2017年8月28日に,平成29年度全国学力テスト(正確には「全国学力・学習状況調査」)の結果が国研のこのページで公開された。
今年は,都道府県ごとの競争を煽らないために,都道府県別平均正答率は整数に丸めて公開された。しかし,実際には小数点以下の勝った負けたが行われている。確かに全体としては整数に丸めた値しか公表されていないが,都道府県別のファイルには小数第1位までちゃんと書かれており,さらに度数分布まで公開されているので任意精度で平均正答率を求めることができる。
詳しい情報が書かれているのは,このページからリンクされているExcelファイル群である。とりあえずこれらを全部ダウンロードしてみよう(これはRではなくUNIXのコマンドである):
wget -m -np -w 5 http://www.nier.go.jp/17chousakekkahoukoku/factsheet/17prefecture-City/
ディレクトリに分かれてたくさんのファイルが取得できる。このうち,小学校の成績の県ごとのファイルは 01p_17r.xlsx から 47p_17r.xlsr までである。これらの名前一覧を取得するRのコマンドは次の通りである(全部のファイルが見える上位のディレクトリで実行する):
names = dir(pattern="^\\d\\dp_17r.xlsx$", full.names=TRUE, recursive=TRUE)
Excelで開いてみると,AE9〜AE24の範囲に国語Aの正答数の度数分布(0問〜15問)が並んでいることがわかる。これらを取得して,都道府県ごとの平均正答数を求めるRのコマンドは次の通りである(あらかじめ library(readxl) しておく):
f = function(n) unlist(read_excel(n, 1, col_names=FALSE, range="AE9:AE24")) # 国語A
x = sapply(names, f)
pka = sapply(1:47, function(i) sum(x[,i]*0:15)/sum(x[,i]))
同様に他の科目や中学校も行えばよい。全体をまとめて,平均正答数を平均正答率(%)に変換してCSVファイルに収めるところまでは,次のスクリプトになる:
library(readxl)
# 小学校
names = dir(pattern="^\\d\\dp_17r.xlsx$", full.names=TRUE, recursive=TRUE)
f = function(n) unlist(read_excel(n, 1, col_names=FALSE, range="AE9:AE24")) # 国語A
x = sapply(names, f)
pka = sapply(1:47, function(i) sum(x[,i]*0:15)/sum(x[,i]))
f = function(n) unlist(read_excel(n, 1, col_names=FALSE, range="AE53:AE62")) # 国語B
x = sapply(names, f)
pkb = sapply(1:47, function(i) sum(x[,i]*0:9)/sum(x[,i]))
f = function(n) unlist(read_excel(n, 2, col_names=FALSE, range="AE9:AE24")) # 算数A
x = sapply(names, f)
psa = sapply(1:47, function(i) sum(x[,i]*0:15)/sum(x[,i]))
f = function(n) unlist(read_excel(n, 2, col_names=FALSE, range="AE53:AE64")) # 算数B
x = sapply(names, f)
psb = sapply(1:47, function(i) sum(x[,i]*0:11)/sum(x[,i]))
# 中学校
names = dir(pattern="^\\d\\dm_17r.xlsx$", full.names=TRUE, recursive=TRUE)
f = function(n) unlist(read_excel(n, 1, col_names=FALSE, range="AD8:AD40")) # 国語A
x = sapply(names, f)
mka = sapply(1:47, function(i) sum(x[,i]*0:32)/sum(x[,i]))
f = function(n) unlist(read_excel(n, 1, col_names=FALSE, range="AD55:AD64")) # 国語B
x = sapply(names, f)
mkb = sapply(1:47, function(i) sum(x[,i]*0:9)/sum(x[,i]))
f = function(n) unlist(read_excel(n, 2, col_names=FALSE, range="AD8:AD44")) # 数学A
x = sapply(names, f)
msa = sapply(1:47, function(i) sum(x[,i]*0:36)/sum(x[,i]))
f = function(n) unlist(read_excel(n, 2, col_names=FALSE, range="AD55:AD70")) # 数学B
x = sapply(names, f)
msb = sapply(1:47, function(i) sum(x[,i]*0:15)/sum(x[,i]))
all = data.frame(番号=1:47,
小国A=pka*(100/15), 小国B=pkb*(100/9), 小算A=psa*(100/15), 小算B=psb*(100/11),
中国A=mka*(100/32), 中国B=mkb*(100/9), 中数A=msa*(100/36), 中数B=msb*(100/15))
write.csv(all, "atest2017.csv", quote=FALSE, row.names=FALSE)
