Windows11の富士通ノートパソコンにTEX23年版をのせて論文をかいています。シュプリンガー社の雑誌に投稿しようとしたところ、bibファイルの使用を求められました。そこで美文書作成入門第8版11.7「BIBTEXの実行例」に見習って、下のようなサンプルファイル(infinit290.tex)とbibファイル(mini.bib)を作って、添付のスクリーンショットbib1~bib5のようにテスト
してみましたがうまくいきません。
(infinit290.tex)
\documentclass[sn-mathphys]{sn-jnl}
\setlength{\textwidth}{16cm}
\setlength{\oddsidemargin}{0cm}
%\setlength{\oddsidemargin}{0.5cm}
\setlength{\evensidemargin}{0cm}
\setlength{\topmargin}{-2cm}
\setlength{\textheight}{25cm}
%iicol,referee,,pdflatex
\usepackage{amsmath}
\usepackage{graphicx}
\usepackage{setspace}
\doublespacing
\begin{document}
\title{(manuscript)
The infinite and contradiction: The history of mathematical physics by dialectical approach}
\maketitle
keywords: infinity, contradiction, history, mathematical physics, dialectic, reverse mathematics
\section{Introduction}
\ \
"Philosophy of science without history of science is empty; history of science without philosophy of science is blind." \cite{Lakatos}
E. Wigner said, "The first point is that the enormous usefulness of mathematics in the natural sciences is something bordering on the mysterious and that there is no rational explanation for it."\cite{Wigner} This quotation from the pioneer of quantum physics shows that elucidating the essential nature of mathematics is important for the natural science.
