Piranesi It BT フォント(piranesi_it_bt.ttf)を入手したので、TeX に導入するべく、以下の手順を実行しました。
1. ttf2tfm piranesi_it_bt.ttf を実行し piranesi_it_bt.tfm を作成
2. 1. で作った piranesi_it_bt.tfm を C:\w32tex\share\texmf\fonts\tfm\ptex に配置
3. piranesi_it_bt.ttf を Windows のフォントフォルダにコピー(この時点でフォント名は "Piranesi It BT" と表示されていた)
4. C:\dviout\map\ttfonts.map に次の 1 行を追加
piranesi_it_bt "Piranesi It BT"
5. dviout の [Option] -> [Setup Parameters...] で Font2 タブの ftt: 欄に
^x\map\ttfonts.map
と入力
ここまで実行した後、fonttest.tex を以下の内容で作成しました。
\documentclass[a4j,12pt]{jarticle}
\title{フォントテスト}
\author{}
\date{\today}
\font\pirit = piranesi_it_bt
\begin{document}
\maketitle
\pirit{UV}
\end{document}
これをコンパイルしてプレビューすると U の文字と V の文字が重なって出力されてしまいました。この現象を解消するにはどうしたらよいでしょうか ?
恐らくこの手順が不適切です。
ttf2tfm piranesi_it_bt.ttf
何もエンコーディングを指定せずに ttf2tfm を呼んでいるという奇妙なコマンドラインですが、実際にこれを実行すると、ttf2tfm はデタラメなエンコーディングの(役に立たない)TFM ファイルを生成してしまうようです。
じゃあどういうエンコーディングにすればよいのかというと、dviout の欧文フォントのマップでは明示的に指定されないので、割と難しいと思います。(私もよく解っていない。)実際に試す限りでは
piranesi_it_bt "Piranesi It BT"
という指定の場合、少なくとも 21h--FFh のエンコーディングは Latin-1 (本当は Windows-1252)になるようです。従って、Latin-1 のエンコーディングで TFM を生成すると、結果的にうまくいくと思われます。具体的には、Unicode のサブフォントを生成すると番号「00」が Latin-1 になることを利用します。
ttf2tfm piranesi_it_bt.ttf output@Unicode@
これで出力される複数の TFM ファイルのうち output00.tfm を piranesi_it_bt.tfm に改名して今ある piranesi_it_bt.tfm を置き換えると恐らくうまくいくと思います。もちろん、非標準のエンコーディングを使うのでその際の注意が必要になりますが。
横から失礼します。
dviout で使おうとされてらっしゃるようですのに、私は dviout については全然分からないので、余計な口出しです…。
> > 非標準のエンコーディングを使うのでその際の注意が必要
>
> というのは具体的にはどういうことでしょう ?
「正解」は Z.R. さんのお返事待ちですが、推測しますに、Z.R. さんが示してくださった方法で作った tfm のエンコーディングは Unicode ですので、TeX で標準の OT1 や T1 では使えないということだと思います。英語で使う限りでしたら多分大丈夫ですが、diacritical mark 付きのグリフを指定するには、工夫が必要になるのではないかと。
なお、dviout で使えるのかどうかは試していませんが、dvipdfmx や pdflatex で使うのであれば、ttf2tfm で -v や -T オプションで OT1 や T1 の tfm を作れるのではないかと思います。
適当に検索して見つかった、
7587.ttf
Piranesi It BT
Version 2.001 mfgpctt 4.4
Copyright 1990--2001 Biestream Inc. All rights reserved.
Piranesi It BT contains 261 glyphs and no standard kern pairs.
This font does not include embedded bitmaps.
というフォントを使って私の手許で試したところでは、なぜか dvipdfmx では fi と fl のリガチャがトーフになってしまいました(別のフォントで試したときは、逆に pdflatex のときに fi と fl がダメだったので、その辺の理由は分かりません)。
T1 の tfm を作ってみた場合のグリフの一覧を添付します(“Preview & Print embedding allowed”となっていましたので、印刷のみ許可にしてあります)。
なお、サブフォントを使うような例ではない、ttf2tfm のごく簡単な使用例をまとめたペーパーを、
http://www.geocities.co.jp/texuttex/font_elementary.html
に置きました(ttf2tfm はペーパーの「8 実例に即して」の部分)。ほとんど Z.R. さんのブログへのポインタの意味しか持たないページかも知れませんが…。
dviout で使おうとされてらっしゃるようですのに、私は dviout については全然分からないので、余計な口出しです…。
> > 非標準のエンコーディングを使うのでその際の注意が必要
>
> というのは具体的にはどういうことでしょう ?
「正解」は Z.R. さんのお返事待ちですが、推測しますに、Z.R. さんが示してくださった方法で作った tfm のエンコーディングは Unicode ですので、TeX で標準の OT1 や T1 では使えないということだと思います。英語で使う限りでしたら多分大丈夫ですが、diacritical mark 付きのグリフを指定するには、工夫が必要になるのではないかと。
なお、dviout で使えるのかどうかは試していませんが、dvipdfmx や pdflatex で使うのであれば、ttf2tfm で -v や -T オプションで OT1 や T1 の tfm を作れるのではないかと思います。
適当に検索して見つかった、
7587.ttf
Piranesi It BT
Version 2.001 mfgpctt 4.4
Copyright 1990--2001 Biestream Inc. All rights reserved.
Piranesi It BT contains 261 glyphs and no standard kern pairs.
This font does not include embedded bitmaps.
