今のところXLConnectパッケージが制約や問題点が少ないようである。
openxlsxパッケージについて追記した。xlsxに限ればこれがお薦めである(ただし注意点あり)。
Hadley Wickhamのreadxlパッケージについて書き足した。爆速かつ完璧。
xlsxパッケージはxls/xlsxファイルを読み書きするためのものである。Javaで書かれたApache POIを使っている。インストールはMacでも簡単に行えた(昨今のセキュリティ事情からJavaをアンインストールした人は使えない)。
ワークシートをデータフレームとして読み込む関数は
read.xlsx()
と
read.xlsx2()
である。どちらもファイル名とシート番号(1から始まる)を引数とする:
data = read.xlsx("test.xls", 1) # または read.xlsx2("test.xls", 1)
いろいろなオプションが指定できるので,ヘルプを参照されたい。Windowsの日本語環境では encoding="UTF-8" のオプションが必要のようである。
ヘルプによれば,read.xlsx() より read.xlsx2()
のほうがJava依存度が高く,行方向に大きいデータでは1桁高速とのことである。
デフォルト(header=TRUE)では1行目が列の名前になる。read.xlsx() は,それ以降の最初の空でない要素から各列のデータ型を判断する。read.xlsx2() はすべて文字列として読む。いずれも,colClasses で各列の型を指定することができる。
いずれもデフォルトでは文字列を因子(factor)に変換する。特に read.xlsx2()
はすべて文字列として読むので,数値も因子になる。これを避けるには
data = read.xlsx2("test.xls", 1, stringsAsFactors=FALSE)
のようなオプションを使うか,あらかじめ
options(stringsAsFactors=FALSE)
と打ち込んでおくのがよい。
下の「いろいろな方法の比較」を見れば,いろいろおもしろいことがわかる。日時については,read.xlsx()
は日時として扱っているのに read.xlsx2()
では内部表現の数値の文字列になってしまっている。また,セルA4には 2013-02-01 23:45:01
と入力したのに read.xlsx()
で 2013-02-01 23:45:00 になってしまっている。12:34:56 のような時刻だけの場合は 1899-12-30
という日付が付く。これらの理由はExcelの日時の内部形式にある。
Excelの日時の内部表現は,1900年1月1日を第1日(第0日ではない)とした数値である。つまり,数値0はこの前日の1900年1月0日(つまり1899年12月31日)に対応する。もっとも,これは1900年を閏年とした場合(間違いだが古いLotus 1-2-3との互換性のためExcelではこうしている)の値で,1900年を閏年としない正しい計算では数値0は1899年12月30日に対応する。また,昔のMac版Excelでは数値0は1904年1月1日に対応したが,現在はWindows版と同じ方式がデフォルトで,環境設定の「計算方法」で起点を1904年に変更できる。
この内部表現は浮動小数点数で,小数部は時刻を表す。数値0.5は,一般的な正午12:00を表す場合と,Excelの1900年1月0日(正しくは1899年12月30日)の正午を表す場合がある。
Excelはタイムゾーンも夏時間も扱えない。
read.xlsx2() ではこの内部表現の数値をそのまま文字列として返す。ヘルプには,これを日時に直すには as.POSIXct((x-25569)*86400, tz="GMT", origin="1970-01-01")
または日付なら as.Date(x-25569, origin="1970-01-01")
とすればよいと書かれている。read.xlsx()
ではそのような変換をしている。しかしこれはまずい。実際,下の「いろいろな方法の比較」の例でセルA4に入れた 2013-02-01 23:45:01
は1秒ずれて 2013-02-01 23:45:00 になっている。理由は,この日時の (x-25569)*86400
は 1359762300.999… となり,as.POSIXct()
は小数部分を切り捨てるためである。秒単位の表示をするためには
as.POSIXct(round((x-25569)*86400), origin="1970-01-01")
とすべきである(Excelに入れた日時が現地時間であるとすれば tz="GMT"
もまずい)。
gdataパッケージはGregory Warnes(geneticsパッケージの作者)によるデータハンドリングのためのツール集である。この中に,Perlを使ってxls/xlsxファイルを読む read.xls() などの関数がある。MacやLinuxでは簡単に使えるが,Windowsではここを見てPerlのインストールから始めなければならない。Windowsの日本語環境では read.xls() に fileEncoding="UTF-8" のオプションが必要のようである。
ここで使われているPerlスクリプトは,Macなら例えば
~/Library/R/2.15/library/gdata/perl/
のようなディレクトリに収められている。この中の xls2csv.pl
がxls/xlsxをcsvに変換する。使い方は
xls2csv.pl [-s] Excelファイル名 [出力ファイル名] [ワークシート番号]
である。オプション -s で空白行を無視しない。出力ファイル名やシート番号を略せば
