[2019-02-16追記] @TA25140989 さんが brunnermunzel パッケージを作られました。これは、内部を Fortran で高速化し、並べ替え Brunner-Munzel 検定もできる優れものです。
[2019-03-10追記] 上記パッケージがCRANに入りました: brunnermunzel: (Permuted) Brunner-Munzel Test。「lawstatパッケージに由来する不具合は次回更新時に修正します(GitHubでは対応済)」とのことです。
[2019-04-10追記] 上記パッケージに計算のおかしいところがあったようで、これから修正が入るようです修正版が出ました。
Python版のBrunner-Munzel検定のページも作りました。
二つの確率変数 $X_1$、$X_2$ が同じ分布に従うという帰無仮説を検定するには、有名なWMW検定(Wilcoxon-Mann-Whitney test)が使えます。しかし、分布が異なる(例えば分散が異なる)場合には、これでは正確に検定できません。
そこで、分布が同じことは仮定せず、両群から一つずつ値を取り出したとき、どちらが大きい確率も等しいという帰無仮説を検定することにします。つまり、
\[ p = P(X_1 < X_2) + \frac{1}{2}P(X_1 = X_2) \]としたとき、$p = 1/2$ が帰無仮説になります。
この $p$ は(本質的でない不等号の向きを無視すれば)WMW検定の統計量を各群の個数の積で割ったものに過ぎません。ただ、WMW検定では両群の分布が同じと仮定するのに対して、ちょうど $t$ 検定を各群の分散が等しくない場合にWelchが拡張したのと同じように拡張したのが、Brunner(ブルンナー)とMunzel(ムンツェル)によるBrunner-Munzel検定(Brunner-Munzel test)です。
以下では、彼らの次の論文に基づいて解説します。
各群 $i\ (=1,2)$ から大きさ $n_i$ の標本を取り出したとします:
\[ X_{i1}, X_{i2}, \ldots, X_{in_i} \]全部を並べた $N = n_1 + n_2$ 個のデータ
\[ X_{11}, X_{12}, \ldots, X_{1n_1}, \quad X_{21}, X_{22}, \ldots, X_{2n_2} \]の、全体を通しての順位を
\[ R_{11}, R_{12}, \ldots, R_{1n_1}, \quad R_{21}, R_{22}, \ldots, R_{2n_2} \]とします(同順位がある場合は順位の平均を用います。以下同様)。この各群内での平均を
\[ \bar{R}_{i\cdot} = \frac{1}{n_i}(R_{i1} + R_{i2} + \cdots + R_{in_i}) \]とすると、
\[ \hat{p} = \frac{\bar{R}_{2\cdot} - \bar{R}_{1\cdot}}{N} + \frac{1}{2} \]が、最初に挙げた $p$ の不偏推定量になります。
一方、それぞれの群内での順位を
\[ R_{i1}^{(i)}, R_{i2}^{(i)}, \ldots, R_{in_i}^{(i)} \]とすると、その平均は
\[ \frac{1}{n_i}(R_{i1}^{(i)} + R_{i2}^{(i)} + \cdots + R_{in_i}^{(i)}) = \frac{n_i + 1}{2} \]です。ここで
\[ \begin{gather*} S_i^2 = \frac{1}{n_i - 1} \sum_{k=1}^{n_i} \left( R_{ik} - R_{ik}^{(i)} - \bar{R}_{i\cdot} + \frac{n_i + 1}{2} \right)^2 \\\\ \hat{\sigma}_i^2 = \frac{S_i^2}{(N - n_i)^2}, \qquad \hat{\sigma}_N^2 = N \left(\frac{\hat{\sigma}_1^2}{n_1} + \frac{\hat{\sigma}_2^2}{n_2} \right) \end{gather*} \]とすると、
\[ W_N^{BF} = \frac{1}{\sqrt{N}} \cdot \frac{\bar{R}_{2\cdot} - \bar{R}_{1\cdot}}{\hat{\sigma}_N} = \frac{n_1 n_2 (\bar{R}_{2\cdot} - \bar{R}_{1\cdot})}{(n_1 + n_2)\sqrt{n_1 S_1^2 + n_2 S_2^2}} \]は、漸近的に($n_i$ や $n_2$ が大きくなると)、標準正規分布 $N(0,1)$ に近づきます。小標本の場合には、より良い近似として、$W_N^\mathrm{BF}$ を自由度
