[2019-02-04] ざっと改訂した。
[2020-10-03] 最後に追記を設けた。
[2023-10-13] Excelの問題はかなり改良された。詳しくはExcel で CSV ファイルを扱う場合の注意参照。
例えば日本の人口は1.26億人であるといった個々の「事実」は自由に伝達できる(著作権法第十条2「事実の伝達にすぎない雑報及び時事の報道は、前項第一号に掲げる著作物に該当しない」)が,事実を集めたデータベースは一般に著作権法で保護される(著作権法第十二条の二「データベースでその情報の選択又は体系的な構成によつて創作性を有するものは、著作物として保護する」)。
政府統計の総合窓口(e-Stat)にはたくさんのデータが収められているが,そのご利用にあたってには「商用目的で複製する場合は、予め個々の情報に関する著作権を有している各府省等までご相談下さい」と書かれており,一定の制約があるようである。本稿を最初に書いた2013年時点では書かれていた(現状については下記参照)。このような制約をなくして,商用目的も含めて自由に使えるようにした「オープンデータ」が増えつつある。オープンデータを提供するサイトとしては,米国のData.gov,英国のdata.gov.ukが有名であるが,日本でもOpen DATA METIや,流山市のオープンデータトライアル,鯖江市のデータシティ鯖江などが知られている。日本でもオープンデータを銘打ったサイトがいろいろ現れた。
消えたOpen DATA METIは時限的な実験サイトで,現在はデータカタログサイトに集約されたようだ。流山市はオープンデータカタログサイトを立ち上げてそちらに移動,データシティ鯖江はURLが変わってこちらに移動。
せっかくオープンデータを公開しても,サイトリニューアルごとにURLが変わることが多い。データカタログサイトも2019-03-18にhttpからhttpsに変わり,リダイレクトされないので従来のhttpリンクがすべてリンク切れになった(アナウンス)。Cool URIs don't change(邦訳クールなURIは変わらない)参照。
オープンデータへの動きは電子行政オープンデータ実務者会議において着実に進められ,そこからリンクされている2015年12月の「政府標準利用規約(第2.0版)」(後述のCC BY 4.0と互換性がある)に結実した。現在の政府統計の総合窓口(e-Stat)の利用規約はこれに合わせて書き直されている。つまり,e-Statにあるデータは今やすべてオープンデータである。このページを書き始めたころと比べれば,大きな進歩である。
オープンデータについての詳細はThe Open Data Handbook(和訳:オープンデータ・ハンドブック)を参照されたい。オープンデータのライセンスとしては,Creative Commonsの分類ではCC0またはCC BY,最もきつい条件でもCC BY-SAが限度である(WikipediaのライセンスがCC BY-SAである)。NC(非営利)では企業の利用が難しく,ND(改変禁止)ではそもそもマッシュアップ(他のデータと組み合わせて新しい価値を生み出すこと)ができない。
オープンデータを提供するファイル形式としては,CSVまたはTSV,JSON,XML,RDF(右に行くほど難易度が高くなる!)のようなテキストベースのオープンかつ単純な形式(機械可読な形式)が望ましい。
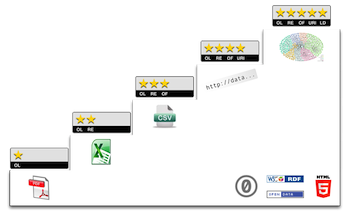
以上のことについて,Tim Berners-Leeの考え方を図解でまとめた5 ★ OPEN DATA(和訳:5 ★ オープンデータ)というサイトがわかりやすい。
この5段階を誰がどこまで登るかについての楠さんたちとの議論をオープンデータ☆5段階を誰がどこまで昇るのか - Togetterにまとめていただいた。
5-star の図の2文字略語は OL: Open License,RE: machine REadable,OF: Open Format,URI: Uniform Resource Identifiers,LD: Linked Data を意味する(5stardata.infoのissue)。
上のTim Berners-Leeの考え方では,★はPDFなど,★★はExcelなど,★★★は「非独占の形式」(CSVなど)となっている。一方,Excelの新しい保存形式*.xlsxはOffice Open XML(OOXML)としてISO/IEC規格になったので「非独占の形式」ではないという反論がある(OpenOffice.org/LibreOfficeのOpenDocument Format(ODF)もISO/IEC規格である)。それは確かにそうであるが,Rなどでネイティブに(Javaプログラムなどを介さず)読めるフォーマットでないという点では,うれしくない。Rでも,readxl パッケージを使えば,単純なExcelファイル(CSVファイルと互換性のあるもの)を読めるようになった。