ベース名.csv
または
ベース名_シート名.csv
になる。
このスクリプトでは,Excelのシートに表示される通りの値に丸められてしまうので,例えば6.022e23を入れても6.02e23になってしまうという問題がある(下の「いろいろな方法の比較」参照)。
XLConnectもApache POIベースで,Javaに依存する。xls/xlsxともに読み書きできる。Macのバイナリは用意されていないので,以下のようにしてソースからインストールする(ご指摘感謝!):
install.packages("XLConnect", type="source") # Mac
R 3.0.0ではMacでも普通にバイナリインストールできた。
MacのGUIでも「CRAN(ソース)」を選択すればインストールできるとのことである。githubからもインストールできる。
たいへん大きなパッケージであるが,シートごとに読むのであれば次のようにファイル名とシート番号(またはシート名)を指定すればデータフレームの形で取得できる:
data = readWorksheetFromFile("test.xls", 1) # xlsxも同様
結果はxls/xlsxともに完璧である。なお,他のパッケージと違って,日時の変換はExcelに合わせて1900年を閏年とするバグを温存している。したがって,数値0には1899-12-31が対応する。
より一般的には,例えば次のようにする。デフォルトでは1行目に列名が並んでいると仮定するが,そうでない場合は header=FALSE オプションが必要。
wb = loadWorkbook("test.xlsx")
sh = getSheets(wb) # シート名の配列を得る
for (s in sh) {
data = readWorksheet(wb, s, header=FALSE)
# ...
}
ほかにも多数のオプションがある。ヘルプ参照。
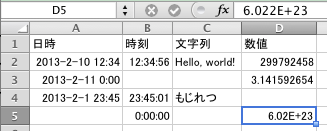
例として,MacのExcel 2011で次のように入力し,xlsおよびxlsx形式で保存する。
ここでは手で打ち込んだが,次のCSVファイルを読み込んでも同じことである:
日時,時刻,文字列,数値
2013-02-10 12:34:56,12:34:56,"Hello, world!",299792458
2013-02-11 00:00:00,,,3.14159265358979
2013-02-01 23:45:01,23:45:01,もじれつ,
,00:00:00,,6.022e23
セルD5には 6.022e23 と入力したが,「数値」と判断され,セル内では
6.02E+23 に見える(上の fx の右には 6.022E+23
と表示されているので内部では正しく扱われている)。セルの書式設定で「標準」に直せばセル内も 6.022E+23 になる。
また,A列は「日付」→「2001-3-14 13:30」の形式,B列には「時刻」→「13:30:55」の形式を設定し,セルA2には
2013-2-10 12:34:56
と入力したが,セル内では 2013-2-10 12:34 までしか表示されない(上の fx の右には :56
まで表示される)。セルA4も 2013-2-1 23:45:01 と入力したが分までしか表示されない。
これをExcelからCSVまたはHTMLで保存したらどうなるか。結果は,日付は分までしか出力されず,6.022e23と入れたセルも6.02E+23になってしまう。Excelを入力ツールとして使う際に注意しなければならない点である。
ちなみにxlsxファイルの中身はXMLで,CSVで表すと次のような文字列が収められている:
日時,時刻,文字列,数値
41315.524259259262,0.52425925925925931,"Hello, world!",299792458
41316,,,3.14159265358979
41306.989594907405,0.98959490740740741,もじれつ,
,0,,6.0220000000000003E+23
Rのxlsxパッケージの read.xlsx() でxls/xlsxファイルを処理した例を示す。上に書いたように,「日時」の列の最後の 23:45:00 は間違いである。
> read.xlsx("test.xls", 1)
日時 時刻 文字列 数値
1 2013-02-10 12:34:56 1899-12-30 12:34:56 Hello, world! 2.997925e+08
2 2013-02-11 00:00:00 <NA> <NA> 3.141593e+00
3 2013-02-01 23:45:00 1899-12-30 23:45:01 もじれつ NA
4 <NA> 1899-12-30 00:00:00 <NA> 6.022000e+23
> read.xlsx("test.xlsx", 1)
日時 時刻 文字列 数値
1 2013-02-10 12:34:56 1899-12-30 12:34:56 Hello, world! 2.997925e+08
2 2013-02-11 00:00:00 <NA> <NA> 3.141593e+00
3 2013-02-01 23:45:00 1899-12-30 23:45:01 もじれつ NA
4 <NA> 1899-12-30 00:00:00 <NA> 6.022000e+23
同じファイルに対して,read.xlsx2() では次のようになる。NAは空文字列になっている。
> read.xlsx2("test.xls", 1, stringsAsFactors=FALSE)
日時 時刻 文字列 数値