というフォントを使って私の手許で試したところでは、なぜか dvipdfmx では fi と fl のリガチャがトーフになってしまいました(別のフォントで試したときは、逆に pdflatex のときに fi と fl がダメだったので、その辺の理由は分かりません)。
T1 の tfm を作ってみた場合のグリフの一覧を添付します(“Preview & Print embedding allowed”となっていましたので、印刷のみ許可にしてあります)。
なお、サブフォントを使うような例ではない、ttf2tfm のごく簡単な使用例をまとめたペーパーを、
http://www.geocities.co.jp/texuttex/font_elementary.html
に置きました(ttf2tfm はペーパーの「8 実例に即して」の部分)。ほとんど Z.R. さんのブログへのポインタの意味しか持たないページかも知れませんが…。
>なお、dviout で使えるのかどうかは試していませんが
ヘルプを見た限り、dviout は .enc ファイルはサポートしないというのはほぼ確実なのですが、その他色々調べたところ、どうやら dviout では欧文 TFM について「普通の」エンコーディングを直接指定する方法はないように思えます。
だから、元の回答では、「piranesi_it_bt "Piranesi It BT"」という設定を前提とし、それに TFM を(なるべく)合わせることにしました。でもこの方法には、非標準エンコーディングを使うという点の他に大きな欠点があります。dviout のユーザの多くは dvipdfmx を併用していると思うのですが、この方法は dviout 特有だから PDF 生成まで適用させることができません。
とすると、dviout で「普通の」エンコーディングを用いる標準的な解法は「ttf2pk に対してマップ設定を行い、後は dviout からの mktexpk の自動起動に任せる」ということになりそうです。手順を簡単に述べると:
- dvipdfmx で OpenType する件について (本編) の手順に従って、dvipdfmx 用の設定をする。例えば TFM 名を piranesi-ri-t1.tfm とすると dvipdfmx のマップ行は次のようになるはず。
piranesi-ri-t1--base a_xxxxxx piranesi_it_bt.ttf - ttf2pk 用のマップファイルに $TEXMF/fonts/map/ttf2pk/ttfonts.map に以下の記述を加える。(これは updmap の管轄外だから直接編集してよい。)
piranesi-ri-t1--base piranesi_it_bt.ttf Encoding=a_xxxxxx.enc
(ちなみに、ttf2pk 用の設定は eggtoothcroc さんの資料で既に解説されています。)
……というのが常識的な答えですが、実は「普通のエンコーディングを SFD ファイルで実現する」という「裏技」を使うと、dviout 直接描画と dvipdfmx の両方に対応できたりします。(「SFD 編-7」を参照。)まあ、ttf2pk 経由だから手間が増えるというわけでもないので、直接描画自体はあまり大きな利点ではないのですが。SFD を使う本当のメリットは、フォントによって異なる「グリフ名」を回避できることだと思っています。
Z. R. さん、おはようございます。丁寧なご説明をありがとうございます!
> dviout で「普通の」エンコーディングを用いる標準的な解法は「ttf2pk に対してマップ設定を行い、後は dviout からの mktexpk の自動起動に任せる」ということになりそうです。
正直、はじめから dviout を使うことは全然考えてなかったので、「常識的な答え」まで頭が廻りませんでした…。
> 「普通のエンコーディングを SFD ファイルで実現する」という「裏技」を使うと、dviout 直接描画と dvipdfmx の両方に対応できたりします。
> SFD を使う本当のメリットは、フォントによって異なる「グリフ名」を回避できることだと思っています。
なんか、Z. R. さんの記事を Z. R. さんご自身にひとことでまとめていただいたみたいな形になってしまい、申し訳ありません…。
基本的に ut さんの言うとおりで、「TeX で標準の OT1 や T1 では使えないということだと思います。英語で使う限りでしたら多分大丈夫ですが、diacritical mark 付きのグリフを指定するには、工夫が必要になる」ということです。
具体的にいうと、\ae とか \"u とか --- とか `` が期待通りになると思ってはいけない、ということです。一応、Latin-1 にある文字だったら、例えば 〈æ〉(U+00E6) ならば \symbol{"E6} のように符号値で入力できます。しかし、〈—〉(em dash; U+2014) や 〈“〉(left double quote; U+201C) は無理です。(これらの文字は CP1252 にはあるので、TFM をちゃんと CP1252 用に作れば dviout で使えるはずなんですが、今は手抜きをしたので。)
「普通のエンコーディング(OT1 や T1)」を使いたい場合は、dviout での直接のレンダリングを諦めて、ttf2pk でビットマップにしてそれを使うという方式を採る必要があります。(ut さんへの返信を参照。)
(解っている人向けの補足です。\ae とかが正常に動作するためには、LaTeX の(MFSS の)現在エンコーディングが正しい(TeX 上の現在フォントと整合する)必要があります。従って、\font プリミティブ(や \newfont 命令)を使う場合はこれらの文字入力命令は使えないと考えるのが合理的です。)
元質問者の方、もう見てらっしゃいませんか…?
