R版PISA 2018データを読むのPython版である。
SPSSのsavデータを読むにはpandasの read_spss() でもできるが,これはpyreadstatパッケージを呼び出しているだけである。以下ではpyreadstatを直接使う:
import pyreadstat
メモリの多いマシンなら全部読み込んでしまうのが手っ取り早い(手元のマシンでは24分ほどかかった):
df, meta = pyreadstat.read_sav('CY07_MSU_STU_QQQ.sav')
dfは
import sys
sys.getsizeof(df)
とすればわかるように,約6Gのメモリを占める。
df.shape
と打ち込めば612004行1118列であることがわかる。
これ以降は次と同じである。
まずはメタデータだけ読んでみよう:
df, meta = pyreadstat.read_sav('CY07_MSU_STU_QQQ.sav', metadataonly=True)
メタデータに含まれる変数名とその説明を表示する(長い出力に注意!):
meta.column_names_to_labels
出力は次のようになる:
{'CNTRYID': 'Country Identifier',
'CNT': 'Country code 3-character',
'CNTSCHID': 'Intl. School ID',
'CNTSTUID': 'Intl. Student ID',
・・・(以下略)・・・
}
これでは見にくいので,JSON形式で保存しておくことにする:
import json
with open("column_names_to_labels.json", "w") as f:
json.dump(meta.column_names_to_labels, f, ensure_ascii=False, indent=2)
with open("variable_value_labels.json", "w") as f:
json.dump(meta.variable_value_labels, f, ensure_ascii=False, indent=2)
これらはそれぞれ変数ラベルとその説明,変数ラベルとその値の説明である。例えば "IC001Q01TA" というラベルについては前者が
"IC001Q01TA": "Available for you to use at home: Desktop computer",
後者が
"IC001Q01TA": {
"1.0": "Yes, and I use it",
"2.0": "Yes, but I don’t use it",
"3.0": "No",
"5.0": "Valid Skip",
"7.0": "Not Applicable",
"8.0": "Invalid",
"9.0": "No Response"
},
となっている。国名(3文字)とこの項目だけを改めて読み込んでみよう:
df, meta = pyreadstat.read_sav('CY07_MSU_STU_QQQ.sav', usecols=['CNT', 'IC001Q01TA'])
"IC001Q01TA" の回答の度数分布を表示する:
df["IC001Q01TA"].value_counts()
結果は
1.0 207182
3.0 97676
2.0 50529
となって順番通りにならない。value_counts(sort=False) としてもランダムな順序になる。そこで
df.groupby('IC001Q01TA').count()
とすると
CNT
IC001Q01TA
1.0 207182
2.0 50529
3.0 97676
のように表らしくなってくれる。あるいは別解として
import pandas as pd
pd.crosstab(df["IC001Q01TA"], "count") # "count" はダミー
とすると
col_0 count
IC001Q01TA
1.0 207182
2.0 50529
3.0 97676
になってくれるようだ。crosstab() の本来の使い方は
pd.crosstab(df["CNT"], df["IC001Q01TA"])
のようにして国名と回答の度数分布を
IC001Q01TA 1.0 2.0 3.0
CNT
ALB 3940 558 1589
AUS 6858 2406 2738
AUT 4797 626 972
BEL 5098 925 1585
BGR 3400 548 503
・・・後略・・・
のように出力することである。日本に限れば
df["IC001Q01TA"][df["CNT"] == "JPN"].value_counts()
# または df[df["CNT"] == "JPN"].groupby('IC001Q01TA').count()
とすればよい。
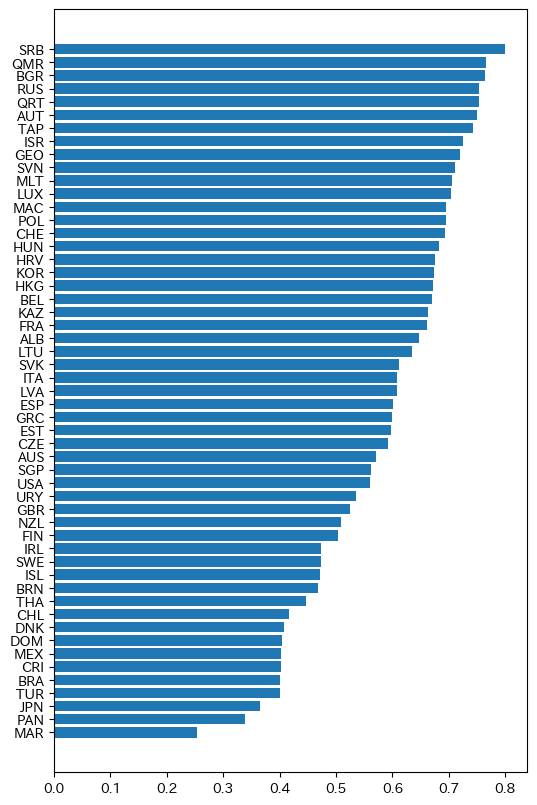
国ごとに回答1の割合を求めるには
s = pd.crosstab(df["CNT"], df["IC001Q01TA"]).apply(lambda x: x.iloc[0]/sum(x), axis=1)
s.sort_values(inplace=True)
手抜き棒グラフにする:
import matplotlib.pyplot as plt
plt.barh(s.index, s)
plt.savefig('191205a.png', bbox_inches="tight")
日本は下から3番目である。
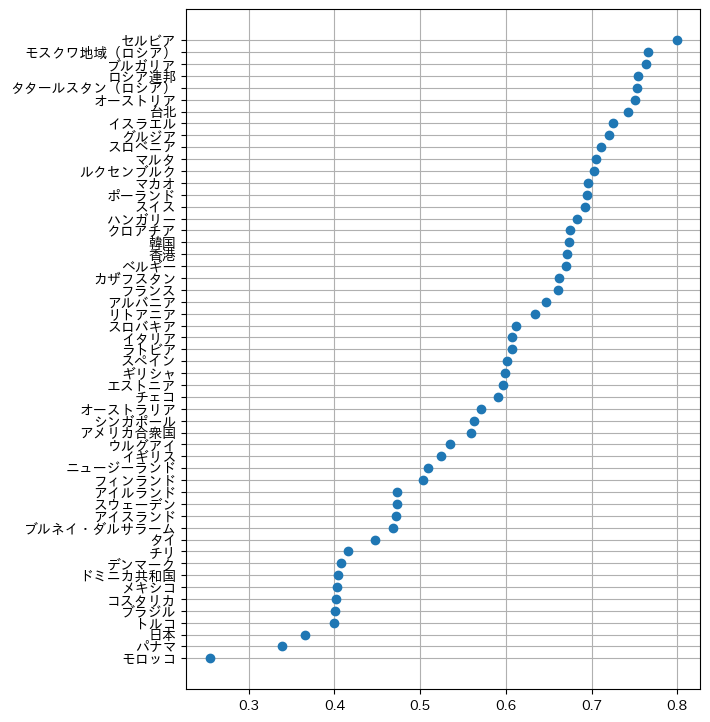
国名を日本語にし,ドットプロットにしてみる:
co = pd.read_csv("https://okumuralab.org/~okumura/stat/data/countries.csv")
dic = { r['三字']: r['国名'] for i,r in co.iterrows() }
cj = [ dic[x] for x in s.index ]
plt.plot(s, cj, "o")
plt.grid()
plt.savefig('191205b.png', bbox_inches="tight")
Last modified: