 毎に改行を入れるなどの作業をしています
- intel mac ではコンパイルできなかった件は M1 mac なら OK なのを発見
- mr2h さんのレイアウトだと3文字長いので、国会図書館などの PDF と見比べる際、
首を縦にフリフリしなければいけないので 作業効率改善のため
- 13pt に変更したり、
- ルビの振り方を初版本に合わせる
- ...
などの調整・検討していました。
(なお、ルビの振り方は後ほど DM などでご相談させていただくつもりです)
などをの事前準備はできたのですが、
仕事の都合などでなかなか作業時間が取れず、
ご報告できるような状態には程遠いのが現状です。申し訳ないです。
仕事の区切りがつく年末から本格的に作業を開始できると思いますので、
できれば2月くらいに完了する目標で作業できればと思います。
それから、全部揃ったとのことですが、
巻毎にすると「第一」「第三」「第二」の順になったり、
「(2)」のようにファイルパスに半角の括弧があると、操作が面倒なので処理しやすいよう変更する予定です。
来年3月頃、入力終了予定とのことと思っていたので、
実際のところ
- github へ登録
- git で扱い易くするため CR/LF や長い一行を \ruby 毎に改行を入れるなどの作業をしています
- intel mac ではコンパイルできなかった件は M1 mac なら OK なのを発見
- mr2h さんのレイアウトだと3文字長いので、国会図書館などの PDF と見比べる際、
首を縦にフリフリしなければいけないので 作業効率改善のため
- 13pt に変更したり、
- ルビの振り方を初版本に合わせる
- ...
などの調整・検討していました。
(なお、ルビの振り方は後ほど DM などでご相談させていただくつもりです)
などをの事前準備はできたのですが、
仕事の都合などでなかなか作業時間が取れず、
ご報告できるような状態には程遠いのが現状です。申し訳ないです。
仕事の区切りがつく年末から本格的に作業を開始できると思いますので、
できれば2月くらいに完了する目標で作業できればと思います。
それから、全部揃ったとのことですが、
巻毎にすると「第一」「第三」「第二」の順になったり、
「(2)」のようにファイルパスに半角の括弧があると、操作が面倒なので処理しやすいよう変更する予定です。
▪️3文字短くした場合の文字間隔について
広いかどうかより、13pt にすることで、
国会図書館などの PDF と見比べた時、
ほぼほぼ「行」単位で比較作業ができることを重視しました。
mr2h さんのルビの設定は、
熟語ルビ、(用語は正しくないけど)前突出・後突出有りを原則にして、
適宜グループルビや文字毎に振っていますが、
出来るだけ、熟語ルビやグループルビをやめ、
後突出有りで文字毎にモノルビ化、
3文字医女の場合次の文字のルビの先頭に全角空白を補ってルビが重ならないように調整するなどして
ほぼほぼ初版本と同じ行送りになりました。
熟語の途中で改行が入ったり、各文字に3文字以上のルビがある場合は、時々ずれますが、
段落毎でリセットされるので許容範囲としています。
最初のページを抜き出したものを添付しますので参考にしてください。
(漢数字の総ルビ化作業が漏れてはいますが ...)
添付 pdf には例はありませんが、
会話部分などの開き鉤括弧(『)が突き出てい流のも許容範囲としています。
広いかどうかより、13pt にすることで、
国会図書館などの PDF と見比べた時、
ほぼほぼ「行」単位で比較作業ができることを重視しました。
mr2h さんのルビの設定は、
熟語ルビ、(用語は正しくないけど)前突出・後突出有りを原則にして、
適宜グループルビや文字毎に振っていますが、
出来るだけ、熟語ルビやグループルビをやめ、
後突出有りで文字毎にモノルビ化、
3文字医女の場合次の文字のルビの先頭に全角空白を補ってルビが重ならないように調整するなどして
ほぼほぼ初版本と同じ行送りになりました。
熟語の途中で改行が入ったり、各文字に3文字以上のルビがある場合は、時々ずれますが、
段落毎でリセットされるので許容範囲としています。
最初のページを抜き出したものを添付しますので参考にしてください。
(漢数字の総ルビ化作業が漏れてはいますが ...)
添付 pdf には例はありませんが、
会話部分などの開き鉤括弧(『)が突き出てい流のも許容範囲としています。
『天うつ浪』第三の「其一」に、脱落がありましたので訂正を致します。
添付フアイルに入れ替えをおねがいいたします。まだまだ「要訂正」がみつかるかも、です。
添付フアイルに入れ替えをおねがいいたします。まだまだ「要訂正」がみつかるかも、です。
ソースが部分的に散財するのはあまり良くないので
個人で作業している github に登録しました。
以前からコッソリ登録していましたが、今回、初心に戻って登録し直しています。
https://github.com/128Mac/SORA-UTSU-NAMI
登録にあたっては、
- git などの作業で修正内容が簡略表示できるよう \ruby などを基準に改行を加えています
- 無意味な「空白、空行」を削除
- CR/LF の調整
などの調整作業を行なっています。
とりあえず、リフレッシュしたので、第一巻冒頭ページの修正は未対応に戻しました、
どんな修正を行うかの例として「1st-calibration」というブランチで「水」の旧読みがな対応例を登録してあります。
なお時々、一括変更が望ましい場合は ruby か perl などで一括変更するのでその時の変更パターンもコミットログに登録しています。
今後、ビルドするための環境構築などの情報を READAME に付記しますので、
ご興味のある方は、時々覗いてみてください。
mr2h さんへ
変更が発生した場合は、DM やメールで連絡していただければ、
こちらで登録しますのでよろしくお願いします。
個人で作業している github に登録しました。
以前からコッソリ登録していましたが、今回、初心に戻って登録し直しています。
https://github.com/128Mac/SORA-UTSU-NAMI
登録にあたっては、
- git などの作業で修正内容が簡略表示できるよう \ruby などを基準に改行を加えています
- 無意味な「空白、空行」を削除
- CR/LF の調整
などの調整作業を行なっています。
とりあえず、リフレッシュしたので、第一巻冒頭ページの修正は未対応に戻しました、
どんな修正を行うかの例として「1st-calibration」というブランチで「水」の旧読みがな対応例を登録してあります。
なお時々、一括変更が望ましい場合は ruby か perl などで一括変更するのでその時の変更パターンもコミットログに登録しています。
今後、ビルドするための環境構築などの情報を READAME に付記しますので、
ご興味のある方は、時々覗いてみてください。
mr2h さんへ
変更が発生した場合は、DM やメールで連絡していただければ、
こちらで登録しますのでよろしくお願いします。