これはPISAデータを読む,PISA 2015データを読むのPISA 2018年版(2019年12月3日公開)である。生徒のアンケート個票をRで読んで分析するのが目的である。
OECD の PISA (Programme for International Student Assessment) の2018年版データは PISA 2018 Database から得られる。例えば SPSS Data Files の Student questionnaire data file (494MB, ファイル名 SPSS_STU_QQQ.zip) をダウンロードして展開すると CY07_MSU_STU_QQQ.sav という1.8Gバイトほどのファイルになる。これをRで読むには次のようにする(かなり時間がかかる):
library(haven)data = read_sav("CY07_MSU_STU_QQQ.sav")object.size(data)# 約5.5Gバイト
データの大きさを調べてみよう:
dim(data)[1] 612004 1118
612004行1118列のデータだとわかる。確かに大きい。項目名(列名)を一覧してみよう:
names(data)[1] "CNTRYID" "CNT" "CNTSCHID" "CNTSTUID"[5] "CYC" "NatCen" "STRATUM" "SUBNATIO"[9] "OECD" "ADMINMODE" "LANGTEST_QQQ" "LANGTEST_COG"[13] "LANGTEST_PAQ" "BOOKID" "ST001D01T" "ST003D02T"[17] "ST003D03T" "ST004D01T" "ST005Q01TA" "ST006Q01TA"[21] "ST006Q02TA" "ST006Q03TA" "ST006Q04TA" "ST007Q01TA"[25] "ST008Q01TA" "ST008Q02TA" "ST008Q03TA" "ST008Q04TA"[29] "ST011Q01TA" "ST011Q02TA" "ST011Q03TA" "ST011Q04TA"[33] "ST011Q05TA" "ST011Q06TA" "ST011Q07TA" "ST011Q08TA"[37] "ST011Q09TA" "ST011Q10TA" "ST011Q11TA" "ST011Q12TA"[41] "ST011Q16NA" "ST011D17TA" "ST011D18TA" "ST011D19TA"....(後略)....
コードブックに書かれているが,先頭のいくつかの項目は次の通りである:
CNTRYID: 国コード(番号)CNT: 国(3文字)CNTSCHID: 学校コードCNTSTUID: 生徒コードOECD: OECD加盟国であるか(0: No, 1: Yes)さらに下に見ていくと,例えば IC001Q01TA Available for you to use at home: Desktop computer という項目があり,1 が Yes, and I use it,2 が Yes, but I dont use it,3 が No である。それぞれの回答数を表にしてみよう:
table(data$IC001Q01TA)1 2 3207182 50529 97676
日本の生徒についての内訳を見るには
table(data$IC001Q01TA[data$CNT=="JPN"])1 2 32200 1790 2029
とする。国とのクロス集計をしてみよう:
x = table(data$CNT, data$IC001Q01TA)head(x)1 2 3ALB 3940 558 1589ARE 0 0 0ARG 0 0 0AUS 6858 2406 2738AUT 4797 626 972BEL 5098 925 1585
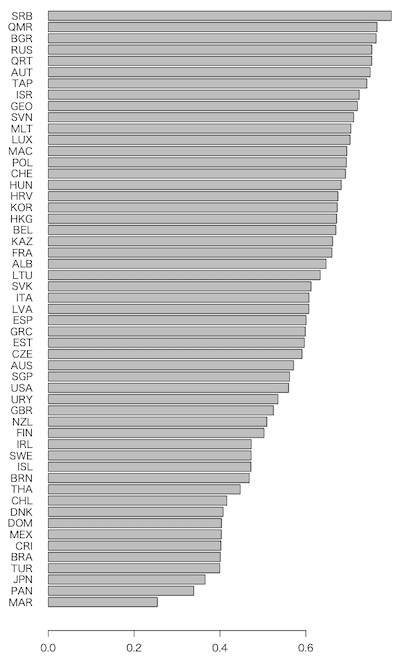
手抜き棒グラフにしてみよう:
barplot(sort(x[,1] / rowSums(x[,1:3])), horiz=TRUE, las=1)
日本は下から3番目である。
3文字国名の表 countries.csv(UTF-8)を使って日本語にしてみよう:
cnt = read.csv("https://okumuralab.org/~okumura/stat/data/countries.csv",
fileEncoding="UTF-8")
tcnt = cnt$国名
names(tcnt) = cnt$三字
s = sort(x[,1] / rowSums(x[,1:3]))
par(mar=c(5,15,1,2)) # 下左上右マージン(要調整)
barplot(s, horiz=TRUE, las=1, names.arg=tcnt[names(s)])
(未完)