松本健太郎さんの『グラフをつくる前に読む本』という本についてのツイートを見て,PDF版を買ってみた。ちょっとした感想をツイートしたところ,著者からご返事をいただいた。なんでも国立国会図書館に通ったり海外の大学にメールを送ったりして調べられたとのことで,私の知らないこともたくさん書かれていた。
その本の152〜153ページに,日教組加入率と学力テストの結果の散布図がある。この話題は,私の古いブログの日教組組織率と学力,日教組組織率と学力:補遺,日教組票と学力,日教組票と学力:補遺で扱っているし,このサイトの相関にも少し出てくる。私の講演や授業でもよくとりあげる題材である。
松本さんの散布図は,横軸が2008年と2015年の日教組加入率の差で,縦軸は2016年の全国学力テストの中学数学Aの得点(正答率)である。中学数学Aだけを使うのは,相関のところにも書いた2008年9月27日の朝日新聞の方法を踏襲されたのであろう。一方,加入率そのものではなくその差を使ったのは,「「減少していない」=「組織が強い」という仮説」(p.152)からとのことである。
松本さんにお願いして,資料のコピーをお送りいただくことができた。いただいたのは『教育委員会月報』28.3および27.4で,都道府県別の加入状況は数値ではなくグラフだけが掲載されており,読み取る際の誤差が心配であるが,とりあえず(下に書いた方法で)えいやっとデータ化してみた:
H27日教組率 = c(29, 1, 45, 6, 32, 28, 17, 44, 0, 5, 1, 34, 6, 49, 52,
30, 41, 70, 52, 38, 0, 45, 46, 66, 11, 0, 16, 42, 30, 2, 40, 2, 37,
15, 1, 3, 0, 0, 1, 17, 11, 3, 7, 50, 4, 12, 34)
H26日教組率 = c(30, 1, 47, 6, 30, 29, 19, 42, 0, 6, 1, 35, 7, 51, 51,
30, 48, 72, 53, 38, 0, 48, 47, 67, 12, 0, 17, 42, 31, 2, 40, 3, 37,
16, 1, 3, 0, 0, 7, 18, 12, 4, 7, 51, 4, 12, 33)
これらの平均を横軸に,全国学力テストの小・中全科目の正答率の平均を縦軸にグラフを描こう。やりかたは全国学力テストの都道府県別正答率と教員初任給と同じである。
都道府県名 = c(
"北海道", "青森", "岩手", "宮城", "秋田", "山形", "福島",
"茨城", "栃木", "群馬", "埼玉", "千葉", "東京", "神奈川",
"新潟", "富山", "石川", "福井", "山梨", "長野", "岐阜",
"静岡", "愛知", "三重", "滋賀", "京都", "大阪", "兵庫",
"奈良", "和歌山", "鳥取", "島根", "岡山", "広島", "山口",
"徳島", "香川", "愛媛", "高知", "福岡", "佐賀", "長崎",
"熊本", "大分", "宮崎", "鹿児島", "沖縄")
正答率 = read.csv("https://okumuralab.org/~okumura/stat/data/atest2017.csv")
日教組率 = (H26日教組率 + H27日教組率) / 2
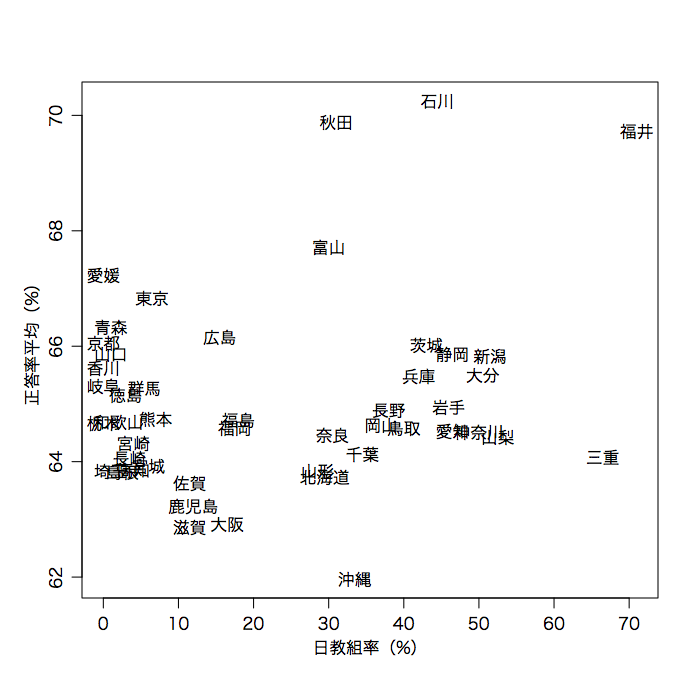
plot(日教組率, rowMeans(正答率[,2:9]), type="n", xlab="日教組率(%)", ylab="正答率平均(%)")
text(日教組率, rowMeans(正答率[,2:9]), 都道府県名)
まったく関係なさそうである(どちらかというと弱い正の相関があるが,有意ではない)。
多分こういうことをするパッケージはすでにあると思うが,探すのも面倒なので,即興で作った。アルゴリズムはいいかげんである。
グラフをpngで保存しておき,画像処理で書いた imager パッケージで読み込んで表示する:
install.packages("imager")
library(imager)
pic = load.image("…….png")
plot(pic)
グラフ表示をなるべく画面いっぱいにしておき,Rに
a = locator()
と打ち込むと,図上でカーソルが十字型になるので,マウスでグラフの4隅と,読み取るべき点を順にクリックする。4隅+47都道府県で,51回クリックすることになる。
a に入った座標を数値化するために,次のいいかげんな関数をでっち上げた:
f = function(x1, x2, y1, y2, a) {
n = length(a$x)
sapply(5:n, function(i) {
q = 0.5
for (j in 1:10) { # 回数は適当(収束するまで)
p = (a$x[i] - a$x[1]) / (a$x[2] - a$x[1]) * (1 - q) +
(a$x[i] - a$x[3]) / (a$x[4] - a$x[3]) * q
q = (a$y[i] - a$y[1]) / (a$y[3] - a$y[1]) * (1 - p) +
(a$y[i] - a$y[2]) / (a$y[4] - a$y[2]) * p
}
c(x1+(x2-x1)*p, y1+(y2-y1)*q)
})
}
これで
f1 = f(0, 100, 1, 47, a)
round(f1[1,])
とすると,加入率が出る仕組みである。ついでに round(f1[2,]) で都道府県番号1〜47が出るはずである。
2回繰り返して,一致しない県についてだけ再度行って多数決で決めた。
なお,日教組組織率と学力:補遺の読者からいただいた古いデータも以下に挙げておく:
H3日教組率 = c(45, 4, 56, 32, 38, 55, 30, 52, 0, 15, 3, 40, 18, 68,
63, 36, 62, 85, 57, 52, 0, 50, 49, 84, 23, 0, 30, 43, 26, 1, 63, 3,
44, 48, 2, 3, 0, 1, 6, 39, 32, 16, 29, 64, 22, 31, 61)