これはPISAデータを読むのPISA 2015年版(2016年12月結果公開)である。生徒のアンケート個票をRで読んで分析するのが目的である。
OECD の PISA (Programme for International Student Assessment) の2015年版データは PISA 2015 Database から得られる。例えば SPSS Data Files の Student questionnaire data file (407MB, ファイル名 PUF_SPSS_COMBINED_CMB_STU_QQQ.zip) をダウンロードして展開すると CY6_MS_CMB_STU_QQQ.sav という1.5Gバイトほどのファイルになる。これをRで読むには次のようにする:
# install.packages("foreign")library(foreign)data = read.spss("CY6_MS_CMB_STU_QQQ.sav", to.data.frame=TRUE)object.size(data)# 2.5Gバイト
2.5Gバイトという巨大なメモリを占有する。これを
data = read.spss("CY6_MS_CMB_STU_QQQ.sav", to.data.frame=TRUE, use.value.labels=FALSE)object.size(data)# 3.8Gバイト
とするとさらに巨大なメモリを要する。
さて,最近は Hadley Wickham 作のパッケージ群を使うのが流行りなので,haven
パッケージを試してみよう。これは zip で固めたままでも読むことができるが,以下では展開したものを読み込んでいる。
library(haven)data = read_sav("CY6_MS_CMB_STU_QQQ.sav")object.size(data)# 3.8Gバイト
これもかなりメモリを占有する。
以下では,この read_sav() で読んだデータを分析する。
念のためCSV化したものをzipで固めた CY6_MS_CMB_STU_QQQ.zip も置いておく。
2.4GHz Core 2 Duo メモリ8GBのMacでR 3.4.1で読んでみた:
data = read.csv("CY6_MS_CMB_STU_QQQ.csv", as.is=TRUE) # 遅いので諦めた
library(readr)
data = read_csv("CY6_MS_CMB_STU_QQQ.csv") # 4分50秒
library(data.table)
data = fread("CY6_MS_CMB_STU_QQQ.csv") # 1分40秒
[2019-05-07追記] 新しい Mac mini 3.6GHz Core i3 で Python でもやってみた:
df = pd.read_csv("CY6_MS_CMB_STU_QQQ.csv")
1回目68.6秒,2回目50.9秒であった。警告 "DtypeWarning: Columns (52,53,54) have mixed types. Specify dtype option on import or set low_memory=False." が出たが,これは
df = pd.read_csv("CY6_MS_CMB_STU_QQQ.csv", dtype={52:'object', 53:'object', 54:'object'})
として文字列として読み込むのが正解らしい。オプション low_memory=False を付けた場合は1回目124.7秒,2回目94.3秒であった。
ちなみに,同じマシンで R の readr でやってみたところ,1回目1分21秒,2回目1分17秒。data.table でやってみたところ,1回目21秒,2回目14秒だった。
読み込んだオブジェクトのサイズは,pandas が 4089336830,readr が 5068092632,data.table が 3760255424 であった(Python は import sys; sys.getsizeof(),R は object.size() で調べた)。
[2019-05-16追記] vroom が速いと聞いてやってみたが,1回目1分34秒,2回目38秒。あまり速くない。
[2019-08-16追記] Python の datatable でやってみた(参考)。
%time df = dt.fread("CY6_MS_CMB_STU_QQQ.csv")
1回目1分9秒,2回目15.4秒だった。sys.getsizeof(df) の結果は3757730280。このままでもいいが,pandasのDataFrameに変換してみる:
%time df = df2.to_pandas()
15.9秒かかった。
上記いずれかの方法で data という名前でデータを読み込んだとする。データの大きさを調べてみよう:
dim(data)[1] 519334 921
519334行921列のデータだとわかる。確かに大きい。項目名(列名)を一覧してみよう:
names(data)[1] "CNTRYID" "CNT" "CNTSCHID" "CNTSTUID"[5] "CYC" "NatCen" "Region" "STRATUM"[9] "SUBNATIO" "OECD" "ADMINMODE" "Option_CPS"[13] "Option_FL" "Option_ICTQ" "Option_ECQ" "Option_PQ"[17] "Option_TQ" "Option_UH" "Option_Read" "Option_Math"[21] "LANGTEST_QQQ" "LANGTEST_COG" "LANGTEST_PAQ" "CBASCI"[25] "BOOKID" "ST001D01T" "ST003D02T" "ST003D03T"[29] "ST004D01T" "ST005Q01TA" "ST006Q01TA" "ST006Q02TA"[33] "ST006Q03TA" "ST006Q04TA" "ST007Q01TA" "ST008Q01TA"[37] "ST008Q02TA" "ST008Q03TA" "ST008Q04TA" "ST011Q01TA"[41] "ST011Q02TA" "ST011Q03TA" "ST011Q04TA" "ST011Q05TA"....(後略)....