Tim Berners-Leeのいう「非独占の形式」の例としてはCSV(Comma-Separated Values)形式が挙げられている。これは値をコンマで区切っただけの非常に簡単な形式で,ExcelからもCSV形式で保存できる。Excelをインストールした環境では拡張子*.csvはExcelに関連付けられるので,ダブルクリックしただけでExcelで開けるという利点もある。英国のdata.gov.ukでは大量のデータがCSV形式で公開されている。
CSV(コンマ区切り)と同様なTSV(タブ区切り,Tab-Separated Values)形式もあるが,Excelに関連づけられた拡張子がない(「開く」メニューからは開ける)ということもあり,CSVのほうがポピュラーである[しかし下の「新事実発見」参照]。
CSVやTSVは,Excelのような「セルの結合」ができないので,機械的に処理しやすいデータを強制できるという利点もある。
TSVの拡張として,フィールド(項目,列)の名前や個数を行ごとに自由に変えられる Labeled Tab-separated Values (LTSV) という形式も提案されている(LTSV FAQ - LTSV って何? どういうところが良いの? 参照)。さらに柔軟な,木構造のデータも許すJSONやXMLといった形式が,近年よく使われている。
震災後の放射線などのデータが自動処理しにくい形で提供されていたことはすでに指摘した(データは自動処理可能な形で提供してほしい)。同様な指摘が多方面からされていたことが高度情報通信ネットワーク社会推進戦略本部第14回 電子行政に関するタスクフォース 議事次第の資料1,p.8からわかる:

この後日談など話せば尽きない。例えば,現時点でも厚労省は「食品中の放射性物質の検査結果について(第XXX報)」というPDFを毎日掲載しており,私が毎日CSV化してここに置き,食品の放射能データ検索で検索できるようにしている[←2012〜2013年の話。現在は厚労省の委託により国立保健医療科学院が食品中の放射性物質検査データサイトを運営している]。
以下ではオープンデータとしてとりあえず妥当なファイル形式と考えられるCSV形式を例に,機械で処理しやすいデータの作り方を解説する。
ここでは,たまたまこれを書き始めた2013年1月にe-Statの新着情報に出ていた労働力調査のデータをクリーンなCSVにしてみる。元データ(Excelファイル)のURLは長ったらしくて永続性があるかわからないのでリンクは省略するが,メニューで「労働力調査」→「基本集計 全都道府県」→「長期時系列データ」→「月別結果―全国」→「労働力人口 1953年1月〜」でたどれるExcelファイルの「原数値(既公表値)」シートは次のようになっている:
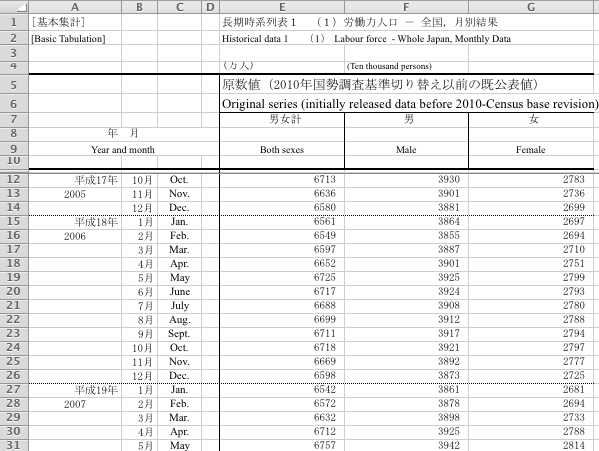
人間が読みやすいように罫線を引いたりセルを結合したり空セルを入れたりして苦労しているが,自動処理には向かない。これを,1行目に列の名前,2行目からデータの並んだ標準形式に直す。
まず年月の形式を揃える。列を挿入するか不要な列を選択し,「セルの書式設定」の「ユーザー定義」で「yyyy/mm」(または「yyyy-mm」)のような日付を表す形式を設定する。データ部分の最初の2セルにそれぞれ「2005/10」「2005/11」を入れて選択し,フィルハンドル(選択領域の右下の小さな正方形)を下にドラッグすると,自動的に「2005/12」「2006/01」…が入る。
フィルハンドルを下にドラッグする方法で日単位のデータはうまくいくが,時単位のデータは誤差が累積する。これはExcelの内部形式が日単位の浮動小数点数のためである(RでExcelのデータを読む方法参照)。このときは,とりあえずRで読み込んで round(..., "hours") として時単位に丸めればよい。
余分な行・列を削除する。「男女計」のように他のデータから簡単に求められる値も削除する。日付以外の列は「セルの書式設定」で「標準」に揃える(これで3桁ごとのコンマも外れる)。
ここではないが,もし欠測値(missing values)があれば,空セルのままにしておくか,「NA」(Not Availableの略)または「-」など一定の文字列を入れておく。ExcelやCSVでは欠測値は空セルでよいが,ExcelからPDFにしてPDFだけ公開する場合は,PDFをpdftotextコマンドでテキストに変換するとき,空セルと列ずれの区別がつかなくなる。
Excelで「NA」に相当するものは #N/A である。CSVファイルに #N/A と書いておけばよい。出力も #N/A になる。ただし,CSVで # をコメント開始文字としている場合は,"#N/A" とする必要がある。
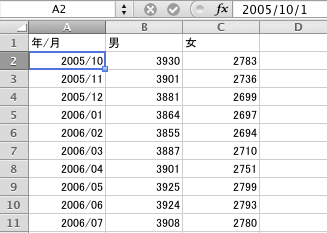
この時点でセルA2の内容は「2005/10/1」(または「2005-10-1」)になっているはずである。Excelで処理をする際に,もし各月の中央がよければ,最初の二つを「2005/10/15」「2005/11/15」に直し,選択してフィルハンドルを下にドラッグする。CSV出力するだけなら1日でも15日でも同じ結果になる。
