以下は古いPISA 2012についてのものです。PISA 2012データは今でもPISAのサイトから入手できますが,以下にはリンク切れのページもあります。PISA 2015データを読むのほうをご参照ください。
OECD の PISA (Programme for International Student Assessment) のデータは PISA products からリンクをたどって得られる。例えば Database - PISA 2012 の Data sets in TXT format (compressed) の最初にある Student questionnaire data file はダウンロードすると235202268バイト(235Mバイト)の INT_STU12_DEC03.zip が得られる(たいへん遅いので注意)。これを展開すると1140901500バイト(約1Gバイト)の INT_STU12_DEC03.txt になる。これは固定長テキストデータ(行末CRLF)で,フォーマットは例えば SPSS syntax to read in student questionnaire data file (INT_STU12_SPSS.sps) を見ればわかる。
ちなみに,別にある Database - PISA CBA 2012 は,CBA (Computer-Based Assessment) によるデータで,上の部分集合である。ここにある Student questionnaire data file は 271323 x 615 のデータである。
PISAのライセンスについては PISA Product Licence に記されている。データや統計は商用利用も含めて自由に利用できる。
PISAについての日本語情報は次のサイトにある:
ここのPISA2012要約を見ると,日本では高校1年相当の生徒を対象に,層化二段抽出法で全国191校から約6400人を対象にしたことがわかる(データベースには6351人分のデータがある)。
PISAの固定長テキストデータを通常のCSVファイルにするPythonスクリプトが RによるPISAの分析(データの準備) で紹介されている。ここではこれをRubyに書き直した次のものを使う:
#! /usr/bin/ruby -w
# -*- coding: utf-8 -*-
x = []
y = []
v = []
File.foreach('INT_STU12_SPSS.sps') do |line|
line.strip!
break if line == "."
if line =~ /^(\w+) (\d+) - (\d+)/
v << $1
x << $2.to_i - 1
y << $3.to_i - 1
end
end
puts v.join(',')
while line = gets
z = []
x.length.times do |i|
z << line[x[i]..y[i]].strip
end
puts z.join(',')
end
次のように打ち込む:
./spss.rb INT_STU12_DEC03.txt > 2012all.csv
すると,約1.2Gバイトの 2012all.csv ができる(行末LFの場合1259448400バイト。CRLFなら485491バイト増)。
念のため,この 2012all.csv を圧縮した PISA2012.zip を置いておく。
ここでは,標準の read.csv() より速いはずの readr の read_csv() を使ってみる:
library(readr)
ALL = read_csv("2012all.csv") # 40秒ほど
dim(ALL) # 485490 634
object.size(ALL) # 1621663888 bytes
1.6Gバイトのメモリを食うが,どうってことはない。
634個ある各変数の意味は,さきほどの INT_STU12_SPSS.sps にも簡潔に書かれているが,より詳しくは Codebook for student questionnaire data file (M_stu_codebook.pdf) を読めばよい。具体的な質問は Questionnaires のところにある。