コードブック Codebooks for the main files に書かれているが,先頭のいくつかの項目は次の通りである:
CNTRYID: 国コード(番号)CNT: 国(3文字)CNTSCHID: 学校コードCNTSTUID: 生徒コードOECD: OECD加盟国であるか(0: No, 1: Yes)ST で始まる項目名が生徒に対する質問の回答である。質問の内容は Student questionnaire (computer-based assessment) に書かれている。例えば ST011「Which of the following are in your home?」の中の ST011Q04TA「A computer you can use for school work」では 1(Yes),2(No)が回答である。それぞれの回答数を表にしてみよう:
table(data$ST011Q04TA)1 2426698 71943
全体で519334件あるはずだが,合わせて498641しか回答がない。無回答の生徒もいるのだろう。
日本の生徒についての内訳を見るには
table(data$ST011Q04TA[data$CNT=="JPN"])1 24095 2477
とする。国とのクロス集計をしてみよう:
x = table(data$CNT, data$ST011Q04TA)head(x)1 2ALB 0 0ARE 12386 1303AUS 13019 978AUT 6734 222BEL 9084 418BGR 5473 219
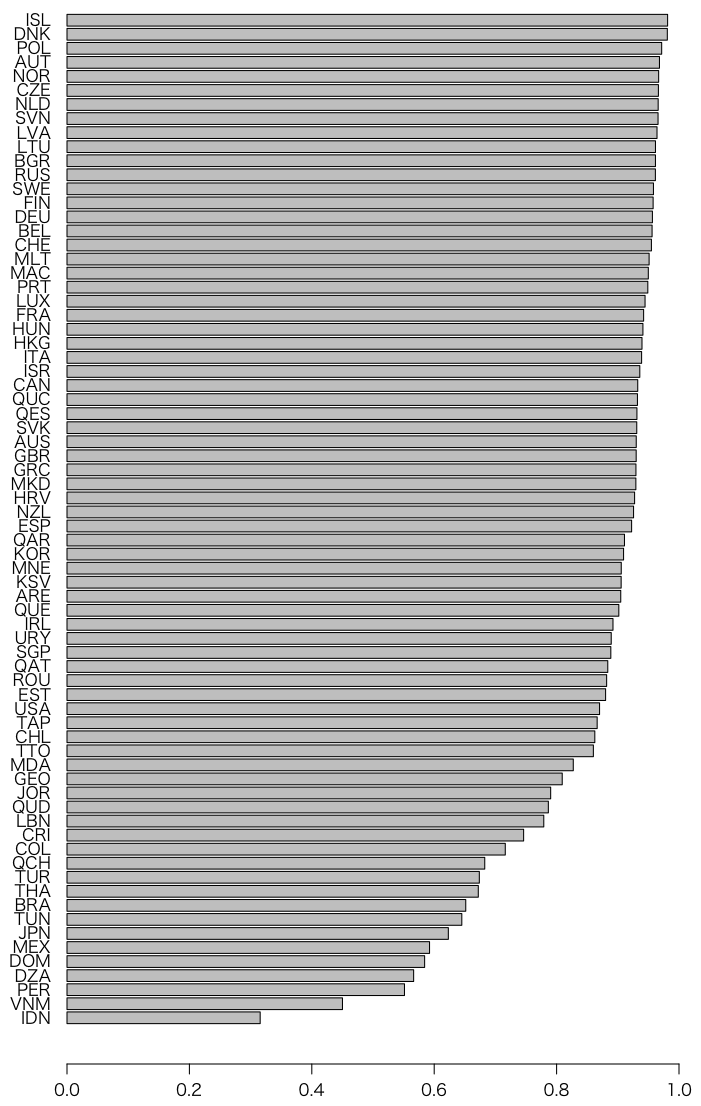
手抜き棒グラフにしてみよう:
barplot(sort(x[,1] / rowSums(x[,1:2])), horiz=TRUE, las=1)
日本は下から7番目である。
3文字国名の表 countries.csv(UTF-8)を使って日本語にしてみよう:
cnt = read.csv("https://okumuralab.org/~okumura/stat/data/countries.csv",
fileEncoding="UTF-8")
tcnt = cnt$国名
names(tcnt) = cnt$三字
s = sort(x[,1] / rowSums(x[,1:2]))
par(mar=c(5,15,1,2)) # 下左上右マージン(要調整)
barplot(s, horiz=TRUE, las=1, names.arg=tcnt[names(s)])
今度は散布図を描いてみよう。ST012の質問 How many of these are there at your home? に対して ST012Q05NA: <Cell phones> with Internet access (e.g. smartphones),ST012Q06NA: Computers (desktop computer, portable laptop, or notebook) について,1: None, 2: One, 3: Two, 4: Three or more の選択肢がある。ここでは,保有割合(全回答数のうち 2〜4 に答えた割合)を使うことにする:
x = table(data$CNT, data$ST012Q05NA)
ph = rowSums(x[,2:4]) / rowSums(x[,1:4])
y = table(data$CNT, data$ST012Q06NA)
pc = rowSums(y[,2:4]) / rowSums(y[,1:4])
plot(100*pc, 100*ph, pch=NA, xlab="PC(%)", ylab="スマホ(%)")
text(100*pc, 100*ph, tcnt[names(ph)], xpd=TRUE)
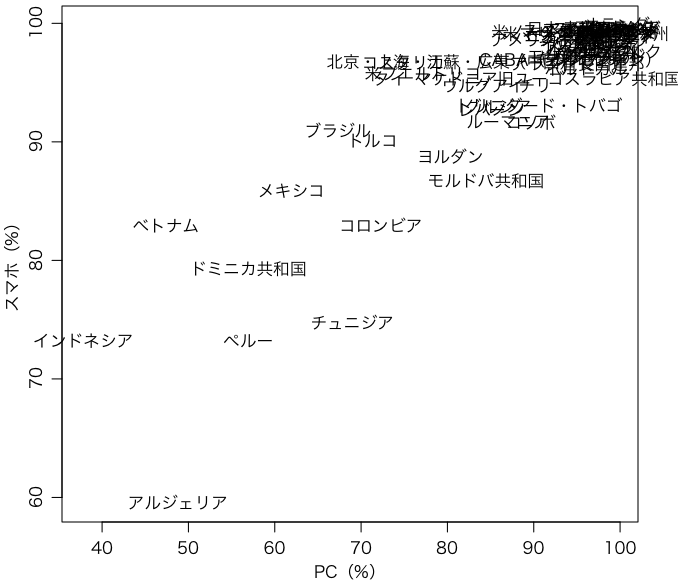
もはやほとんどの先進国が右上隅に集中してしまって,あまり見やすくない。