これをExcelから「ファイル」→「名前を付けて保存...」→「CSV (コンマ区切り)」で保存すると,次のようなCSV形式のテキストファイルになる。
年/月,男,女
2005/10,3930,2783
2005/11,3901,2736
2005/12,3881,2699
2006/01,3864,2697
2006/02,3855,2694
……
文字コードはShift_JIS(Windows-31J)になる。行末はMacのExcelではCR,WindowsのExcelではCRLFになる。昔のMacのExcelはCRであったが,CSVの決まり(後述)ではCRLFを使うことになっているので統一されたのかもしれない(Rで読み込む場合は行末はCR/LF/CRLFどれでもよい)。文字コードは,時代の流れからすればUTF-8が好ましいが,日本語環境のExcelでは文字化けすることがある[新しいExcelではBOM付きUTF-8なら化けないようである]。
「文字化けすることがある」と書いたが,拡張子を「.txt」に変えてExcelの「開く」メニューから開けば,テキストファイルウィザードが現れて,Windows版Excelではうまくいくようである(どういうわけかMac版ではうまくいかない)。ダブルクリックして開く場合は,Windows版Excel 2010以降はBOM付きUTF-8なら文字化けせず開けるが,Mac版Excel 2011ではShift_JIS以外うまくいかない[Mac版Excel 2016でBOM付きUTF-8のCSVが開けるようになった]。英語(ASCII文字)で統一すれば文字コードの問題は生じず,海外の人にも使ってもらいやすくなるので一挙両得であるが,ここでは文字コードの問題を顕在化させるために,あえて日本語を使った。
なお,上のCSVファイルをExcelで再度開くと,私の環境では日付部分が「Oct-05」のような英語表記になってしまう。とりあえず列全体を選択し「セルの書式設定」の「ユーザー定義」で「yyyy/mm」に直せば戻る。あるいは,「セルの書式設定」で「日付」の「2005年3月」の形式を選んでから保存すれば,再度読み込んでも日本語のままだが,海外の人が使いにくい。
[2013-02-18(?)] 文字コードをUTF-16LEにしたタブ区切り(TSV)の拡張子をcsv(またはxls)に偽装すれば,何とWindowsでもMacでもダブルクリックでExcelで正常に開ける。セル中にコンマがあってもダブルクォートで囲まなくても大丈夫 → Win/Mac どちらの Excel でも正しく開ける Unicode な csv の出力方法
[2016-10-23(?)] MacのExcel 2016では,Windows版と同様,BOM付きUTF-8のCSVファイルなら文字化けせず開けるようになった。また,Mac版・Windows版とも,Excelで「CSV UTF-8 (コンマ区切り) (*.csv)」(Windows版),「CSV UTF-8 (コンマ区切り) (.csv)」(Mac版)という保存形式がサポートされた(いずれもBOM付き)。これでExcel→CSV,CSV→Excelとも問題なくできるようになった(日付と解釈される文字列だけは要注意)。
BOMについて追記: R 3.0.0から read.csv("...", fileEncoding="UTF-8-BOM") というエンコード指定ができるようになった。ただし MacのRはBOM付きでもデフォルト("UTF-8" だけでも問題なく読めるようである。"UTF-8")で読めるが,WindowsのRは"UTF-8-BOM")を指定しないとBOMが正しく扱われないようである。書き出す際には "UTF-8-BOM" 指定はできないので,readr::write_excel_csv() を使うのが便利。
[2022-04-25] R 4.2.0からWindows版もMac版と同様にUTF-8がデフォルトになった。もう read.csv("...", fileEncoding="UTF-8") や read.csv("...", fileEncoding="UTF-8-BOM") という指定は不要(SJISのときだけ read.csv("...", fileEncoding="CP932") が必要)。
Pythonのpandasでのデータの読み書きは,MacでもWindowsでもデフォルトUTF-8で,読む際にBOMは無視され,書く際には encoding="utf_8_sig", line_terminator="\r\n" のようにBOM付きやCRLFを指定できる。
このように不要部分を削ったCSVファイルは,それだけでは何のデータかわからないので,説明ページを別途用意しておく。あるいは,CSVの決まりごとには定められていないが,行頭に「#」などの目印を付けて注釈を書いておくこともしばしば行われる。Rの read.csv() 関数で読み込む場合はオプション comment.char="#" を付けると「#」で始まる行を無視する。
