伝統的な統計学では,$p \leq 0.05$ で帰無仮説を棄却(「有意」),そうでなければ帰無仮説を棄却しないといった二分法の考え方が支配的でした。その副作用として,例えばある薬がある病気に有用かどうか調べる研究がいくつか行われ,多くの研究が有意でない結果を出したとすると,「薬の効果はなさそうだ」あるいは「はっきりしない」という結論が出され,せっかくの有用な薬が広く利用されないといったことが起こり得ました。しかし,有意でない結果でも,いくつか合わせれば非常に有意な結果が導けるかもしれないのです。そのためには,「有意か有意でないか」の二分法をやめ,効果量(effect size)とその誤差(標準誤差または信頼区間)あるいはそれらを導くためのデータを報告することが必要になります。
Publication Manual of the American Psychological Association, Sixth Edition でも同様なことが強調されています(p.33):
Historically, researchers in psychology have relied heavily on null hypothesis statistical significance testing (NHST) as a starting point for many (but not all) of its analytic approaches. APA stresses that NHST is but a starting point and that additional reporting elements such as effect sizes, confidence intervals, and extensive description are needed to convey the most complete meaning of the results. The degree to which any journal emphasizes (or de-emphasizes) NHST is a decision of the indivisual editor. However, complete reporting of all tested hypotheses and estimates of appropriate effect sizes and confidence intervals are the minimum expectations for all APA journals. ...
信頼区間(confidence interval, CI)の報告は例えば d = 0.65, 95% CI [0.35, 0.95] や M = 3.05 cm, 99% CI [18.0, 43.0] のような形式で行うとされています(p. 117)。この2番目の例のように [ ] の中では単位は省略します。
例えばある量を測定したとき,研究1では 2.5(95%信頼区間 [-0.5, 5.5]),研究2では 3.5(95%信頼区間 [-0.5, 7.5])という結果が出たとします。帰無仮説が 0 であれば,0 はどちらの信頼区間にも含まれていますので,どちらも有意な結果ではありません。実際,正規分布を仮定すれば,研究1は p = 0.102,研究2は p = 0.086 程度です。
95%信頼区間の長さの比は 3 : 4 です。誤差分散の比は,ほぼ信頼区間の長さの2乗に比例しますから,9 : 16 です。メタアナリシス(固定効果モデル)では,この分散の逆数の比 1/9 : 1/16 を使って,二つの量を重み付けします。すると,結果は (1/9 * 2.5 + 1/16 * 3.5) / (1/9 + 1/16) = 2.86 です。この量の相対的な分散は 1 / (1/9 + 1/16) = 5.76 になります。$\sqrt{5.76} = 2.4$ ですから,95%信頼区間は [2.86-2.4, 2.86+2.4] つまり [0.46, 5.26] になります。これは p = 0.020 程度に相当します。
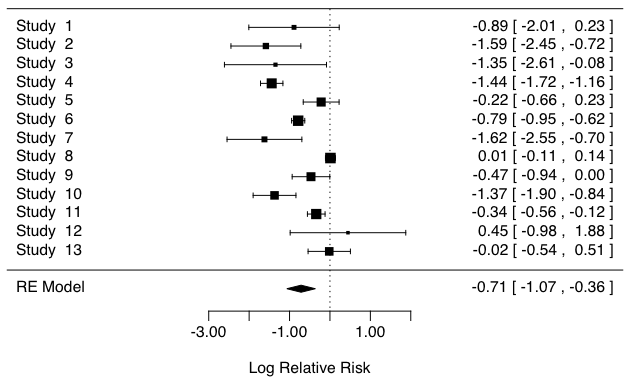
以上のことを図式的に描けば次のようになります。上の二つの横棒が,二つの研究の結果の信頼区間を表します。このような誤差(信頼区間)を表す棒をエラーバー(error bar)といいます。黒い正方形■は面積が重みに比例するように描いてあります。下の菱形がメタアナリシスの結果です。縦線が帰無仮説(効果量 = 0)を表しています。このような図をフォレストプロット(forest plot,森林プロット)といいます。
この図からも,上の二つの信頼区間は帰無仮説(効果量 = 0)を含み,有意でありませんが,これらを合成したものは帰無仮説を含まず,有意であることがわかります。もっとも,$p \leq 0.05$ かどうかで二分するという考え方自体が,効果量とその誤差に重きをおく考え方とは相容れないものですが。