sum(ALL$CNT=="JPN") と打てばわかるように,日本は6351人分のデータがある。
例えばIC09 "How often do you use a computer for the following activities outside of school?" の6番目の "Doing homework on the computer" という問いについての日本の子どもたちの回答分布は
> table(ALL$IC09Q06[ALL$CNT=="JPN"])
1 2 3 4 5 7 9
5524 307 133 38 21 94 234
である。ここで回答は次の意味を持つ:
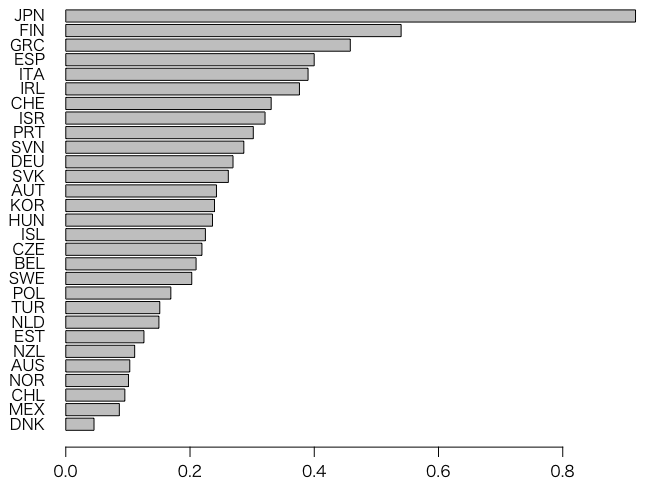
これと国名を掛け合わせたクロス集計をし,回答1(学校外でコンピュータで宿題なんかしないよ)の割合を国別に見てみよう。ただしOECD国に限ることにする。
x = table(ALL$CNT[ALL$OECD==1], ALL$IC09Q06[ALL$OECD==1])
barplot(sort(x[,1] / rowSums(x[,1:5])), horiz=TRUE, las=1)
日本ではコンピュータを使う宿題を出さないことがわかる。
日本の家庭にはコンピュータがないのか。
x = table(ALL$CNT[ALL$OECD==1], ALL$ST26Q04[ALL$OECD==1])
barplot(sort(x[,1] / rowSums(x[,1:2])), horiz=TRUE, las=1)
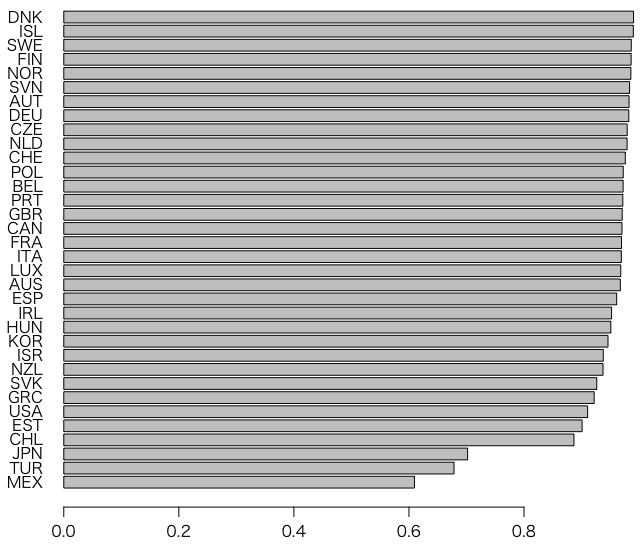
トルコとメキシコを除いて,他のOECD国よりかなり少ない。
日本だけ色を変えるには例えば次のようにする:
x = table(ALL$CNT[ALL$OECD==1], ALL$ST26Q04[ALL$OECD==1])
s = sort(x[,1] / rowSums(x[,1:2]))
barplot(s, horiz=TRUE, las=1, col=ifelse(names(s)=="JPN",gray(0.4),gray(0.8)))
さらに3文字国名を日本語にするにはウィキペディアのISO 3166-1から作った表 countries.csv(UTF-8)を使う。ただし,最後の6件(上海,台北,ペルミ,米国のいくつかの州)は国名ではなくPISAで便宜的に使っている地域名である。また,韓国・北朝鮮・台湾は略称を使った。
cnt = read.csv("countries.csv")
tcnt = cnt$国名
names(tcnt) = cnt$三字
x = table(ALL$CNT, ALL$ST26Q04)
s = sort(x[,1] / rowSums(x[,1:2]))
par(mar=c(1,10,1,2)+0.1) # マージン(デフォルト: c(5,4,4,2)+0.1)
barplot(s, horiz=TRUE, las=1, col=ifelse(names(s)=="JPN",gray(0.4),gray(0.8)),
names.arg=tcnt[names(s)], xlim=c(0,1), axes=FALSE)
axis(3, at=0:5/5, labels=paste(0:5*20, "%", sep=""), line=-1.5)
結果はこのPDFのようになる。
もう一つのほう(IC09Q06)は次のようにしてこのPDFのようになる。
x = table(ALL$CNT, ALL$IC09Q06)
s = sort(x[,1] / rowSums(x[,1:5]))
par(mar=c(1,10,1,2)+0.1) # マージン(デフォルト: c(5,4,4,2)+0.1)
barplot(s, horiz=TRUE, las=1, col=ifelse(names(s)=="JPN",gray(0.4),gray(0.8)),
names.arg=tcnt[names(s)], xlim=c(0,1), axes=FALSE)
axis(3, at=0:5/5, labels=paste(0:5*20, "%", sep=""), line=-1)