1 41315.52425925926 0.5242592592592593 Hello, world! 2.99792458E8
2 41316.0 3.14159265358979
3 41306.989594907405 0.9895949074074074 もじれつ
4 0.0 6.022E23
> read.xlsx2("test.xlsx", 1, stringsAsFactors=FALSE)
日時 時刻 文字列 数値
1 41315.52425925926 0.5242592592592593 Hello, world! 2.99792458E8
2 41316.0 3.14159265358979
3 41306.989594907405 0.9895949074074074 もじれつ
4 0.0 6.022E23
次に,Rのgdataパッケージの read.xls()
でxls/xlsxファイルを処理した例を示す。上にも書いたように,「数値」の列の最後の 6.02e+23
は間違いである。
> read.xls("test.xls", 1)
Wide character in print at /Users/okumura/Library/R/2.15/library/gdata/perl/xls2csv.pl line 270.
Wide character in print at /Users/okumura/Library/R/2.15/library/gdata/perl/xls2csv.pl line 270.
日時 時刻 文字列 数値
1 2013/2/10 12:34 12:34:56 Hello, world! 2.997925e+08
2 2013/2/11 0:00 3.141593e+00
3 2013/2/1 23:45 23:45:01 もじれつ NA
4 0:00:00 6.020000e+23
> read.xls("test.xlsx", 1)
日時ニチジ 時刻ジコク 文字列モジレツ 数値スウチ
1 2013/2/10 12:34 12:34:56 Hello, world! 2.997925e+08
2 2013/2/11 0:00 3.141593e+00
3 2013/2/1 23:45 23:45:01 もじれつ NA
4 0:00:00 6.022000e+23
最後に,RのXLConnectパッケージの readWorksheetFromFile()
でxls/xlsxファイルを処理した例を示す。他のパッケージで1899-12-30となるところが1899-12-31となっていることに注意する。
> readWorksheetFromFile("test.xls", 1)
日時 時刻 文字列 数値
1 2013-02-10 12:34:56 1899-12-31 12:34:56 Hello, world! 2.997925e+08
2 2013-02-11 00:00:00 <NA> <NA> 3.141593e+00
3 2013-02-01 23:45:01 1899-12-31 23:45:01 もじれつ NA
4 <NA> 1899-12-31 00:00:00 <NA> 6.022000e+23
> readWorksheetFromFile("test.xlsx", 1)
日時 時刻 文字列 数値
1 2013-02-10 12:34:56 1899-12-31 12:34:56 Hello, world! 2.997925e+08
2 2013-02-11 00:00:00 <NA> <NA> 3.141593e+00
3 2013-02-01 23:45:01 1899-12-31 23:45:01 もじれつ NA
4 <NA> 1899-12-31 00:00:00 <NA> 6.022000e+23
比較のため,RではなくRubyであるが,Rubyによるデータ処理のspreadsheetライブラリの例で*.xlsを処理すると次のようになる(それぞれ
puts row.join(',') および puts CSV.generate_line(row) の出力):
日時,時刻,文字列,数値
41315.5242592593,0.524259259259259,Hello, world!,299792458
41316.0,,,3.14159265358979
41306.9895949074,0.989594907407407,もじれつ
,0.0,,6.022e+23
日時,時刻,文字列,数値
2013-02-10T12:34:56+00:00,1899-12-30T12:34:56+00:00,"Hello, world!",299792458
2013-02-11T00:00:00+00:00,,,3.14159265358979
2013-02-01T23:45:01+00:00,1899-12-30T23:45:01+00:00,もじれつ
,1899-12-30T00:00:00+00:00,,6.022e+23
また,*.xlsxについて,同ページのrooライブラリの例では次のようになる(それぞれ
puts row.join(',') および sheet.to_csv の出力):
日時,時刻,文字列,数値
2013-02-10T12:34:56+00:00,45296.00000000001,Hello, world!,299792458.0
2013-02-11,,,3.14159265358979
2013-02-01T23:45:00+00:00,85501.0,もじれつ,
,0.0,,6.022e+23
"日時","時刻","文字列","数値"
2013-02-10T12:34:56+00:00,12:34:56,"Hello, world!",299792458
