グラフの例:地球温暖化
気象庁 | 世界の年平均気温偏差(℃)
にある世界全体の平均気温をプロットする。
データを取得する:
data = read.csv("http://www.data.jma.go.jp/cpdinfo/temp/list/csv/an_wld.csv", fileEncoding="CP932")
[2019-01-21追記] ツイッターで教えていただいたが,おそらく一時的なものだと思うが,昨年末,このファイルに2018年の項目が付け加わった際に,
2018,+0.30*,+0.41*,+0.20*
のようにゴミ(* 印)が付いた。気象庁によれば,「*:1月から11月までの月平均気温の偏差をもとに算出した速報値」とのことである。この余計な文字のおかげで,列全体が文字列と見なされる。さらにRの read.csv() などはデフォルトで文字列をファクター(列挙型のようなもの)として扱い,内部的に整数で保存される。これを plot() で使うと,強制的に数値に変換される際に,ファクターの内部表現としての整数値が使われてしまうため,次のようなでたらめなグラフになってしまう。
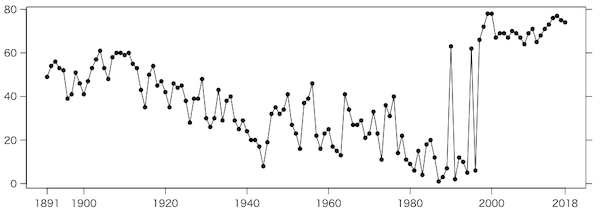
これは少なくともエラーになったほうがいいので,文字列をファクターにしないためのおまじない
options(stringsAsFactors=FALSE)
を冒頭で実行しておくほうが安全であろう。そうすれば,2018年の値は「強制変換により NA が生成されました」という警告メッセージが出て NA に変換され,無視される。もし2018年の値も使いたいなら,さらに
for (i in 1:dim(data)[2]) {
data[,i] = as.numeric(gsub("[^0123456789.-]", "", data[,i]))
}
とすればよい。これは "[^0123456789.-]" すなわち0〜9・ピリオド・マイナス以外を空文字列で置き換える。ここでは data[,i] は文字列として扱われるので,数値でも問題ないし,ファクターでもその内部表現ではなく文字列として扱われるので,意図通りに変換される。
readr パッケージの read_csv() を使えば,ファクターには変換されず,この場合は文字列になる。ただし data[,i] は data[[i]] にする必要がある。
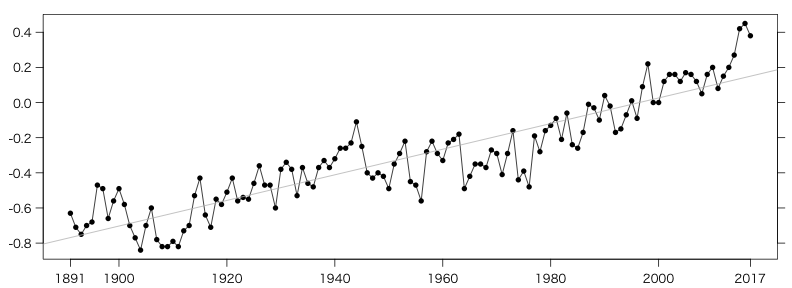
まずは「世界全体」だけを描く。簡単には
plot(data$年, data$世界全体, type="l")
とすればよいが,もう少し手をかけてみる:
par(mgp=c(2,0.8,0)) # 軸マージン(デフォルト: c(3,1,0))