# 日本の労働力人口
# Labor Force of Japan
# 年/月,男,女
Year/Month,Male,Female
2005/10,3930,2783
2005/11,3901,2736
2005/12,3881,2699
2006/01,3864,2697
2006/02,3855,2694
……
# 2011年3-8月は推定値
CSV(Comma-Separated Values)形式の詳細はRFC 4180で決められている。WikipediaのComma-Separated Valuesに解説がある。
CSVの細かな決まりごととして,フィールド(項目)がコンマや改行やダブルクォート(")を含めば,フィールド全体をダブルクォートで囲む。その際,内側のダブルクォートは "" のように二重にする。この決まりごとはExcelやRにも実装されている。もっとも,コンマやダブルクォートを多く含むデータはCSVではなくTSV(Tab-Separated Values,タブ区切りテキスト)形式で公開するほうがよいかもしれない。
Excelで作ったCSVには,よくわからない理由で余分な行や列が入ってしまうことがある。必ず最終的なCSVファイルをテキストエディタでチェックするべきである。
CSVの編集には,Excelなどの表計算ソフトのほか,EmacsのCsv Modeも便利である。CSVのコメント(デフォルトでは「#」で始まる行)も正しく扱える。C-c C-a(csv-align-fields)でCSVの列を揃えた表示になり,C-c C-u(csv-unalign-fields)で元に戻る。フィールド中の改行や2重ダブルクォートにはうまく対応していない。
CSV形式の欠点は,データに型が指定できないことである。特にExcelでダブルクリックで開く場合にこの欠点が顕在化し,例えば "001" は数値 1 に,"1-2-3" は日付 2001/2/3 に,"1E3" は指数表示の数 1.00E+03 に,STAP細胞で有名になった遺伝子名 "Oct4" は日付 4-Oct になる(これらはExcelに手入力した場合と同じ振舞いである)。遺伝子関係の論文の2割くらいがこの罠に引っかかっているそうである(Gene name errors are widespread in the scientific literature,Autocorrect errors in Excel still creating genomics headache)。対策としては,拡張子をtxtに変えてExcelの「開く」メニューで開き,ウィザードで各列の「データ形式」を「文字列」に指定する。あるいは ="001" のように ="…" で囲むという奥の手もある。
[2018-08-11] Excelで遺伝子はOct4に限らずFeb,Mar,Apr,Jun,Aug,Sep,Oct,Nov,Decが危ないとのこと。あと化学のCASナンバーや,住所の「番地」でも問題が生じ得る。電話番号やクレジットカード番号は数値と解釈されて先頭の0が落ちたり16桁を超えると右の桁が0になったりする。
[追記] 2020年: 「Excelのおせっかい」のせいで人間の遺伝子の名前が変更を余儀なくされる “all symbols that autoconverted to dates in Microsoft Excel have been changed (for example, SEPT1 is now SEPTIN1; MARCH1 is now MARCHF1)” (Guidelines for human gene nomenclature)
CSV形式で,文字コードや,ヘッダ行の有無を指定するには,MIMEタイプを使うことになっている:
text/csv; charset=UTF-8; header=present
text/csv; charset=Shift_JIS; header=absent
RでURL指定で試してみたが,charsetもheaderも見ていないようである。
[2019-02-03] 上述のように,ExcelでCSVファイルを編集すると,0123 が 123 に,(1) が -1 に,1-2-3 が 2001/2/3 に,123456789012 が 1.23457E+11 に,Oct-4 が 4-Oct になり,危険である。私は Emacs の CSV モードを使って編集することがよくあるが,有料であるが「EmEditor Professional」が便利そうである(「Excel」でCSV編集はNG? 脱エクセルを実現する「EmEditor」の実力を徹底検証)。別の方法として,Twitterでご指摘いただいたが(このページの上のほうにも書いてあったが)拡張子を「.txt」に変えてExcelの「開く」メニューから開き,ダイヤログで区切り文字を指定し,すべての列を選択して「文字列」として読み込む方法がある。データ入力の際にもすべてのセルを選択し「文字列」にすれば余計な解釈をされない。