私はそもそも dviout で使おうとは考えてなかったので、ちゃんとヘルプとかも見なかったのですけれど、dviout のヘルプ(“-ftt”という項目)と ttfonts.map 冒頭のコメントに、やり方が書いてありましたよ。どうも、dviout は、vf を使えば、8r と 8t の変換については、特に 8r.enc で実フォントを並べ直さなくても、変換してくれるみたいです。また、map ファイルで unicode の指定なんかも出来るみたいです。
それで、具体的には、まず、ttf2tfm と vptovf で、
ttf2tfm 7587.ttf -p 8r.enc -t cork.enc -v piranesi8t.vpl piranesi8r.tfm
vptovf piranesi8t
を実行して、piranesi8r.tfm、piranesi8t.vf, piranesi8t.tfm を作ります(私の手許にあるのはたまたま 7587.ttf ですが、お手許の正しいファイル名にしてください)。この 3 ファイルを、dviout から見える場所に置きます(最初、カレントフォルダに置いておいたらうまくいきませんでした)。
そして、ttfonts.map か $user.map に、
piranesi8r "Piranesi It BT"
と書いて、原稿では piranesi8t のほうをロードします。あとは、原稿ファイルでも \usepackage[T1]{fontenc} とすれば、「\ae とか \"u とか --- とか `` 」も、期待通りに出力されます(--- とか `` というリガチャがうまくいくのは vf のおかげですが)。
unicode の指定をする場合の map の書き方がいまいちよく分からないのですが、(一応ヘルプを見ながら)適当に、
output00 "Piranesi It BT/[1252]" default
と書いてみましたら、これはこれでうまくいきました(output00.tfm は、Z. R. さんが最初に教えてくださった方法で作った tfm ファイルです)。
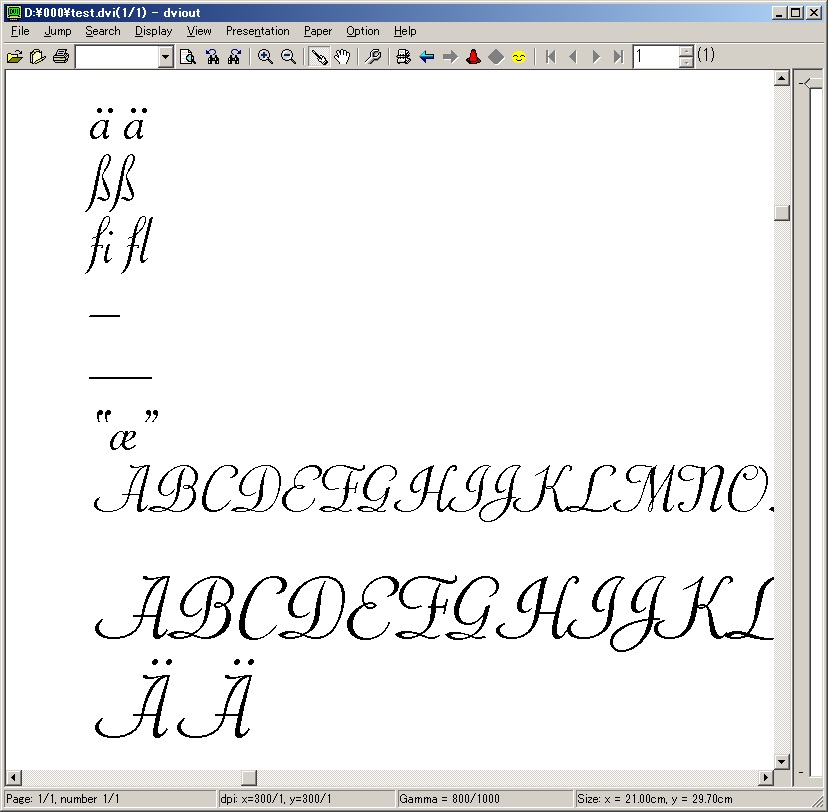
以下の原稿をタイプセットしたものを dviout で表示した画像を添付します。
% ----------
\documentclass{jarticle}
\usepackage[T1]{fontenc}
\begin{document}
\font\piranesi=piranesi8t at 15pt
\piranesi
\"a \char228
\ss \char255
fi fl
--
---
``\ae''
ABCDEFGHIJKLMNOPQRSTUVWXYZ
\bigskip
\font\piranesii=output00 at 20pt
\piranesii
ABCDEFGHIJKLMNOPQRSTUVWXYZ
\"A\char196
\end{document}
% ----------
私はそもそも dviout で使おうとは考えてなかったので、ちゃんとヘルプとかも見なかったのですけれど、dviout のヘルプ(“-ftt”という項目)と ttfonts.map 冒頭のコメントに、やり方が書いてありましたよ。どうも、dviout は、vf を使えば、8r と 8t の変換については、特に 8r.enc で実フォントを並べ直さなくても、変換してくれるみたいです。また、map ファイルで unicode の指定なんかも出来るみたいです。
それで、具体的には、まず、ttf2tfm と vptovf で、
ttf2tfm 7587.ttf -p 8r.enc -t cork.enc -v piranesi8t.vpl piranesi8r.tfm
vptovf piranesi8t
を実行して、piranesi8r.tfm、piranesi8t.vf, piranesi8t.tfm を作ります(私の手許にあるのはたまたま 7587.ttf ですが、お手許の正しいファイル名にしてください)。この 3 ファイルを、dviout から見える場所に置きます(最初、カレントフォルダに置いておいたらうまくいきませんでした)。
そして、ttfonts.map か $user.map に、
piranesi8r "Piranesi It BT"
と書いて、原稿では piranesi8t のほうをロードします。あとは、原稿ファイルでも \usepackage[T1]{fontenc} とすれば、「\ae とか \"u とか --- とか `` 」も、期待通りに出力されます(--- とか `` というリガチャがうまくいくのは vf のおかげですが)。
unicode の指定をする場合の map の書き方がいまいちよく分からないのですが、(一応ヘルプを見ながら)適当に、
output00 "Piranesi It BT/[1252]" default
と書いてみましたら、これはこれでうまくいきました(output00.tfm は、Z. R. さんが最初に教えてくださった方法で作った tfm ファイルです)。
以下の原稿をタイプセットしたものを dviout で表示した画像を添付します。
% ----------
\documentclass{jarticle}
\usepackage[T1]{fontenc}
\begin{document}
\font\piranesi=piranesi8t at 15pt
\piranesi
\"a \char228
\ss \char255
fi fl
--
---
``\ae''
ABCDEFGHIJKLMNOPQRSTUVWXYZ
\bigskip
\font\piranesii=output00 at 20pt
\piranesii
ABCDEFGHIJKLMNOPQRSTUVWXYZ
\"A\char196
\end{document}
% ----------
本当にしつこくてすいません。自分への突っ込みです。
「--- とか `` というリガチャがうまくいくのは vf のおかげ」というのは、不正確で、(リガチャの設定が書かれた)enc ファイルを使って(vf とペアの)tfm を作っているから、というべきでした。