\[ \hat{f} = \frac{(\hat{\sigma}_1^2 / n_1 + \hat{\sigma}_2^2 / n_2)^2} {\dfrac{(\hat{\sigma}_1^2 / n_1)^2}{n_1 - 1} + \dfrac{(\hat{\sigma}_2^2 / n_2)^2}{n_2 - 1}} = \frac{(n_1 S_1^2 + n_2 S_2^2)^2} {\dfrac{(n_1 S_1^2)^2}{n_1 - 1} + \dfrac{(n_2 S_2^2)^2}{n_2 - 1}} \]の $t$ 分布で検定することをBrunnerとMunzelは提案しています。
Rには lawstat パッケージに brunner.munzel.test() があります。t検定で使った Lumley (1996) のデータで試してみましょう。
library(lawstat) x = c(1,2,1,1,1,1,1,1,1,1,2,4,1,1) y = c(3,3,4,3,1,2,3,1,1,5,4) brunner.munzel.test(x, y)
結果は次のようになりました:
Brunner-Munzel Test
data: x and y
Brunner-Munzel Test Statistic = 3.1375, df = 17.683,
p-value = 0.005786
95 percent confidence interval:
0.5952169 0.9827052
sample estimates:
P(X<Y)+.5*P(X=Y)
0.788961
新しいbrunnermunzelパッケージでは次のようになります:
install.packages("brunnermunzel")
library(brunnermunzel)
x = c(1,2,1,1,1,1,1,1,1,1,2,4,1,1)
y = c(3,3,4,3,1,2,3,1,1,5,4)
brunnermunzel.test(x, y)
結果:
Brunner-Munzel Test
data: x and y
Brunner-Munzel Test Statistic = 3.1375, df = 17.683, p-value = 0.005786
95 percent confidence interval:
0.5952169 0.9827052
sample estimates:
P(X<Y)+.5*P(X=Y)
0.788961
サンプルが非常に小さい場合には、Brunner-Munzelの統計量に並べ替え検定を適用すれば、もっと正確に計算できます。この方法(permuted Brunner-Munzel test)は次の文献で評価されています:
さきほどと同じデータでやってみましょう。全部の並べ替えでやってみたところ、Pentium 4 3.20GHzのLinuxマシンで6000秒あまりかかりました。
bm = brunner.munzel.test(x, y)$statistic
n1 = length(x)
n2 = length(y)
N = n1 + n2
xandy = c(x, y)
foo = function(X) {
brunner.munzel.test(xandy[X], xandy[-X])$statistic
}
z = combn(1:N, n1, foo)
mean(abs(z) >= abs(bm))
結果は 0.008037645 となりました。
新しいbrunnermunzelパッケージでは次のように簡単かつ高速にできます:
brunnermunzel.permutation.test(x, y)permuted Brunner-Munzel Testdata: x and yp-value = 0.008038
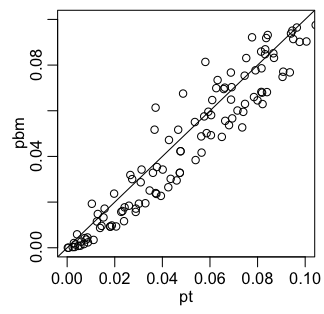
Brunner-Munzel検定と、Welchの $t$ 検定を順位について適用した場合とでは、右図のように、どちらかといえば前者のほうが小さい $p$ 値が出やすいようです。
この図は次のRのプログラムで描きました:
ni = 1000
pt = pbm = numeric(ni)
for (i in 1:ni) {
a = sample(20)
b = sample(5:10, 1)
x = a[1:b]
y = a[(b+1):20]
pt[i] = t.test(x, y)$p.value
pbm[i] = brunner.munzel.test(x, y)$p.value
}
par(mgp=c(1.5,0.6,0)) # 数字とラベルをもっと軸に近づける
plot(pt, pbm, xlim=c(0,0.1), ylim=c(0,0.1))
abline(0, 1)
[追記] より詳しいシミュレーション結果→マイナーだけど最強の統計的検定 Brunner-Munzel 検定
[追記] 並べ替え検定の改良版→ Brunner-Munzel の並べ替え検定 - 裏 RjpWiki