[2019-02-04] 秀丸にもCSVモードがあるらしい。
流山市オープンデータトライアル[現在はリンク切れ]から年齢別・男女別人口[現在はリンク切れ]の平成24年4月1日現在のものを取り上げる。
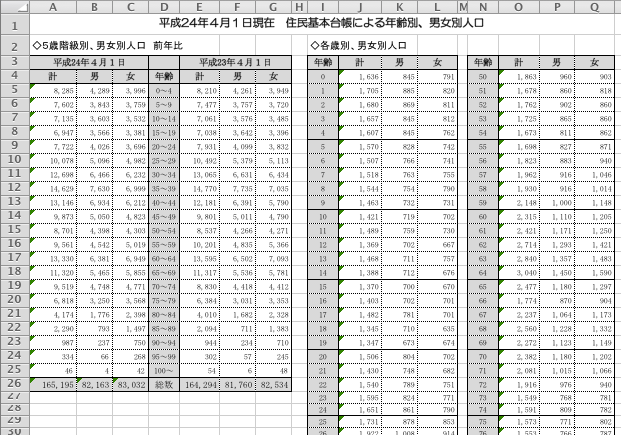
紙への印刷を考えて途中で列を分けている。このままでは機械処理が難しい。一つにつなげて,簡単に計算できるものを省くと,次のようになる。
# 流山市の年齢・男女別人口(平成24年4月1日)
# Population of Nagareyama City as of April 1, 2012.
# 年齢,男,女
Age,Male,Female
0,845,791
1,885,820
2,869,811
3,845,812
……
99,5,23
100,4,42
# 最後の行は100歳以上
# Last row: 100 or older.
最後の行は「100〜」であったが,これでは文字列になってしまうので,「100」に変えて,注釈を入れた。
このCSVファイルから人口ピラミッドを描くには,Rで(あらかじめpyramidパッケージをインストールしておき)次のように打ち込む(CP932 はSJISのWindows拡張):
library(pyramid)
data = read.csv("https://okumuralab.org/~okumura/stat/h24nenreibetsudanjobetsu.csv",
fileEncoding="CP932", comment.char="#")
pyramids(data$Male, data$Female, data$Age, Cstep=10)
ところで,こういう毎年更新されるデータを提供するには,例えば https://example.jp/nagareyama/population/by_age/2012.csv のようにURLで年が指定できれば,年を入力すればその年の人口ピラミッドを描くアプリケーションが作りやすくなる。動的に生成する場合も,例えば ...data?city=nagareyama&year=2012 のように引数を渡せばよい。年の代わりに new のような文字列を与えれば最新のデータにリダイレクトされるのもいいかもしれない。毎年予測不可能なURLで新データを提供するシステムが多いのは困ったものである(それ以前に古いデータのURLもしょっちゅう変わることがある)。
東電は福島原発事故に伴う電力不足からでんき予報を提供しているが,このCSVデータも提供し,他サイトやスマホのアプリでも逼迫状況がわかるようにしている。今日に至るまで同じURLで提供を続けているのはすばらしいことである。
このCSVもどきのフォーマットは,最初は次のようであった:
2011/5/18 15:30 UPDATE
ピーク時供給力(万kW),時台,供給力情報更新日,供給力情報更新時刻
4450,14:00,5/18,8:30