\usepackage[T1]{fontenc} とした状態で unicode の tfm ファイルのテストをしているのもおかしいですよね…。unicode でも T1 でも 196 番は Adieresis ですし。
あと、「output00.tfm には、U+0020 から U+00ff までしか含まれていないので、unicode の tfm を使うメリットはあまりないのでは」というのも言葉不足で、unicode の最初の 256 スロットには、グリフではないスロットもあるので、それなら T1 とかのほうがいいんじゃないかな、というつもりだったのですが、でも、英独仏語くらいであれば、U+0020 から U+00ff まででも十分なのかも知れません。
これから明後日の朝までネット使えないので、このままでは今晩眠れなくなりそうで、書き込みさせていただきました。申し訳ありません。
>ttfonts.map 冒頭のコメントに、やり方が書いてありましたよ
おおー、本当だ! こんなところに解説があるとは盲点だった…。
「dviout は普通の(Unicode の; つまり BaKoMa フォントのような TeX 専用の特別なエンコーディングをもつものでない)欧文フォントをどのようにして用いることを想定しているのか」についてずっと疑問に思っていました。ヘルプには「普通の欧文フォント」のマップ例が載っているので「非対応」扱いではないことは判る、でも CP1252 のままでは LaTeX で「普通に」扱えない、そしてその間を埋める方法は幾つか考え出せるがどれも一般的でない、だから一体 dviout 開発側がどんな方法を想定しているのか解らない、という疑問です。
ttfonts.map のコメントにおいて、この「想定している方法」が明確に示されています。ut さんが元の投稿で既に述べていますが、念のためもう一度書いておきます。
CP1252 を近似的に TeXBase1 エンコーディング(8r エンコーディング)と見做し、Type1 フォントで一般的に用いられている「8r のフォントを参照する VF の形で OT1/T1/TS1 のエンコーディングを構成する」という方法を適用する
dviout が中で用いているエンコーディングが CP1252 であることは実際に適当なフォントでコード表を表示させて確かめたのですが、これを TeXBase1 であると見做せるということは気付かなかった。TeXBase1 のコード表も何回も見ているのですが、それが CP1252 互換であるということも初めて知りました。
貴重な情報を教えて頂いてありがとうございます!
【参考】添付の画像について
- 上は dviout で「
piranesi_it_bt "Piranesi It BT"」のような「最も単純なマップ指定」を行った場合に実際に用いられるエンコーディング。基本的に CP1252(Windows-1252、WinAnsi)であるが、0x20 以下は所謂「remap」への対応のために 0x80 以上の文字を重複させている。 - 下は TeXBase1 エンコーディング。これの用途については、ut さんの資料を参照してほしい。Berry 規則での識別子が「8r」なので「8r エンコーディング」とも呼ばれる。
なお、この画像は dvipdfmx で生成した PDF から変換したもの。これを作るときに用いた SFD を載せておく。
l1a 0xA1_0xAA 0xAD_0xC3 0x21_0x7E 0xC4 128: 0x20AC 130: 0x201A \
0x0192 0x201E 0x2026 0x2020 0x2021 0x02C6 0x2030 0x0160 0x2039 \
0x0152 142: 0x017D 145: 0x2018 0x2019 0x201C 0x201D 0x2022 \
0x2013 0x2014 0x02DC 0x2122 0x0161 0x203A 0x0153 158: 0x017E \
0x0178 161: 0xA1_0xFF
8r 1: 0x02D9 0xFB01 0xFB02 0x2044 0x02DD 0x0141 0x0142 0x02DB \
0x02DA 11: 0x02D8 0x2212 14: 0x017D 0x017E 0x02C7 0x0131 0x0237 \
0xFB00 0xFB03 0xFB04 0x2260 0x221E 0x2264 0x2265 0x2202 \
0x2211 0x220F 0x03C0 0x60 0x27 0x20_0x26 0x2019 0x28_0x5F \
0x2018 0x61_0x7E 128: 0x20AC 0x222B 0x201A 0x0192 0x201E 0x2026 \
0x2020 0x2021 0x02C6 0x2030 0x0160 0x2039 0x0152 0x2126 0x221A \
0x2248 147: 0x201C 0x201D 0x2022 0x2013 0x2014 0x02DC 0x2122 \
0x0161 0x203A 0x0153 0x2206 0x25CA 0x0178 161: 0xA1_0xFF

ちなみに、CP1252 を強引に TeXBase1 だと思うことの齟齬は、実際に「TeXBase1 の 0x20 以下にある文字」(CP1252 + remap と食い違うもの)を使ってみると露呈します。
〔TFM 生成〕
ttf2tfm arial.ttf -p 8r.enc -t cork.enc -v arialx-r-t1.vpl arialx-r-8r.tfm vptovf arialx-r-t1
〔dviout マップ行〕
arialx-r-8r "Arial"
〔LaTeX 文書〕
\documentclass[a4paper]{article}
\DeclareFontFamily{T1}{arialx}{}
\DeclareFontShape{T1}{arialx}{m}{n}{arialx-r-t1}{}
\begin{document}
\usefont{T1}{arialx}{m}{n}\LARGE
A\v{s}a{\l}a\v{z}a!