\bibliographystyle{sn-mathphys}
\bibliography{mini}
\end{document}
(mini.bib)
@book{Lakatos,
author = {Lakatos, Imre},
year = {1970},
title = {History of science and its rational reconstructions},
booktitle = {Proceedings of the Biennial Meeting of Philosophy of Science Association},
pages = {91-136},
publisher = {Springer},
}
@book{Wigner,
author = {Wigner, Eugene P},
year = {1967},
title = {The unreasonable effectiveness of mathematics in the natural sciences},
booktitle = {Symmetries and reflections},
publisher = {Indiana Univ. Press},
}
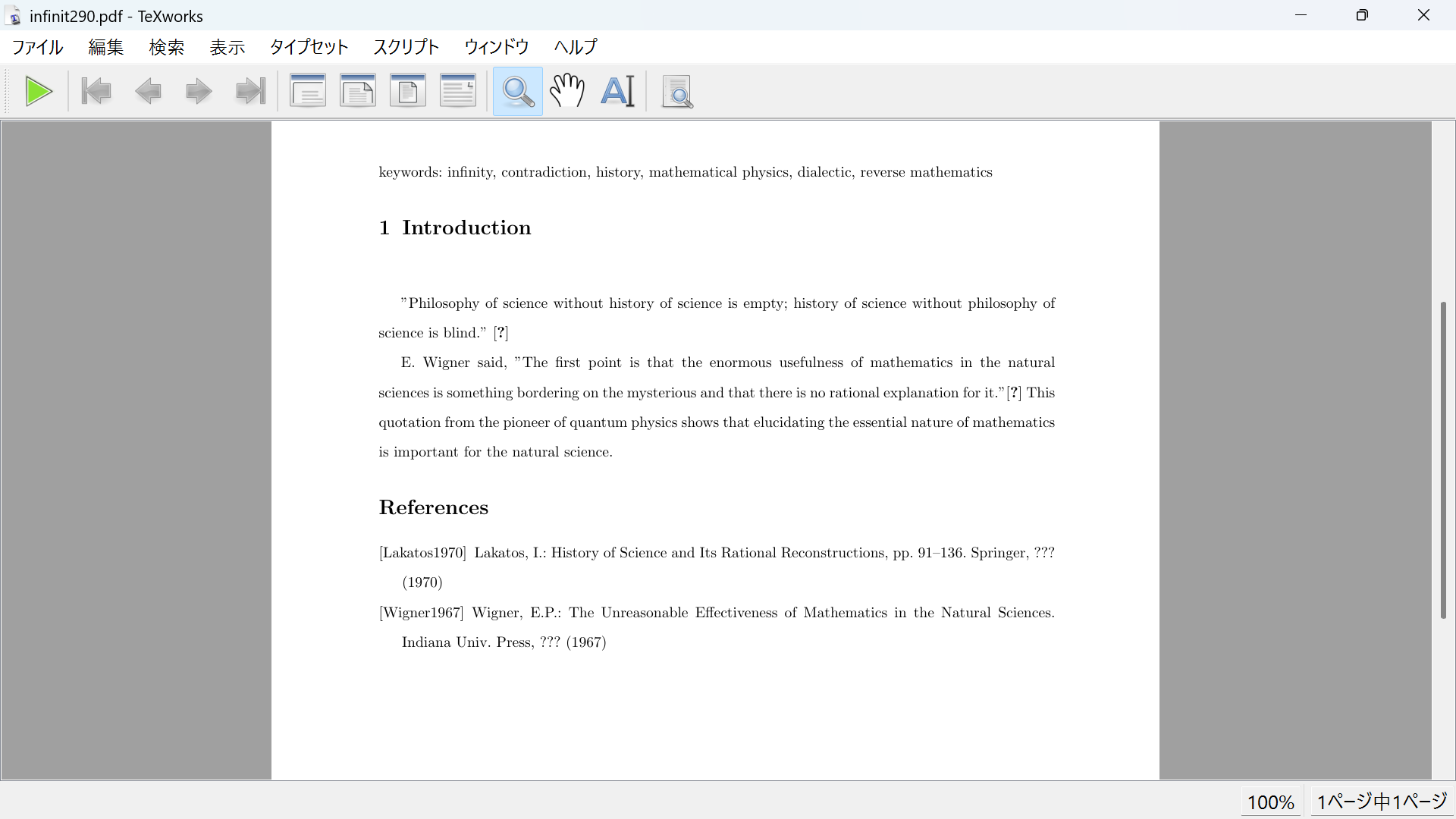
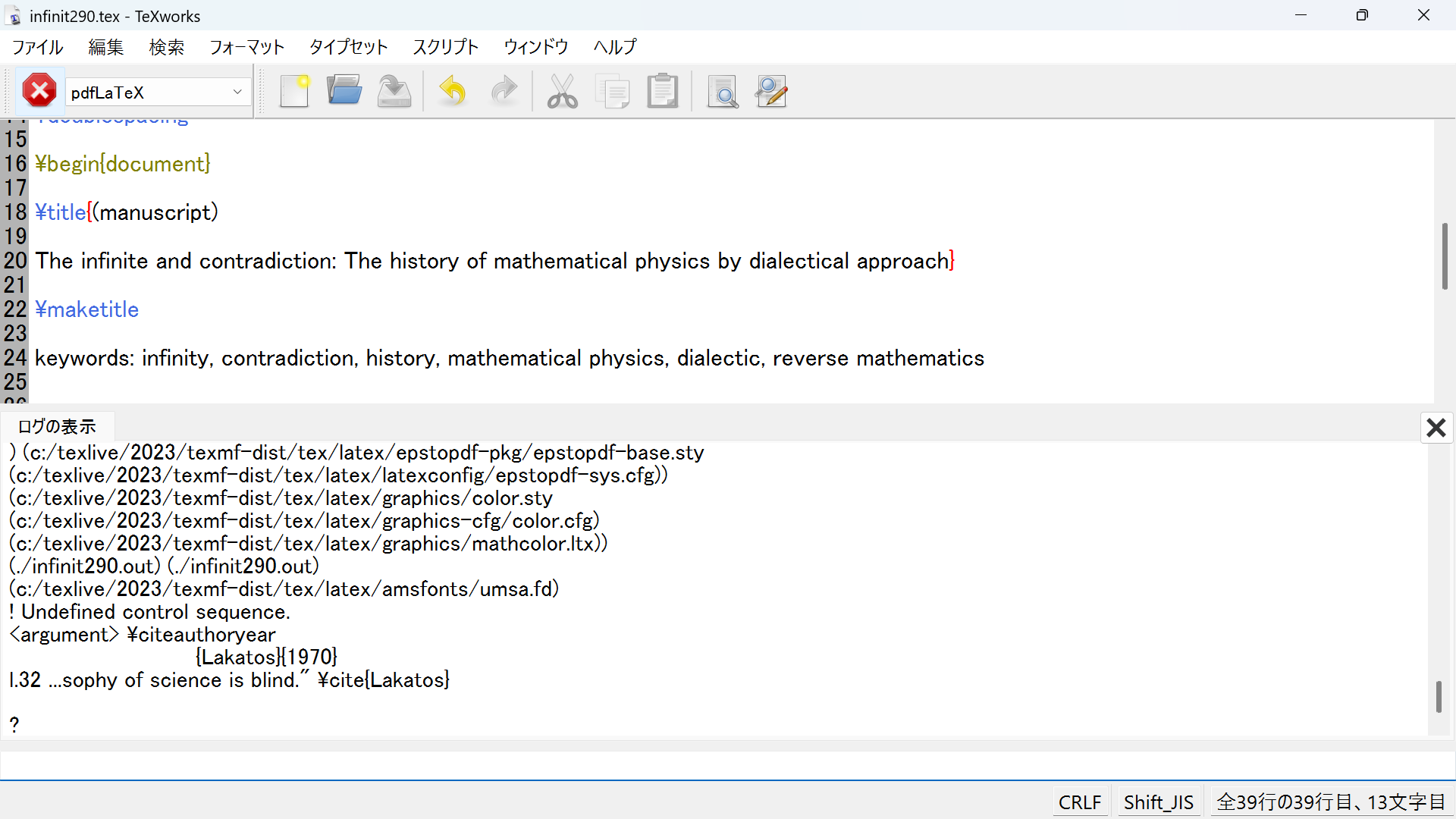
以下texworksで作業しました。まずinfinit290.texをpdfLATEXでタイプセットすると、スクリーンショットbib1のようにPDFのタイプセット前に\citeで文献を指示した箇所に???が入ります。次にスクリーンショットbib2のようにタスクバーのタイプセット欄にBIBTEXを入れてタイプセットし(タスクバー左端の三角形をクリックし)、続いてまたpdfLATEXでタイプセットすると、スクリーンショットbib3のようにエラーで中断されます。さらにまたpdfLATEXでタイプセットすると、スクリーンショットbib4のようにbib1と同じ画面になり、もう一度pdfLATEXでタイプセットすると、スクリーンショットbib5のようにbib3のようにエラーで中断されます。bibファイルについて教えていただければ幸いです。
参考にlogファイルを保存したもの(infinit290log.txt)と使用されたシュプリンガー社提供ファイル3件(sn-...)を添付します。(以前和田様にbibファイルについて教えて頂きましたがまた分からなくなりました。すみません。)
植木