予想最大電力(万kW),時間帯,予想最大電力情報更新日,予想最大電力情報更新時刻
3400,14:00~15:00,5/18,1:05
DATE,TIME,当日実績(万kW),前日実績(万kW)
2011/5/18,0:00,2652,2656
2011/5/18,1:00,2532,2527
2011/5/18,2:00,2498,2482
2011/5/18,3:00,2473,2456
…
ところが,2011年7月1日から予告なく次のような形式に変わった:
2011/8/16 13:00 UPDATE
ピーク時供給力(万kW),時間帯,供給力情報更新日,供給力情報更新時刻
5530,9:00~20:00,8/16,8:30
予想最大電力(万kW),時間帯,予想最大電力情報更新日,予想最大電力情報更新時刻
4340,14:00~15:00,8/16,8:30
DATE,TIME,当日実績(万kW),予測値(万kW)
2011/8/16,0:00,3076,0
2011/8/16,1:00,2831,0
2011/8/16,2:00,2684,0
2011/8/16,3:00,2607,0
…
つまり,「前日実績(万kW)」欄が突然「予測値(万kW)」に変わった(この開き括弧が全角,閉じ括弧が半角という変な書き方は現在もそのままであるが,下手に変えないほうがよい)。
このおかげで,このデータを利用するサイトやアプリは大混乱した(東電のCSV形式が突然変更された)。
オープンデータを提供するCSVファイルの形式はできるだけ変えず,もし変えるなら周知が必要である。
[2022-03-23追記] 東日本大震災から11年を経た2022-03-16の夜,再び宮城県や福島県で最大震度6強の揺れを観測する地震が起きた。東電の火力発電所が停止し,電力が逼迫した。東電のでんき予報ページのCSVデータダウンロードのファイル名は juyo-d-j.csv に変わっており,ファイル内容も若干変わっている。従来と同じ名前の juyo-j.csv もリンクはされていないが提供が続いており,こちらのほうが2011-07-01の型式に近い。
2013年3月22日に福島第一原発事故初期の新たなデータが公表された(→事故初期の可搬型モニタリングポストについて[現在はリンク切れ]の可搬型モニタリングポスト未公表データ一覧表について(PDF形式 638KB)[現在はリンク切れ])。PDF形式であるだけでなく,たとえExcel形式でも機械的な処理が難しい並べ方になってしまっている。
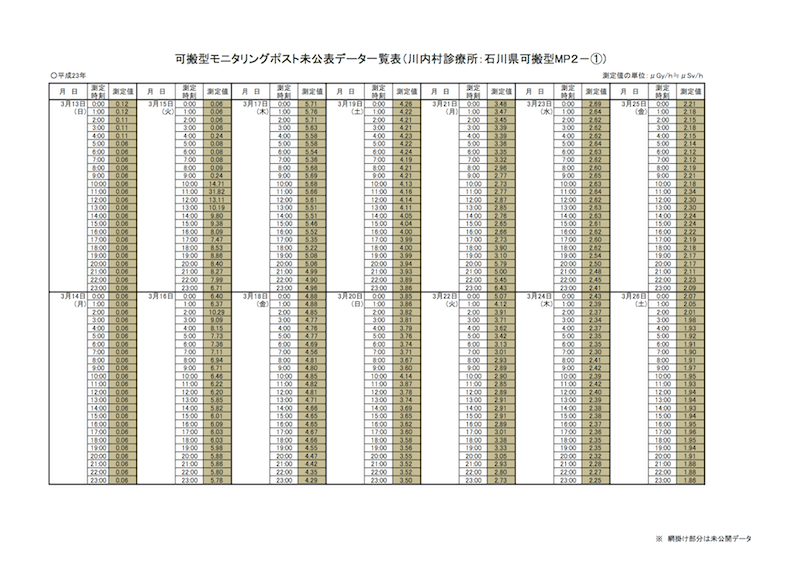
縦に長くなって印刷しにくいのでこのようにしたのであろうが,グラフを描くためには縦に並べるしかない。
DateTime,uGy/h
2011-03-13 00:00,0.12
2011-03-13 01:00,0.12
2011-03-13 02:00,0.11
2011-03-13 03:00,0.11
2011-03-13 04:00,0.11
2011-03-13 05:00,0.06
...