\end{document}
〔dviout での出力〕
添付画像の通り。〈š〉は正常ですが〈ł〉や〈ž〉は化けます。なお、dvipdfmx で同等の設定をした場合は全て正常です。
そうすると、「その領域にある」 fi とか fl がなぜ化けない(ut さんの出力例を参照)のかが気になるところですが、この理由は単純で、上のコマンドで生成される VF では fi や fl のリガチャをそもそも使っていないからのようです。
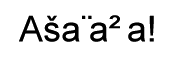
ttfonts.map で例に挙げられている wnsr8r.tfm ですが,これは dviout の配布に含まれる ttnfss package のものを念頭に置いていると思われます.で,この wnsr8r.tfm は 8r ではなく Windows 1252 ですね(確信までは持てていませんが).wnsr8r.pl を作って見てみると,0x00~0x20 あたりのメトリック情報がありません.また,vf での飛ばし方も 8t->8r とは思えません.例えば(8t 側での) 0x00(grave) について見てみると,
%%% Z. R. さんの解説に従って作った arialx-r-t1.vpl
(CHARACTER O 0 (comment grave)
(CHARWD R 333)
(CHARHT R 719)
(MAP
(SETCHAR O 36)
)
)
(8進で)36番に飛ばしている.8r だとこれでいいのだろうが,cp1252 で表示するとまずい.
%%% ttnfss に含まれる wnsr8t.vf から作った wnsr8t.vpl
(CHARACTER O 0
(CHARWD R 0.333)
(CHARHT R 0.6725)
(MAP
(SETCHAR O 140)
)
)
(8進で)140番に飛ばしている.cp1252 の表示でたぶんうまくいく.
%%%
となっています.あと,dvipdfmx の map を見ると,私の環境では wnsr8r に対して winansi.enc が設定されています(大昔から?).これであれば dviout と同じ表示が得られるはずです.無論,cp1252 に飛ばしたところで T1-enc のすべてをカバーできるわけではないので,Z. R. さんが示されたような文字化けは発生します(化け方が違ったりするが).tfnfss を使った例を書いてみると,
\documentclass[a4paper]{article}
\usepackage{timesnew}
\begin{document}
\LARGE
A\v{s}a{\l}a\v{z}a!
\`P
\end{document}
これだと,\l は化け,\v{z} は無くなってしまう(log に warning が出ている)が,\`P は正常に出るはずです.8r に飛ばした場合には \`P も化けてしまうでしょう.それと,timesnew.sty が winenc.sty を呼んでいて,これは T1 類似の input encoding 設定をしています.cp1252 を使った場合にできる限り実用的になるような設定を行っているのでしょう(ちゃんと確かめていないので,多分).winenc.sty では \l は定義されていなく,本来はerror となった方がいいのでしょうが,これは既存の定義が残っちゃっているということなのでしょう.
と,長々と書いてきてしまったのですが version が違えば全然違う話になっているのかもしれません.
%%% Z. R. さんの解説に従って作った arialx-r-t1.vpl
(CHARACTER O 0 (comment grave)
(CHARWD R 333)
(CHARHT R 719)
(MAP
(SETCHAR O 36)
)
)
(8進で)36番に飛ばしている.8r だとこれでいいのだろうが,cp1252 で表示するとまずい.
%%% ttnfss に含まれる wnsr8t.vf から作った wnsr8t.vpl
(CHARACTER O 0
(CHARWD R 0.333)
(CHARHT R 0.6725)
(MAP
(SETCHAR O 140)
)
)
(8進で)140番に飛ばしている.cp1252 の表示でたぶんうまくいく.
%%%
となっています.あと,dvipdfmx の map を見ると,私の環境では wnsr8r に対して winansi.enc が設定されています(大昔から?).これであれば dviout と同じ表示が得られるはずです.無論,cp1252 に飛ばしたところで T1-enc のすべてをカバーできるわけではないので,Z. R. さんが示されたような文字化けは発生します(化け方が違ったりするが).tfnfss を使った例を書いてみると,
\documentclass[a4paper]{article}
\usepackage{timesnew}
\begin{document}
\LARGE
A\v{s}a{\l}a\v{z}a!
\`P
\end{document}
これだと,\l は化け,\v{z} は無くなってしまう(log に warning が出ている)が,\`P は正常に出るはずです.8r に飛ばした場合には \`P も化けてしまうでしょう.それと,timesnew.sty が winenc.sty を呼んでいて,これは T1 類似の input encoding 設定をしています.cp1252 を使った場合にできる限り実用的になるような設定を行っているのでしょう(ちゃんと確かめていないので,多分).winenc.sty では \l は定義されていなく,本来はerror となった方がいいのでしょうが,これは既存の定義が残っちゃっているということなのでしょう.
と,長々と書いてきてしまったのですが version が違えば全然違う話になっているのかもしれません.
ネット環境のない実家から帰って参りました。
さて。私の適当な書き込みから、Z. R. さんと山本さんがキチンと調べてくださったお蔭で、私もよく事情が分かりました。
> CP1252 を近似的に TeXBase1 エンコーディング(8r エンコーディング)と見做し
実際はそういうことだったのですか!
>「その領域にある」 fi とか fl がなぜ化けない(ut さんの出力例を参照)のかが気になるところですが、この理由は単純で、上のコマンドで生成される VF では fi や fl のリガチャをそもそも使っていないからのようです。
あらら、リガチャじゃなかったのですね…。ちゃんと調べもせずに、一見うまくいったように思えると嬉しくなってつい書きこんでしまうといういつもの悪い癖が出てしまいました。
> ttfonts.map で例に挙げられている wnsr8r.tfm ですが,これは dviout の配布に含まれる ttnfss package のものを念頭に置いていると思われます.で,この wnsr8r.tfm は 8r ではなく Windows 1252 ですね
> あと,dvipdfmx の map を見ると,私の環境では wnsr8r に対して winansi.enc が設定されています
確かに、そうなってます!
