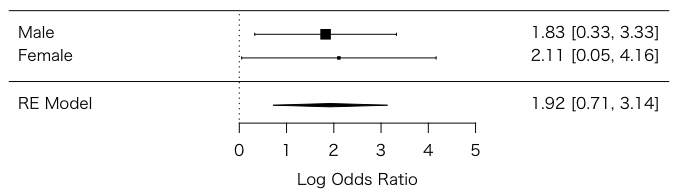
メタアナリシスのように考えることもできる:
library(metafor)
y = matrix(as.numeric(x), ncol=4, byrow=TRUE)
dat = escalc(measure="OR", ai=y[,1], bi=y[,2], ci=y[,3], di=y[,4])
res = rma(yi, vi, data=dat)
forest(res, slab=c("Male","Female"))
豪華客船タイタニック号は,1912年,イギリスからアメリカに向かう処女航海で,氷山に衝突し,沈没した。詳しくは,ウィキペディアのタイタニック号沈没事故や,Encyclopedia Titanica を参照されたい。
タイタニック号の生存統計(諸説あるがそのうちの一つ)がRの Titanic というデータセットに収められている。このデータ構造を str() 関数で調べてみよう:
str(Titanic)'table' num [1:4, 1:2, 1:2, 1:2] 0 0 35 0 0 0 17 0 118 154 ...- attr(*, "dimnames")=List of 4..$ Class : chr [1:4] "1st" "2nd" "3rd" "Crew"..$ Sex : chr [1:2] "Male" "Female"..$ Age : chr [1:2] "Child" "Adult"..$ Survived: chr [1:2] "No" "Yes"
これからわかるように,Titanic は4個の添字を持つ人数の表($4 \times 2 \times 2 \times 2$ の表)で,各添字は,乗客クラス(ファーストクラス,セカンドクラス,サードクラス,乗組員),性別(男,女),年齢(子ども,大人),生存(No,Yes)を表す。
sum(Titanic)# 全員[1] 2201sum(Titanic[,,,"Yes"])# 生存者[1] 711sum(Titanic[,,,"No"])# 死亡者[1] 1490
これと同じことは margin.table() 関数でもできる:
margin.table(Titanic)[1] 2201margin.table(Titanic, 4)SurvivedNo Yes1490 711
margin.table() は次のようなこともできる:
margin.table(Titanic, c(2,4))SurvivedSex No YesMale 1364 367Female 126 344margin.table(Titanic, c(2,4,1)), , Class = 1stSurvivedSex No YesMale 118 62Female 4 141, , Class = 2ndSurvivedSex No YesMale 154 25Female 13 93, , Class = 3rdSurvivedSex No YesMale 422 88Female 106 90, , Class = CrewSurvivedSex No YesMale 670 192Female 3 20
これを見れば,全体として,男性の多くが死に,女性の多くは助かったことがわかる。しかし,サードクラスでは女性も死者のほうが多い。
男と比べた女の生存者の多さは,例えばオッズ比(odds ratio)という指標で表せる(2×2の表,オッズ比,相対危険度 参照)。オッズ比を計算する関数はいろいろなパッケージで定義されているが,自前で作っても,次のように1行でできる:
oddsratio = function(x) (x[2,2]/x[2,1])/(x[1,2]/x[1,1])
これを使えば,全体のオッズ比は
oddsratio(margin.table(Titanic, c(2,4)))[1] 10.14697
乗客クラスごとのオッズ比は
for (i in 1:4) cat(i, oddsratio(margin.table(Titanic, c(2,4,1))[,,i]), "\n")1 67.088712 44.067693 4.0716124 23.26389
またはもっとRらしく
apply(margin.table(Titanic, c(2,4,1)), 3, oddsratio)1st 2nd 3rd Crew67.088710 44.067692 4.071612 23.263889
つまり,ファーストクラスでは紳士的に女性の生存が優先されたが,クラスが下がるにつれその傾向が減っていることがわかる。
個数を表す $2 \times 2$ の表,あるいは一般に $I \times J$ の表で,行と列の独立性を調べるには,カイ2乗検定またはFisherの正確検定を使う。例えばタイタニック号での生存が性別によらないという帰無仮説を検定するには,次のようにすればよい:
chisq.test(margin.table(Titanic, c(2,4)))Pearson's Chi-squared test with Yates' continuity correctiondata: margin.table(Titanic, c(2, 4))X-squared = 454.5, df = 1, p-value < 2.2e-16
あるいは
fisher.test(margin.table(Titanic, c(2,4)))Fisher's Exact Test for Count Datadata: margin.table(Titanic, c(2, 4))p-value < 2.2e-16alternative hypothesis: true odds ratio is not equal to 195 percent confidence interval:7.97665 12.92916sample estimates:odds ratio10.1319
このオッズ比が oddsratio(margin.table(Titanic, c(2,4))) の結果 10.14697 と若干異なるのは,Fisherの正確検定に書いた(conditional MLE あたり)。
しかし,生存と性別の関係は乗客クラスに依存するので,乗客クラスを無視した解析は正しくない。正しくは,乗客クラスごとに調べた結果を(重み付き)平均しなければならない。
添字が3個ある($2 \times 2 \times K$ の)人数のデータを $n_{ijk}$ とする。一つの添字について合計した値を例えば $n_{i.k} = \sum_j n_{ijk}$ のように表す。このとき,