このような形にしたKawauchiMP2.csvを置いておく。これで次のようなグラフを描くのは簡単になる。
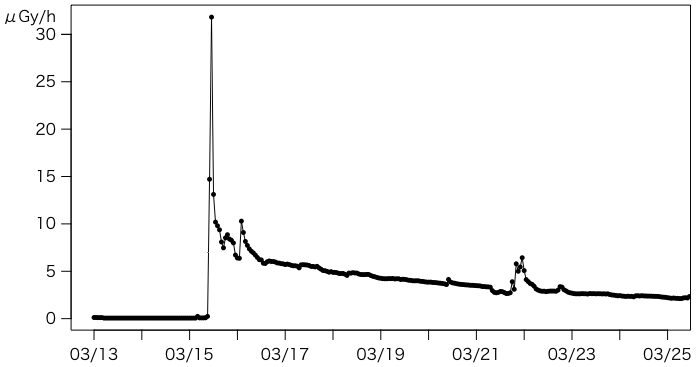
元のPDFは,未公開だった部分を背景色で示している(川内村診療所MP2はすべて未公開)。未公開分と既公開分を区別するのであれば,列を一つ余分に作って,そこに「既公開」「未公開」(または「0」「1」)と入れればよい。
追加CSV:川内村県道小野・富岡線割山トンネル出口MP3,川内村役場MP1
2011年の大震災・原発事故関連データの混迷を機として以上の議論を始めたが,2020年のCOVID-19(いわゆる新型コロナ)でも相変わらずデータの混迷が生じてしまっている。患者情報はFAXでやりとりされ,お役所はデータをまとめきれず,公開データはまだまだPDF形式が多く,自動処理の妨げになっている。PDFはデータ化しにくいだけでなく,環境によってはこちらの「「埼玉」と「埼⽟」」の項目に書いたようなコード点化けが生じることも問題である。
一方,自動処理のためのデータ形式はますますCSVやJSONに向かい,文字コードはもはやUTF-8以外は考えられなくなってきた。Windowsの「メモ帳」のデフォルトもBOMなしUTF-8になった。ExcelはBOM付きUTF-8のCSVを読み書きできるようになった(BOMなしCSVを開くと化けるのは何とかしてほしい)。
2020年8月16日からは,oku.edu.mie-u.ac.jpとokumuralab.orgの/etc/httpd/conf/httpd.confの <Directory /> と </Directory> の間に Header set Access-Control-Allow-Origin '*' を追記した。こうすることで他サイトのコンテンツ中のJavaScriptから当サイトのデータを自由に利用できるようになる。あるいは,公開データを入れたディレクトリに .htaccess を置き Header append Access-Control-Allow-Origin '*' と書いておくだけでもよい。GitHub(GitHub Pagesも含めて)ではサイト全体にわたってこのような設定になっているので,公開したいデータはGitHubに置くのでもよい。
再利用しやすいデータについては tidy data(整然データ)という呼称が広まった。The American Statistician の Special Issue on Data Science に含まれる Data Organization in Spreadsheets も参考になる。