> それと,timesnew.sty が winenc.sty を呼んでいて,これは T1 類似の input encoding 設定をしています.
そうだとしますと、ttf2tfm で 8r(類似)の tfm を作る際に、-p 8r.enc ではなくて -p winansi.enc として、また、原稿では winenc.sty を読み込むようにすれば、TTNFSS バンドルと同じように一般の TrueType フォントを dviout で使えるということでしょうか。
(TTNFSS の readme.txt の末尾に乙部先生がちゃんと「T1 エンコードを使う場合、別途 winenc.sty ファイルを読み込んでください。」と書いてらっしゃいますね…)
>そうだとしますと、ttf2tfm で 8r(類似)の tfm を作る際に、-p 8r.enc ではなくて -p winansi.enc として、また、原稿では winenc.sty を読み込むようにすれば、TTNFSS バンドルと同じように一般の TrueType フォントを dviout で使えるということでしょうか。
ttnfss と同じようにというのを目指すならそれでいいような気がします,自信はないのですが.ただ,もう一つ気になることがあって,ttnfss 環境下で \v{z} が消えてしまう件です.こいつをちょっと調べてみました.log file には
Missing character: There is no ^^ba in font wnsr8t!
とあり,^^ba = O 272 (zcaron) というやつですよね.wnsr8t の tfm や vf を調べてみると O 272 のメトリック情報がありません.ということは,wnsr8t.tfm は厳密には T1-enc ではないことになります.また,winenc.sty でも \v{z} は定義されていません.ああ,対応するものが無いから未定義にするように tfm もチューンしているんだな.と思っていたら,cp1252 には 0x9E に zcaron が存在しています.そこで今度は -p winansi.enc -t cork.enc を用いて作った vpl を見ると O 236 = 0x9E に飛ばしており,こちらを使ってやると dviout でちゃんと表示もできます.おそらく初めは T1->8r の構成で作っていて,cp1252 でうまく表示できないところは tfm 側を未定義にしたのではないかと思います.
まあ,dviout 以外の dviware との互換性を考えるなら,T1->8r が主流でしょうからそれでもいいし,T1->winansi だと使えるアクセント記号が少し増える.OT1 でギリシャ文字大文字まで出ないと気が済まない,なんていう場合にはこのような方法では無理なので,完全を目指すなら Z. R. さんの sfd を使った裏技が一番いいですね.
>> 自分への補足です.
ttnfss に含まれる vf(vpl を作成) を見てみると,作り方が書いてありました.
%%% from wnsr8t.vpl %%%
(VTITLE Created by afm2tfm afm\monotype\times\wnsr8a -t ecwin.enc -p win8r.enc -v vpl\monotype\times\wnsr8t.vpl)
%%% from wnsr7t.vpl %%%
(VTITLE Created by afm2tfm afm\monotype\times\wnsr8a -u -t OT1.enc -p win8r.enc -v vpl\monotype\times\wnsr7t.vpl)
各 enc file はお手製っぽいですね.\usepackage[OT1]{timesnew} とすると,OT1-enc に対応することになっていて,その際には上の wnsr7t 等が用いられます.文字一覧を作ってみると,ギリシャ文字部分がばっさり削ってあったりして... win8r.enc 側にギリシャ文字のグリフ名が無いので wnsr7t 側で定義が無くなっているのでしょうね.ターゲットエンコーディング名は win8r.enc か,開発者が tfm名等に 8r を冠している理由も見えてきました.
ttnfss に含まれる vf(vpl を作成) を見てみると,作り方が書いてありました.
%%% from wnsr8t.vpl %%%
(VTITLE Created by afm2tfm afm\monotype\times\wnsr8a -t ecwin.enc -p win8r.enc -v vpl\monotype\times\wnsr8t.vpl)
%%% from wnsr7t.vpl %%%
(VTITLE Created by afm2tfm afm\monotype\times\wnsr8a -u -t OT1.enc -p win8r.enc -v vpl\monotype\times\wnsr7t.vpl)
各 enc file はお手製っぽいですね.\usepackage[OT1]{timesnew} とすると,OT1-enc に対応することになっていて,その際には上の wnsr7t 等が用いられます.文字一覧を作ってみると,ギリシャ文字部分がばっさり削ってあったりして... win8r.enc 側にギリシャ文字のグリフ名が無いので wnsr7t 側で定義が無くなっているのでしょうね.ターゲットエンコーディング名は win8r.enc か,開発者が tfm名等に 8r を冠している理由も見えてきました.
おはようございます。
> ttnfss と同じようにというのを目指すならそれでいいような気がします,
………
> そこで今度は -p winansi.enc -t cork.enc を用いて作った vpl を見ると O 236 = 0x9E に飛ばしており,こちらを使ってやると dviout でちゃんと表示もできます.
確かに、どうしても TTNFSS に合わせなければならない、という理由はないです。Zcaron を使う日が来るかどうかは分かりませんけれど、winansi.enc を使えば Zcaron も出せるわけですし。
> ただ,もう一つ気になることがあって,ttnfss 環境下で \v{z} が消えてしまう件です.
………
> 各 enc file はお手製っぽいですね.