2013-02-11,,,3.14159265358979
2013-02-01T23:45:00+00:00,23:45:01,"もじれつ",
,00:00:00,,602200000000000027262976
さらに比較のため,Pythonで書かれた
dilshod/xlsx2csv
を使ってみる(sudo pip3 install xlsx2csv しておく)。時刻が分単位に切り捨てられてしまう:
日時,時刻,文字列,数値
2013/02/10 12:34,12:34,"Hello, world!",299792458
2013/02/11 00:00,,,3.14159265358979
2013/02/ 1 23:45,23:45,もじれつ,
,00:00,,602200000000000027262976
openxlsx はJavaに依存せずxlsxファイルの読み書きができるパッケージである(Javaに依存せずにxlsxを読む - 東京で尻を洗う参照)。
以下のように簡単かつ高速に処理できる。ただし,日時の内部形式を文字列に直す convertToDateTime() は空セル(NA)があるとエラーになる。また,時刻の内部形式を文字列に直す関数がないので convertToDateTime() を流用することになる(不要な 1899-12-30 が付いてしまう)。
> install.packages("openxlsx")
> library(openxlsx)
> data = read.xlsx("test.xlsx")
> data
日時 時刻 文字列 数値
1 41315.52 0.5242593 Hello, world! 2.997925e+08
2 41316.00 NA <NA> 3.141593e+00
3 41306.99 0.9895949 もじれつ NA
4 NA 0.0000000 <NA> 6.022000e+23
> convertToDate(data$日時)
[1] "2013-02-10" "2013-02-11" "2013-02-01" NA
> convertToDateTime(data$日時)
以下にエラー as.POSIXlt.character(x, tz, ...) :
character string is not in a standard unambiguous format
> convertToDateTime(data$日時[1:3])
[1] "2013-02-10 12:34:56 JST" "2013-02-11 00:00:00 JST"
[3] "2013-02-01 23:45:00 JST"
> convertToDateTime(data$時刻[c(1,3:4)])
[1] "1899-12-30 12:34:56 JCST" "1899-12-30 23:45:01 JCST"
[3] "1899-12-30 00:00:00 JCST"
追記:Windowsではinvalid multibyte errorとなり使えないという情報をいただいた。
[2015-12-06] 追記:Rで解析:セル体裁!大きなデータも大丈夫!エクセル操作の「openxlsx」パッケージ
Hadley Wickhamの新しい readxl(開発版は hadley/readxl)を試してみた。爆速という評判。最初はちょっとおかしかったが,バグ報告したおかげで直してもらえた。結果は完璧:
> install.packages("readxl")
> # install.packages("devtools") # 開発版の場合
> # devtools::install_github("hadley/readxl") # 開発版の場合
> library(readxl)
> data1 = read_excel("test.xls")
> data1
日時 時刻 文字列 数値
1 2013-02-10 12:34:56 1899-12-30 12:34:56 Hello, world! 2.997925e+08
2 2013-02-11 00:00:00 <NA> <NA> 3.141593e+00
3 2013-02-01 23:45:00 1899-12-30 23:45:01 もじれつ NA
4 <NA> 1899-12-30 00:00:00 <NA> 6.022000e+23
> data2 = read_excel("test.xlsx")
> data2
日時 時刻 文字列 数値
1 2013-02-10 12:34:56 1899-12-30 12:34:56 Hello, world! 2.997925e+08
2 2013-02-11 00:00:00 <NA> <NA> 3.141593e+00
3 2013-02-01 23:45:00 1899-12-30 23:45:01 もじれつ NA
4 <NA> 1899-12-30 00:00:00 <NA> 6.022000e+23
カレントディレクトリに大量のExcelファイルがあって,それを集計したいとする。ファイルは次のような形式で1行だけ(あるいは複数行)のデータが入っているとする。
| 品名 | 値段 |
|---|---|
| りんご | 298 |
これらを全部縦につないで一つの大きなデータフレームにしたい。ただし1行目は烈名であるので一つあれば十分である。
上で解説した readxl パッケージの read_excel() 関数を使えば次のようにできる:
names = dir(pattern="*.xlsx")
alldata = do.call(rbind, lapply(names, read_excel))