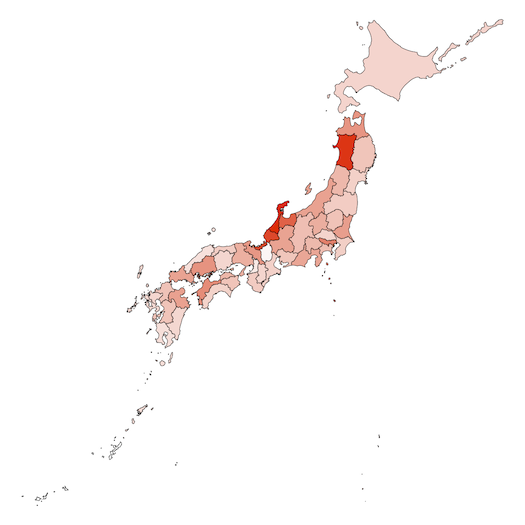
全国学力テストの都道府県別正答率の2018年版である。
2018年7月31日に,平成30年度全国学力テスト(正確には「全国学力・学習状況調査」)の結果が国研のこのページで公開された。
平成29年度から,都道府県ごとの競争を煽らないために,都道府県別平均正答率は整数に丸めて公開されている。しかし,実際には小数点以下の勝った負けたが行われている。確かに全体としては整数に丸めた値しか公表されていないが,都道府県別のファイルには小数第1位までちゃんと書かれており,さらに度数分布まで公開されているので任意精度で平均正答率を求めることができる。
詳しい情報が書かれているのは,このページからリンクされているExcelファイル群である。とりあえずこれらを全部ダウンロードしてみよう(これはRではなくUNIXのコマンドである):
wget -m -np -w 5 http://www.nier.go.jp/18chousakekkahoukoku/factsheet/18prefecture-City/
ディレクトリに分かれてたくさんのファイルが取得できる。このうち,小学校の成績の県ごとのファイルは 01p_18r.xlsx から 47p_18r.xlsr までである。これらの名前一覧を取得するRのコマンドは次の通りである(全部のファイルが見える上位のディレクトリで実行する):
names = dir(pattern="^\\d\\dp_18r.xlsx$", full.names=TRUE, recursive=TRUE)
Excelで開いてみると,AE8〜AE20の範囲に国語Aの正答数の度数分布(12問〜0問)が並んでいることがわかる。これらを取得して,都道府県ごとの平均正答数を求めるRのコマンドは次の通りである(あらかじめ library(readxl) しておく):
f = function(n) unlist(read_excel(n, 1, col_names=FALSE, range="AE8:AE20")) # 国語A
x = sapply(names, f)
pka = sapply(1:47, function(i) sum(x[,i]*12:0)/sum(x[,i]))
同様に他の科目や中学校も行えばよい。全体をまとめて,平均正答数を平均正答率(%)に変換してCSVファイルに収めるところまでは,次のスクリプトになる:
library(readxl)
# 小学校
names = dir(pattern="^\\d\\dp_18r.xlsx$", full.names=TRUE, recursive=TRUE)
f = function(n) unlist(read_excel(n, 1, col_names=FALSE, range="AE8:AE20")) # 国語A
x = sapply(names, f)
pka = sapply(1:47, function(i) sum(x[,i]*12:0)/sum(x[,i]))
f = function(n) unlist(read_excel(n, 1, col_names=FALSE, range="AE51:AE59")) # 国語B
x = sapply(names, f)
pkb = sapply(1:47, function(i) sum(x[,i]*8:0)/sum(x[,i]))
f = function(n) unlist(read_excel(n, 2, col_names=FALSE, range="AE8:AE22")) # 算数A
x = sapply(names, f)
psa = sapply(1:47, function(i) sum(x[,i]*14:0)/sum(x[,i]))
f = function(n) unlist(read_excel(n, 2, col_names=FALSE, range="AE51:AE61")) # 算数B
x = sapply(names, f)
psb = sapply(1:47, function(i) sum(x[,i]*10:0)/sum(x[,i]))
f = function(n) unlist(read_excel(n, 3, col_names=FALSE, range="AE8:AE24")) # 理科
x = sapply(names, f)
pr = sapply(1:47, function(i) sum(x[,i]*16:0)/sum(x[,i]))
f = function(n) unlist(read_excel(n, 3, col_names=FALSE, range="AE51:AE54")) # 理科A
x = sapply(names, f)
pra = sapply(1:47, function(i) sum(x[,i]*3:0)/sum(x[,i]))
f = function(n) unlist(read_excel(n, 3, col_names=FALSE, range="AE94:AE107")) # 理科B
x = sapply(names, f)
prb = sapply(1:47, function(i) sum(x[,i]*13:0)/sum(x[,i]))
# 中学校
names = dir(pattern="^\\d\\dm_18r.xlsx$", full.names=TRUE, recursive=TRUE)
f = function(n) unlist(read_excel(n, 1, col_names=FALSE, range="AE8:AE40")) # 国語A
x = sapply(names, f)
mka = sapply(1:47, function(i) sum(x[,i]*32:0)/sum(x[,i]))
f = function(n) unlist(read_excel(n, 1, col_names=FALSE, range="AE63:AE72")) # 国語B
x = sapply(names, f)
mkb = sapply(1:47, function(i) sum(x[,i]*9:0)/sum(x[,i]))
f = function(n) unlist(read_excel(n, 2, col_names=FALSE, range="AE8:AE44")) # 数学A
x = sapply(names, f)
msa = sapply(1:47, function(i) sum(x[,i]*36:0)/sum(x[,i]))
f = function(n) unlist(read_excel(n, 2, col_names=FALSE, range="AE63:AE77")) # 数学B
x = sapply(names, f)
msb = sapply(1:47, function(i) sum(x[,i]*14:0)/sum(x[,i]))
f = function(n) unlist(read_excel(n, 3, col_names=FALSE, range="AE8:AE35")) # 理科
x = sapply(names, f)
mr = sapply(1:47, function(i) sum(x[,i]*27:0)/sum(x[,i]))
f = function(n) unlist(read_excel(n, 3, col_names=FALSE, range="AE63:AE74")) # 理科A
x = sapply(names, f)
mra = sapply(1:47, function(i) sum(x[,i]*11:0)/sum(x[,i]))
f = function(n) unlist(read_excel(n, 3, col_names=FALSE, range="AE118:AE134")) # 理科B
x = sapply(names, f)
mrb = sapply(1:47, function(i) sum(x[,i]*16:0)/sum(x[,i]))
all = data.frame(番号=1:47,
小国A=pka*(100/12), 小国B=pkb*(100/8),
小算A=psa*(100/14), 小算B=psb*(100/10), 小理=pr*(100/16),
中国A=mka*(100/32), 中国B=mkb*(100/9),
中数A=msa*(100/36), 中数B=msb*(100/14), 中理=mr*(100/27))
write.csv(all, "atest2018.csv", quote=FALSE, row.names=FALSE)
このようにして作った atest2018.csv を置いておく。文字コードはExcelで文字化けしにくいようにBOM付きUTF-8とした。MacのRなら read.csv() でそのまま読み込めるが,WindowsのRならオプション fileEncoding="UTF-8-BOM" が必要である(fileEncoding="UTF-8" だけではうまくいかないようだ)。
次の日本地図は色が濃いほど成績が良い。