このように,どの研究も同じ量を測定していると仮定する「固定効果モデル」(fixed-effect model)のメタアナリシス(meta-analysis)では,誤差分散の逆数で重み付けします。$X$ と $Y$ が独立なら $V(aX + bY) = a^2 V(X) + b^2 V(Y)$ ですから,$a + b = 1$ の条件下で,$a : b = \dfrac{1}{V(X)} : \dfrac{1}{V(Y)}$ のとき,重み付き和 $aX + bY$ の分散が最小値 $\dfrac{1}{\dfrac{1}{V(X)} + \dfrac{1}{V(Y)}}$ になります。研究の数が3以上でも同様です。
メタアナリシスには,研究ごとに少しずつ違う量を測定している(研究ごとに異なるランダムな系統誤差がある)と仮定する「ランダム効果モデル」(random-effects model)もあります。この場合は,誤差分散を統計誤差と系統誤差に振り分けなければならず,そのための方法がいろいろ提案されていますが,研究数が少ない場合には,安定した振り分けは困難です。ただ,固定効果モデルよりランダム効果モデルのほうが合成量の誤差が大きく出るので,安全側(有意な結果が出にくい)に立てば,ランダム効果モデルを使うべきだと言えます。
出版バイアス(publication bias,お蔵入り問題,file drawer problem)といって,有意な結果は出版されやすいけれども,そうでない結果は出版されずに,研究者のファイル入れに留まる傾向があります。つまり,出版された研究結果には偏りがあります。したがって,出版された結果だけを集めてメタアナリシスしても正しい結果は得られないという議論があります。ただ,出版されていない有意でない結果がたくさんあったとしても,それらを含めると有意でなくなるとは限りません。むしろ,さらに有意になる可能性もあります。
[TODO] 出版バイアスを避けるための方法(プレレジ,results-free reviewなど)をどこかに書く。
Rでメタアナリシスを行うパッケージには meta,rmeta,metafor などがあります(レビュー:CRAN Task View: Meta-Analysis)。ここではmetaforを解説します。詳細は metafor サイトやJSS論文 Conducting Meta-Analyses in R with the metafor Package を参照してください。
まずインストール:
install.packages("metafor")
ライブラリを読み込みます:
library(metafor)
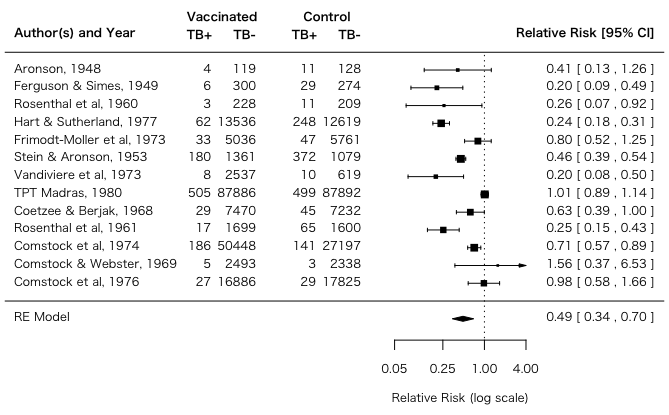
例題データ Studies on the Effectiveness of the BCG Vaccine Against Tuberculosis を読み込みます:
data(dat.bcg)
効果量(ES:effect size)を計算します。ここでは RR (log relative risk) を効果量とします:
dat = escalc(measure="RR", ai=tpos, bi=tneg, ci=cpos, di=cneg, data=dat.bcg)
これをもとにメタアナリシスを実行します。デフォルトはランダム効果モデルのREML(restricted maximum-likelihood estimator)です。たいていの教科書に最初に載っている DerSimonian-Laird にするには method="DL" を指定します。
res = rma(yi, vi, data=dat)
とりあえずフォレストプロットを描きます:
forest(res)
# 必要に応じてフォント名や軸とラベルの距離を指定:
# forest(res, family="Helvetica", mgp=c(2,0.6,0))
いろいろいじった結果(metafor論文より):
forest(res, slab=paste(dat$author,dat$year,sep=", "),
xlim=c(-16,6), at=log(c(0.05,0.25,1,4)), atransf=exp,
ilab=cbind(dat$tpos,dat$tneg,dat$cpos,dat$cneg),
ilab.xpos=c(-9.5,-8,-6,-4.5)+0.7, ilab.pos=c(2,2,2,2),
cex=0.75)
op = par(cex=0.75, font=2)
text(c(-9.5,-8,-6,-4.5), 15, c("TB+","TB-","TB+","TB-"))
text(c(-8.75,-5.25), 16, c("Vaccinated","Control"))
text(-16, 15, "Author(s) and Year", pos=4)
text(6, 15, "Relative Risk [95% CI]", pos=2)
par(op)
メタアナリシス全般については Michael Borenstein, Larry V. Hedges, Julian P. T. Higgins, Hannah R. Rothstein, Introduction to Meta-Analysis (Wiley, 2009) がよく読まれているようです(iBooks版やKindle版もありますが,例によってKindle版のほうが安いようです)。