………
> ターゲットエンコーディング名は win8r.enc か,開発者が tfm名等に 8r を冠している理由も見えてきました.
wnsr8r.tfm のグリフ一覧を作ってみますと、142 番の Zcaron と 158 番の zcaron がありません。これがつまり、
> CP1252 を近似的に TeXBase1 エンコーディング(8r エンコーディング)と見做し
ということの差なのでしょうね。8r.enc では Zcaron と zcaron が 14 番と 15 番なので、8r の 0x20 から 0xFF に合わせて作ったと思われる “win8r.enc” では、この二つのグリフをはずしたということが推測されます。なるほど。
今回は、余計な口を挟んだせいで、とても勉強になりました。ありがとうございました。
「ありがとうございました」といって締めたつもりでしたが、ちょっと補足を(すいません…)。
上の私の書き込みですと、0x20 から 0xFF については、Zcaron と zcaron しか、8r と CP1252 の差がないみたいに聞こえてしまいますが、先に山本さんがご指摘くださったように、grave とかも違っています。
既に Z. R. さんがグリフの表を並べてくださっていますが、真似をして作ってみました(Z. R. さんみたいに全スロットを埋めたかったのですけど、Latin Modern では埋まらないみたいです)。
色を塗ったところが 8r と CP1252 で異なるコードですが、ホント、ほとんど同じなのですね(Adobe Reader でしか確認していないので、他のビューアだとちゃんと表示されないかも知れません)。
上の私の書き込みですと、0x20 から 0xFF については、Zcaron と zcaron しか、8r と CP1252 の差がないみたいに聞こえてしまいますが、先に山本さんがご指摘くださったように、grave とかも違っています。
既に Z. R. さんがグリフの表を並べてくださっていますが、真似をして作ってみました(Z. R. さんみたいに全スロットを埋めたかったのですけど、Latin Modern では埋まらないみたいです)。
色を塗ったところが 8r と CP1252 で異なるコードですが、ホント、ほとんど同じなのですね(Adobe Reader でしか確認していないので、他のビューアだとちゃんと表示されないかも知れません)。
私もあと少しだけ補足を.ttnfss におけるエンコーディングについてです.
まず,次のようにして T1->winansi の構成を作ったとします.
ttf2tfm times.ttf -p winansi.enc -t cork.enc -v timesnew-t1.vpl timesnew-wa.tfm
vptovf timesnew-t1
この場合,両 enc で対応が取れなかった timesnew-t1 スロットには,winansi.enc の定義が「降って」きます.例えば O 251 (copyright) の部分について timesnew-t1.vpl を見ると
(CHARACTER O 251 (comment copyright)
(CHARWD R 759)
(CHARHT R 677)
(CHARDP R 15)
)
とあり(SETCHAR が無いことにも注意),これが timesnew-t1.tfm にも反映されるので,timesnew-t1.tfm は T1-enc とは異なるものになります.この「定義が降ってくる」現象は -u オプションで防げますが,その場合には timesnew-t1.tfm 側のスロットは単に未定義になります.いずれにせよ T1-enc とは完全には同じものにはなりませんが,それは問題とはしないとします.
次に,wnsr8t.vf から作った vpl を見ると,
(CHARACTER O 207
(CHARWD R 0.759)
(CHARHT R 0.6725)
(CHARDP R 0.015)
(MAP
(SETCHAR O 251)
)
)
とあり,wnsr8t.tfm における copyright は O 207=0x87 にあり,それを O 251=0xA9 に飛ばしていることが解ります.これは,ecwin.enc の段階で 0x87 copyright を配置していることが推測されます.8r も cp1252 も copyright は 0xA9 にあるのにわざわざ場所を移動している理由はよくわかりません.0x80~0xBF の部分でこの類の移動が引きおこっており,ecwin.enc はこの部分に関して独自のエンコーディングとなっているようです.そしてさらに winenc.sty でこの O 207=0x87 の copyright が使えるようにしています.
%%% from winenc.sty %%%
...
\DeclareTextSymbol{\textyen}{T1}{'203}
\DeclareTextSymbol{\textcopyright}{T1}{'207}
...
%%%%%%%%%%%%%%%%%%%%%%%
このことからも 0x80~0xBF の部分で積極的というか自発的に独自エンコーディングを定義していることが推測されます.また,wnsr8t.vpl では定義がされている全てのスロットで SETCHAR が使われており,上述の「降り込み」は起こっていないようです(それを嫌っているのかも?).
以上のことから,ttnfss と同じものを目指す場合には enc file をそれなりに作りこまなければなりません.target enc は winansi.enc から Zcaron と zcaron の2つを抜いてやれば多分それでよい(いや,抜かない方が私はいいと思うが).base enc は vpl 等をよーく見て作成することが必要.まあ,cork.enc の 0x80~0xBF の部分を書き変え,さらに「降り込み」が起こらないようにしておけばよいのでしょう.
まず,次のようにして T1->winansi の構成を作ったとします.
ttf2tfm times.ttf -p winansi.enc -t cork.enc -v timesnew-t1.vpl timesnew-wa.tfm
vptovf timesnew-t1
この場合,両 enc で対応が取れなかった timesnew-t1 スロットには,winansi.enc の定義が「降って」きます.例えば O 251 (copyright) の部分について timesnew-t1.vpl を見ると
(CHARACTER O 251 (comment copyright)
(CHARWD R 759)
(CHARHT R 677)
(CHARDP R 15)
)
とあり(SETCHAR が無いことにも注意),これが timesnew-t1.tfm にも反映されるので,timesnew-t1.tfm は T1-enc とは異なるものになります.この「定義が降ってくる」現象は -u オプションで防げますが,その場合には timesnew-t1.tfm 側のスロットは単に未定義になります.いずれにせよ T1-enc とは完全には同じものにはなりませんが,それは問題とはしないとします.
次に,wnsr8t.vf から作った vpl を見ると,
(CHARACTER O 207
(CHARWD R 0.759)
(CHARHT R 0.6725)
(CHARDP R 0.015)
(MAP
(SETCHAR O 251)
)
)
とあり,wnsr8t.tfm における copyright は O 207=0x87 にあり,それを O 251=0xA9 に飛ばしていることが解ります.これは,ecwin.enc の段階で 0x87 copyright を配置していることが推測されます.8r も cp1252 も copyright は 0xA9 にあるのにわざわざ場所を移動している理由はよくわかりません.0x80~0xBF の部分でこの類の移動が引きおこっており,ecwin.enc はこの部分に関して独自のエンコーディングとなっているようです.そしてさらに winenc.sty でこの O 207=0x87 の copyright が使えるようにしています.