par(las=1) # 縦軸の文字を横向きにしない
plot(data$年, data$世界全体, type="o", pch=16, xlab="", ylab="", xaxt="n")
t = c(1891, seq(1900,max(data$年)-8,20), max(data$年))
axis(1, t, t)
axis(4, labels=FALSE)
ついでに回帰直線も加える:
r = lm(data$世界全体 ~ data$年)
abline(r, col="gray")
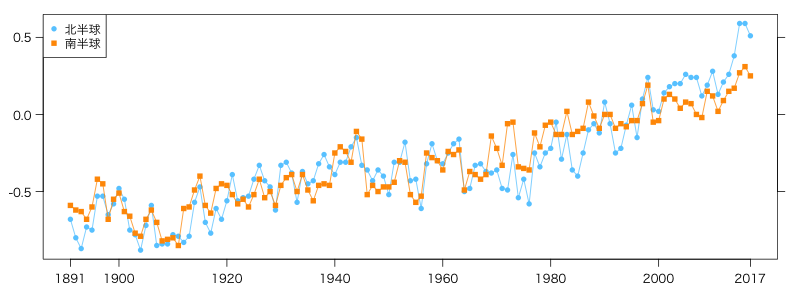
北半球と南半球に分けて描く:
matplot(data$年, data[c("北半球","南半球")], type="o", lty=1,
pch=c(16,15), col=c("#66ccff","#ff9900"), xlab="", ylab="", xaxt="n")
t = c(1891, seq(1900,max(data$年)-8,20), max(data$年))
axis(1, t, t)
axis(4, labels=FALSE)
legend("topleft", legend=c("北半球","南半球"), pch=c(16,15), col=c("#66ccff","#ff9900"))
中澤港先生の
これ
や
これ
も参照。
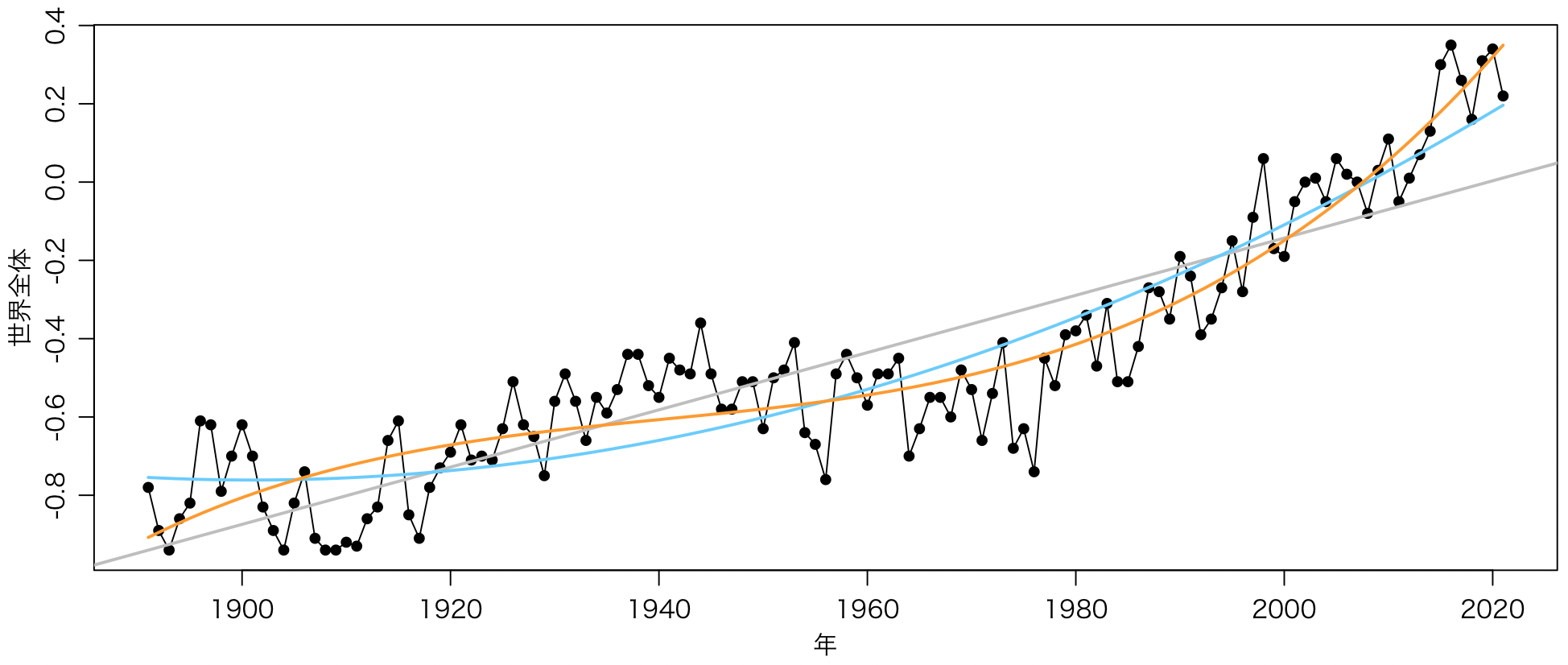
2022年になったので2021年までのデータで描き直し、1〜3次の曲線でフィットしてみる。
df = read.csv("http://www.data.jma.go.jp/cpdinfo/temp/list/csv/an_wld.csv",
fileEncoding="CP932")
with(df, plot(年, 世界全体, type="o", pch=16))
r1 = lm(世界全体 ~ 年, data=df)
abline(r1, col="gray", lwd=2)
r2 = lm(世界全体 ~ 年 + I(年^2), data=df)
curve(r2$coefficients[1] + r2$coefficients[2] * x + r2$coefficients[3] * x^2,
col="#66ccff", lwd=2, add=TRUE)
r3 = lm(世界全体 ~ 年 + I(年^2) + I(年^3), data=df)
curve(r3$coefficients[1] + r3$coefficients[2] * x + r3$coefficients[3] * x^2 +
r3$coefficients[4] * x^3, col="#ff9900", lwd=2, add=TRUE)