このようにして作った atest2017.csv を置いておく(文字コードはExcelでも読めるようにBOM付きUTF-8とした)。
せっかく整数に丸めて公表されているのに,勝手に丸める前の値を公開していいものか。ちょっと悩んだので,都道府県名は付けないでおいた。
おまけ:通塾と学力の相関という記事を見かけたので,このデータで検証してみる:
library(readxl)
names = dir(pattern="^\\d\\dp_17a.xlsx$", full.names=TRUE, recursive=TRUE)
f = function(n) unlist(read_excel(n, 1, col_names=FALSE, range="C60:U60")) # 学習塾
x = sapply(names, f)
juku = sapply(1:47, function(i) 1 - as.numeric(x[9,i])/sum(as.numeric(x[c(9:13,18:19),i])))
# [1] 0.3686093 0.2828586 0.2601114 0.3804514 0.2224544 0.2851136 0.3339514
# [8] 0.4145688 0.4176955 0.4422374 0.4563553 0.5127072 0.5820875 0.5739025
# [15] 0.3572296 0.3739383 0.3719183 0.3828915 0.4184482 0.3981113 0.4716042
# [22] 0.4755472 0.4976620 0.5011098 0.4903206 0.5062606 0.5113585 0.5480711
# [29] 0.5427592 0.5320781 0.3610875 0.3233766 0.4661890 0.4581543 0.4285054
# [36] 0.4930064 0.4432964 0.4654696 0.4648547 0.3999904 0.3711454 0.3745027
# [43] 0.3569343 0.3980394 0.3356785 0.3263963 0.3836275
a = read.csv("https://okumuralab.org/~okumura/stat/data/atest2017.csv")
kenmei = c("北海道", "青森", "岩手", "宮城", "秋田", "山形", "福島", "茨城",
"栃木", "群馬", "埼玉", "千葉", "東京", "神奈川", "新潟", "富山", "石川",
"福井", "山梨", "長野", "岐阜", "静岡", "愛知", "三重", "滋賀", "京都",
"大阪", "兵庫", "奈良", "和歌山", "鳥取", "島根", "岡山", "広島", "山口",
"徳島", "香川", "愛媛", "高知", "福岡", "佐賀", "長崎", "熊本", "大分",
"宮崎", "鹿児島", "沖縄")
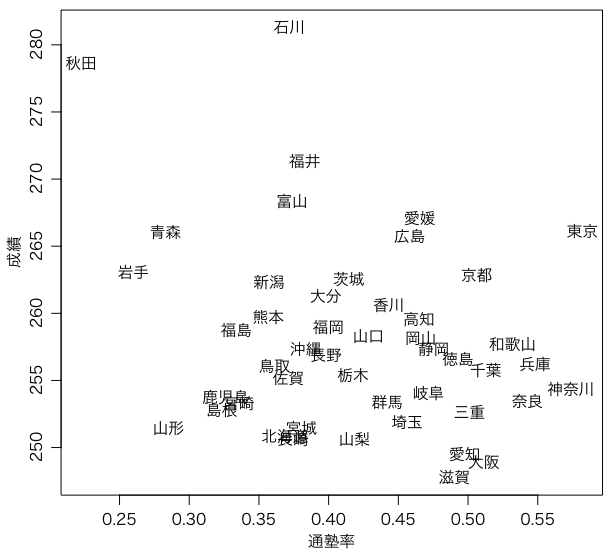
plot(juku, rowSums(a[,2:5]), type="n", xlab="通塾率", ylab="成績")
text(juku, rowSums(a[,2:5]), kenmei)
cor.test(juku, rowSums(a[,2:5]))
# Pearson's product-moment correlation
#
# data: juku and rowSums(a[, 2:5])
# t = -1.8927, df = 45, p-value = 0.06484
# alternative hypothesis: true correlation is not equal to 0
# 95 percent confidence interval:
# -0.51829704 0.01694128
# sample estimates:
# cor
# -0.2715466
総得点とは負の相関があるように見える(統計的に有意ではない)。科目ごとに見れば,国A・算Aとは統計的に有意な負の相関がある。
これは県レベルの相関であるが,個人レベルの相関はこれではわからない。ここの下のほうにある「クロス集計表(児童質問紙-教科)全国【表】」というExcel表(ファイル名 17p_424.xlsx)に個人レベルのクロス集計が記されている。同じ塾でも,「学校の勉強より進んだ内容や,難しい内容を勉強している」塾と「学校の勉強でよく分からなかった内容を勉強している」塾で正反対の傾向が見えるが,機械的に人数で重みづけて平均してみる:
ju = read_excel("17p_424.xlsx", 17, col_names=FALSE, range="G13:O17")
ju = ju[,c(1,2,3,5,7,9)]
matplot(1:2, sapply(3:6, function(i) c(ju[1,i], sum(ju[2:5,i] * ju[2:5,1]) / sum(ju[2:5,1]))),
pch=16, col="black", type="o", lty=1, xlim=c(0.7,2.3), xaxt="n",
xlab="", ylab="平均正答率")
text(2, sapply(3:6, function(i) sum(ju[2:5,i] * ju[2:5,1]) / sum(ju[2:5,1])),
labels=c("国A","国B","算A","算B"), pos=4)
axis(1, at=1:2, labels=c("通塾なし","通塾あり"))
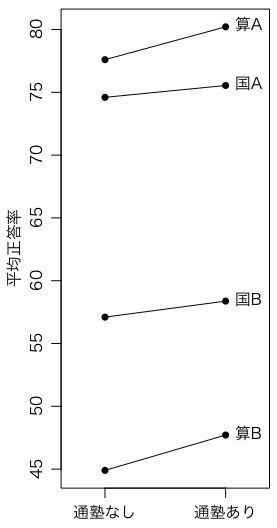
どの科目についても,個人レベルでは通塾ありのほうが成績が良い。県レベルで見えた負の相関から個人レベルの相関を推測するのは正しくなさそうである(生態学的誤謬。同様な例はPIAACデータ解析,地域の大人に勉強を教えてもらうと成績が下がる?参照)。