%%% from winenc.sty %%%
...
\DeclareTextSymbol{\textyen}{T1}{'203}
\DeclareTextSymbol{\textcopyright}{T1}{'207}
...
%%%%%%%%%%%%%%%%%%%%%%%
このことからも 0x80~0xBF の部分で積極的というか自発的に独自エンコーディングを定義していることが推測されます.また,wnsr8t.vpl では定義がされている全てのスロットで SETCHAR が使われており,上述の「降り込み」は起こっていないようです(それを嫌っているのかも?).
以上のことから,ttnfss と同じものを目指す場合には enc file をそれなりに作りこまなければなりません.target enc は winansi.enc から Zcaron と zcaron の2つを抜いてやれば多分それでよい(いや,抜かない方が私はいいと思うが).base enc は vpl 等をよーく見て作成することが必要.まあ,cork.enc の 0x80~0xBF の部分を書き変え,さらに「降り込み」が起こらないようにしておけばよいのでしょう.
dviout のフォントの扱いについては、トニイさんのサイトにある次の資料に、すべて書かれていました。
これを見ると、「dviout 流の 8r と T1 を確立しようとしている」という意図を感じ取ることができます。
この文書自体は(別の目的で)少なくとも 3 回は読んだことがあるのですが、それにも関わらず、ここに答えが書いてあったことに気付かなかったということにショックを覚えています。恐らくは「いつもの 8r の話が書いてある」と早とちりして読み飛ばしてしまってたのでしょう。
あまりにショックなので、ブログに記事を書きました ;-)
このシリーズはあと 1 回、実際の作業手順を紹介する記事を書いて終わることになると思いますが、そこで使うデータ aencdviout.zip を奥底の簡易包装コーナーに置きました。このアーカイブの中に win8r.enc と ecwin.enc を再現したものが含まれています。
- Zcaron(Ž)/zcaron(ž) について: Windows-1252 に関する Wikipedia の記事によると、これらの文字はこのコードページに後から追加された文字のようです。だから、TeXBase1 と同じく Windows-1252 を基礎とするコードである TeXnANSI(LY1)でも、この文字の符号位置は異なっています。(Windows-1252=0x8E/0x9E; TeXBase1=0x0E/0x0F; LY1=0x8D/0x9D) それを考えると、単純に、TTNFSS パッケージを作ったころには Windows-1252 に Ž/ž がまだ無かったのだと思います。もし今「dviout 流 T1」を構成するのならば 0x9A/0xBA(T1 の符号位置)に Ž/ž を入れることになるのでしょう。
- 「降り込み」は ttf2tfm の仕様なので、TeXBase1 → T1 の VF を構成した場合にも起こります。この場合、TeXBase1 になくて T1(本物)にある文字に対する最善の扱いは「グリフ合成」をすることなのでしょう(ptmr8t を参照)。ここで「元の(Type1/OpenType)フォントがそのグリフを持っているならば当然それを使いたい」と考えるなら、そもそも TeXBase1 を介在させる方法が不適当です。(dviout でない場合の話。)
- 「全部のスロットが埋まっているコード表」は「M+ 1P Medium」で作成したものです。
- TTNFSS の wnsr?? を実際に dviout で表示させたものの画像(dviout の画像出力を利用)を添付しておきます。

# 我ながら切りがないと思いつつ…。
乙部先生の web ページに、乙部先生が作られた win8r.enc と ECwin.enc がありました。
http://argent.shinshu-u.ac.jp/~otobe/tex/packages/perfectcollection.html
の、「TrueTypeフォントの利用」の部分の
生成キット 170KB
http://argent.shinshu-u.ac.jp/~otobe/tex/packages/files/ttnfss/wttfpccr.lzh
の中にあります。ご参考まで。
・最後の最後に余計な感想:
dviout では、map ファイルで enc ファイルを指定して実フォントの並べ替えが出来るようになっていないようですので、そうしますと、結局、CP1252 の 0x20 から 0xFF までのグリフしか使えないということになりそうです。
そこで、TTNFSS の場合には、CP1252 の 0x20 から 0xFF までには含まれていない T1 のグリフのスロット(0x80 から 0xBF)を有効に利用するために、そこに、CP1252 の 0x80 から 0xBF のグリフを入れているのかな、と感じました。
> Z. R. さん
>Zcaron(Ž)/zcaron(ž) について: Windows-1252 に関する Wikipedia の記事によると、これらの文字はこのコードページに後から追加された文字のようです。...
なるほど.確かに win8r.enc は本物の 8r とは関係なく初めから cp1252 を意図したものであることがはっきりしてきました.
> ut さん
>乙部先生の web ページに、乙部先生が作られた win8r.enc と ECwin.enc がありました。
おお,乙部さんのページは見てたのですがここにあるのか.
>そこで、TTNFSS の場合には、CP1252 の 0x20 から 0xFF までには含まれていない T1 のグリフのスロット(0x80 から 0xBF)を有効に利用するために、そこに、CP1252 の 0x80 から 0xBF のグリフを入れているのかな、と感じました。
cp1252 の中でそのまま T1 として使えるグリフを T1 の位置に並べてみる.すると,0x8? と 0xA? の部分がすっぽり空きになる.合字合成はせず cp1252 にある種々のグリフを利用するというコンセプトをとると,例えば 0xB2(上付き添え字の2かな) はどこかに移動しなければならない.で,空いている 0x8?, 0xA? に全てを並べてみるとうまく収まっている.こんな感じでしょうか.