2015年5月17日,大阪都構想の住民投票が行われたが,賛成694844,反対705585の僅差で,大阪市の存続が決まった。
これらのデータの冗長な部分を除いたすべてを osaka2015.csv として置いておく(文字コードはUTF-8)。Rでの読み込みは次のようにしてできる。
osaka = read.csv("http://okumuralab.org/~okumura/stat/data/osaka2015.csv")
これだけでもいろいろグラフが描けるが,やはり区ごとの年齢構成が重要である。
このデータはExcelだがやや自動処理がしにくい。Hiroaki Yutaniさん(@yutannihilation)がCSV化してくださった:
これをダウンロードして,読み込む:
age = read.csv("osaka_age_composition.csv")
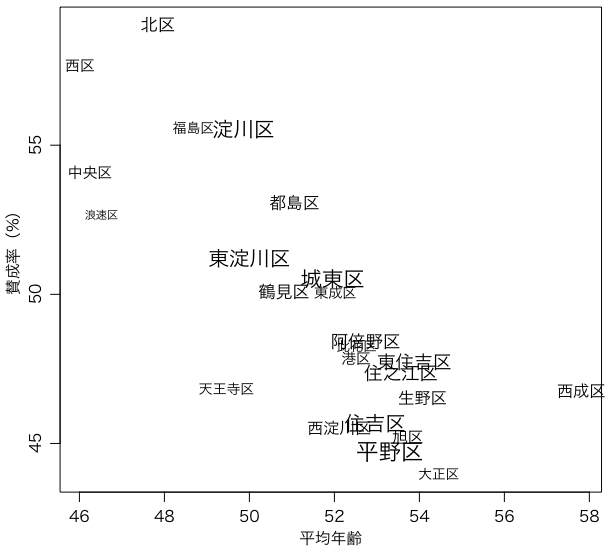
各区の20歳以上の平均年齢を求め,賛成率とともにプロットする:
ku = sub('区$', '', osaka$区名)
avg = function(i) {
a = subset(age, district == ku[i] & age >= 20)
sum(a$total * a$age) / sum(a$total)
}
avgage = sapply(1:24, avg)
par(mgp=c(2,0.8,0)) # 軸マージン(デフォルト: c(3,1,0))
par(xpd=TRUE) # グラフ領域を超えて文字を書く
with(osaka, plot(avgage, 100*賛成/(賛成+反対), xlab="平均年齢", ylab="賛成率(%)", pch=NA))
with(osaka, text(avgage, 100*賛成/(賛成+反対), 区名))
グラフは次のようになる。こういう図は,通常は原因と想定するものを横軸,結果と想定するものを縦軸にとる。ただし,当然ながら,たとえ相関関係があっても,因果関係が示されるわけではない。
最小2乗法で直線をあてはめて図に書き込みたいなら
r = with(osaka, lm(100*賛成/(賛成+反対) ~ avgage))
par(xpd=FALSE)
abline(r)
とすることが考えられる。ただし小さい区も大きい区も同じ重みでフィットするのではなく,投票数で重み付けするほうがよいだろう。
r = with(osaka, lm(100*賛成/(賛成+反対) ~ avgage, weights=賛成+反対))
さらに言えば,これはそもそも最小2乗法でフィットすべきデータではなく,2項分布を仮定して一般化線形モデル(ロジスティック回帰など)を使うべきかもしれない。いや,その場合も横軸の値は正確にわかっているべきで,平均年齢しかわかっていない場合には……。
……などとモデル化に凝るのもいいが,ここでは,モデルに依存する直線を引くのはやめて,上の図のように単に事実だけをプロットし,判断は見る人に任せることを選びたい。安易に直線を描くことの問題点は人口密度と出生率でも述べた。
同様の理由で,このような区ごとの平均値の相関係数
with(osaka, cor(賛成/(賛成+反対), avgage)) # -0.7921376
も,個人ごとの年齢・賛否の相関係数とはまったく異なるものであることに注意すべきである。
とはいうものの,このデータから,投票率と賛成率を性×年齢の関数として求めてみたいという気はするので,ちょっとつぶやいてみた:
大阪都の件,区×性×年齢データがあるのだから,投票率と賛成率を性×年齢の関数と見るロジスティックモデルを最尤推定する人はいないかな http://t.co/OswF5gZCE7
— Haruhiko Okumura (@h_okumura) 2015, 5月 24やってみたという人はまだおられないようだ。
ちなみに,平均でなく中央値を使いたいなら,上の avg を次のものに置き換える:
med = function(i) {
a = subset(age, district == ku[i] & age >= 20)
median(rep(a$age,a$total))
}
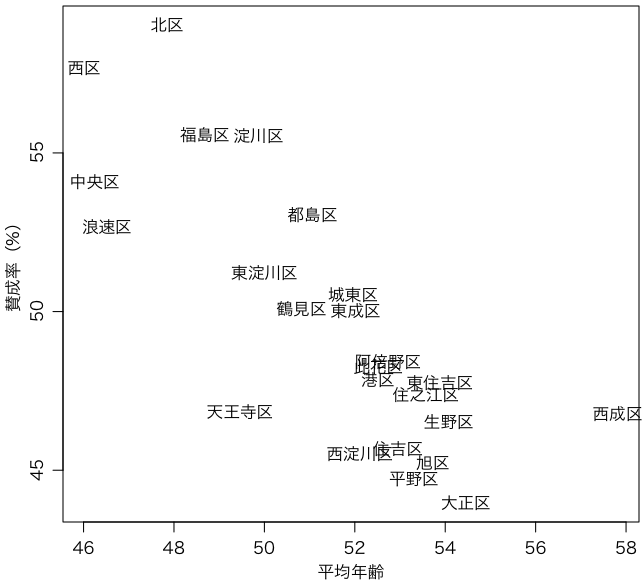
[追記] 次のように文字の大きさを投票者数の平方根に比例させるほうがよかったかもしれない。
with(osaka, text(avgage, 100*賛成/(賛成+反対), 区名, cex=sqrt((賛成+反対)/50000)))