\[ \frac{(\sum_k (n_{11k} - \mu_{11k}))^2}{\sum_k \mathrm{var}(n_{11k})} \]は自由度1のカイ2乗分布に従う。ここで
\[ \mu_{11k} = n_{1.k} n_{.1k} / n_{..k} \]である。分散 $\mathrm{var}(n_{11k})$ は
\[ \mathrm{var}(n_{11k}) = n_{1.k} n_{2.k} n_{.1k} n_{.2k} / (n_{..k}^2 (n_{..k} - 1)) \]で推定できる(Mantel and Haenszel, 1959)。これに先立って Cochran (1954) も同様の提案をしているが,$\mathrm{var}(n_{11k})$ の分母を $n_{..k}^3$ としている。この類の検定を (Cochran-)Mantel-Haenszel((コクラン・)マンテル・ヘンツェル)検定という。
Rには標準で mantelhaen.test() という関数が備わっている。これは $2 \times 2 \times K$ の表に対して,(デフォルトでは連続性の補正をした)Mantel-Haenszel 検定を行う:
mantelhaen.test(margin.table(Titanic, c(2,4,1)))Mantel-Haenszel chi-squared test with continuity correctiondata: margin.table(Titanic, c(2, 4, 1))Mantel-Haenszel X-squared = 360.33, df = 1, p-value < 2.2e-16alternative hypothesis: true common odds ratio is not equal to 195 percent confidence interval:8.232629 14.185153sample estimates:common odds ratio10.80653
このデータについては,Mantel-Haenszel で求めた common odds ratio 10.80653 は,oddsratio(margin.table(Titanic, c(2,4))) で求めた 10.14697 とあまり違わない。どんな場合にもそうであろうか,というのが次節の話題である。
ちなみに,mantelhaen.test() はオプション exact=TRUE でFisherの正確検定に対応する厳密な方法を行う。この場合,common odds ratio も conditional MLE になる。
次のようなコマンドで作られる $2 \times 2 \times 2$ の表を考えよう。
x = array(c(21, 2,71,42,
18,70, 1,32),
dim=c(2,2,2),
dimnames=list(Treatment=c("Treated","Untreated"),
Survival=c("Alive","Dead"),
Sex=c("Male","Female")))
これは,男女について,ある治療をした結果を表す:
x, , Sex = MaleSurvivalTreatment Alive DeadTreated 21 71Untreated 2 42, , Sex = FemaleSurvivalTreatment Alive DeadTreated 18 1Untreated 70 32
男女をまとめて1つの表にしてしまおう:
y = margin.table(x, c(1,2))ySurvivalTreatment Alive DeadTreated 39 72Untreated 72 74oddsratio(y)[1] 0.556713
これを見ると,治療しなければ生死はほぼ等しいのに,治療したら死亡のほうが増えてしまうという,まずい治療の例のようである。Fisherの正確検定をしてみる:
fisher.test(y)Fisher's Exact Test for Count Datadata: yp-value = 0.03049alternative hypothesis: true odds ratio is not equal to 195 percent confidence interval:0.3242247 0.9524200sample estimates:odds ratio0.5579833
オッズ比が 1 であるという帰無仮説は棄却される($p = 0.03$)。
しかし,男女別にオッズ比を計算すれば,
apply(x, 3, oddsratio)
Male Female
6.211268 8.228571
どちらもオッズ比は 1 より大きく,治療したほうがよい。Mantel-Haenszel 検定は
mantelhaen.test(x)Mantel-Haenszel chi-squared test with continuity correctiondata: xMantel-Haenszel X-squared = 11.222, df = 1, p-value = 0.0008084alternative hypothesis: true common odds ratio is not equal to 195 percent confidence interval:2.062906 23.283520sample estimates:common odds ratio6.930492
となり,オッズ比はやはり 1 より大きい($p = 0.0008$)。
このように,層別に分けた結果と,分けない結果とでは,結果が逆になることがある(Simpsonのパラドックス)。この場合は層別の結果を使うべきである。
mantelhaen.test() の中を調べると,common odds ratio 6.930492 は次のようにして求めているようである(136,121はそれぞれ男女の総数):
(21*42/136 + 18*32/121) / (71*2/136 + 1*70/121)[1] 6.930492
メタアナリシスのように考えることもできる:
library(metafor)
y = matrix(as.numeric(x), ncol=4, byrow=TRUE)
dat = escalc(measure="OR", ai=y[,1], bi=y[,2], ci=y[,3], di=y[,4])
res = rma(yi, vi, data=dat)
forest(res, slab=c("Male","Female"))