今度は散布図を描いてみよう。IC01の質問 Are any of these devices available for you to use at home? に対して (a) Desktop computer (b) Portable laptop, or notebook (g) <Cell phone> (with Internet access) などについて (1) Yes, and I use it (2) Yes, but I don't use it (3) No の選択肢がある。(g) のケータイ(ネット接続可)を使う割合については簡単である:
x = table(ALL$CNT, ALL$IC01Q07)
ph = x[,1] / rowSums(x[,1:3])
デスクトップPCとノートPCについては,少なくともどちらか一つ使う割合を求めたい。これは両方使わない割合を1から引けばよい:
x = table(ALL$CNT, ALL$IC01Q01, ALL$IC01Q02)
pc = 1 - rowSums(x[,2:3,2:3]) / rowSums(x[,1:3,1:3])
この二つを散布図にする:
plot(100*pc, 100*ph, pch=NA, xlab="PC(%)", ylab="携帯(%)", xlim=c(59,104))
text(100*pc, 100*ph, tcnt[names(ph)])
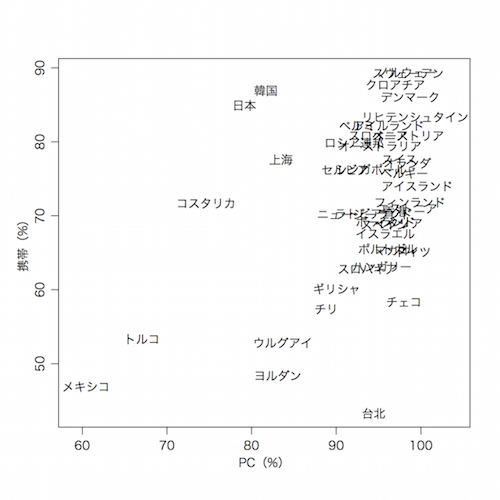
個票には成績は含まれていない。
成績の代わりに,plausible values というものが複数含まれている。これは,個人の成績としては用いてはならないが,全体についての統計量を計算する際に使うことのできる値である。i 番目の plausible value を使って統計量を求め,それを i について平均すれば,全体の統計量が求められる。
国ごとの成績概要は,例えば2012年なら PISA 2012 Results の Download Excel snapshot of student performance in mathematics, reading and science (XLS) から得られる。これに3文字国名を付けてCSVにした pisa2012summary.csv を置いておく。項目は,CNT(3文字国名),country(国名),math_mean(数学平均),math_low(数学レベル2未満の割合),math_top(数学レベル5・6の割合),math_change(数学の年変化),reading_mean(読解平均),reading_change(読解の年変化),science_mean(理科平均),science_change(理科の年変化)である。
同様に,pisa2009summary.csv は,CNT(3文字国名),country(国名),reading(読解),math(数学),science(理科)の平均である。
ちょっと手抜きで見にくいが散布図の例(数学):
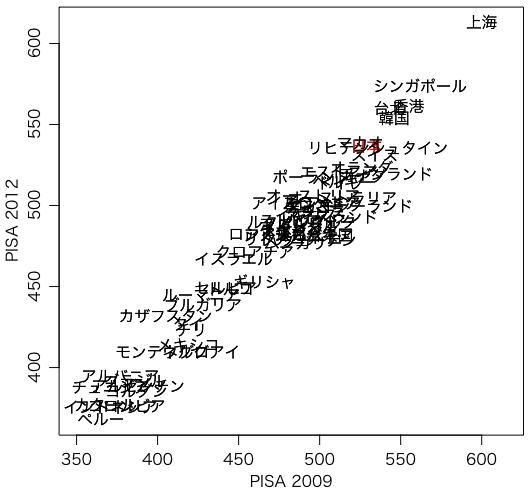
p2009 = read.csv("http://okumuralab.org/~okumura/stat/data/pisa2009summary.csv")
p2012 = read.csv("http://okumuralab.org/~okumura/stat/data/pisa2012summary.csv")
cnt = read.csv("http://okumuralab.org/~okumura/stat/data/countries.csv")
p = merge(p2009, p2012)
p = merge(p, cnt, by.x="CNT", by.y="三字")
with(p, plot(math, math_mean, type="n", xlab="PISA 2009", ylab="PISA 2012", asp=1))
with(p, text(math, math_mean, labels=国名, col=ifelse(CNT=="JPN","red","black")))