e-StatのAPI
[2015-01-30] 政府統計の総合窓口(e-Stat)−API機能バージョン2.0の提供が始まった。以下は2.0に書き換えた。
[2015-12-21] 「からだにいいもの」にRで解析:政府統計の総合窓口(e-Stat)のAPIを利用したデータの取得例という記事が出たようだ(まだ読んでない)。
[2016-07-17] e-Stat APIバージョン2.1をRから使う,API 2.1になってCSVもどきが取れるようになったようだ。
はじめに
政府統計ポータル(e-Stat)と R でサンタさんの12月の出費動向を調べてみた - akiyoko blog はマウス操作の説明がほとんどなので,APIを使ってスマートにできないかと考え, WebAPI - e-Stat を使って統計情報を取得してみる - Qiita などを読んで勉強を始めた。しかし,R_Linux 師匠が RPubs - 政府統計の総合窓口(e-Stat)のAPIを使ってみる というすばらしい記事を書いてくださったので,することはなくなった。
とりあえず,なるべく重複がないようにメモしておく。
政府統計の窓口APIでデータを取得する
政府統計の総合窓口のデータをAPIで提供する次世代統計利用システムの試行運用が始まったのが2013年6月10日である。私もさっそく利用登録したが,そのままになっていた。
2014年10月31日にAPI機能の本格運用が始まった。詳細情報は上記サイトからe-Stat内の政府統計の総合窓口(e-Stat)-API機能のページに移った。登録情報も受け継がれた。2015年1月30日にはAPI 2.0が出た。
詳細はAPI仕様のページにあるPDFを読めばわかるはずだが,ざっくばらんにまとめておく。
APIで提供するデータはXMLまたはJSON形式である。元はXMLで,これをJSONにも変換しており,大きいデータをJSONで取得するとエラーになるらしい(ただし2.0時点では未確認)ので,今のところはXMLのほうがよさそうである。
まずは利用登録し,「アプリケーションID」なるものを取得しておく必要がある。以下ではアプリケーションIDを「XXXX」と記す。
全部Rで行うことも可能であるが,ここではMacまたはLinuxのターミナルでwgetを使ってファイルを取得する。まず,全データのリストをXMLで取得するには,ターミナルで次のように打ち込む:
wget http://api.e-stat.go.jp/rest/2.0/app/getStatsList?appId=XXXX
Rだけでやりたければ,次のようにする:
library(RCurl)
x = getURI("http://.....")
これで x にテキストが入る。ファイルにしたければこれを保存すればよい:
write(x, "filename")
Mac標準のcurlコマンドをwgetと同様に使うためには,~/.curlrc に次のように書き込んでおく:
--location
--remote-name-all
--remote-header-name
--remote-time
--xattr
これで curl http://..... と打ち込む。
うまくいけば60Mバイト強のXMLファイルが得られる。
全データのリストが必要なければ,提供データのページにあるものから選ぶ。例えば「国勢調査」の「政府統計コード」(statsCode)は 00200521 であるので,
wget 'http://api.e-stat.go.jp/rest/2.0/app/getStatsList?appId=XXXX&statsCode=00200521'
とする。ターミナルにこのような & を含むURLを打ち込む際には必ずクォートで囲む。
次のような形式でリストされている。
<TABLE_INF id="0003033021">
<STAT_NAME code="00200521">国勢調査</STAT_NAME>
<GOV_ORG code="00200">総務省</GOV_ORG>
<STATISTICS_NAME>平成22年国勢調査 速報集計 抽出速報集計</STATISTICS_NAME>
<TITLE no="00110">年齢(各歳),男女,国籍(総数及び日本人)別人口,平均年齢及び年齢中位数 全国,全国市部,全国郡部</TITLE>
<CYCLE>-</CYCLE>
<SURVEY_DATE>201010</SURVEY_DATE>
<OPEN_DATE>2011-06-29</OPEN_DATE>
<SMALL_AREA>0</SMALL_AREA>
<MAIN_CATEGORY code="02">人口・世帯</MAIN_CATEGORY>
<SUB_CATEGORY code="01">人口</SUB_CATEGORY>
<OVERALL_TOTAL_NUMBER>1980</OVERALL_TOTAL_NUMBER>
<UPDATED_DATE>2011-08-02</UPDATED_DATE>
</TABLE_INF>
これで「平成22年国勢調査 速報集計 抽出速報集計 年齢(各歳),男女,…」が0003033021というID(statsDataId)を持つことがわかる。これを取得するには次のようにターミナルに打ち込む:
wget 'http://api.e-stat.go.jp/rest/2.0/app/getStatsData?appId=XXXX&statsDataId=0003033021'
これをXMLでなくJSONで取得するには次のようにする:
wget 'http://api.e-stat.go.jp/rest/2.0/app/json/getStatsData?appId=XXXX&statsDataId=0003033021'
XMLはきれいにインデントされているが,JSONは全体が1行になっている上に,「全角」文字は \u6B63 のようにUnicodeの番号に変換されているので,人間が読むには不向きである。
XML/JSONをパースする
いろいろな手法のメモ:
- Rで統計API - 備忘録@かすみがおか:e-StatデータをRで素直にパースし,グラフを描いている
- R による XML の CSV 化 - なんとなくな Developer のメモ:e-StatデータをR(およびGroovy)のいろいろな方法でCSV化し,時間を比較している
- RPubs - 政府統計の総合窓口(e-Stat)のAPIを使ってみる:Rのjsonliteでパースし,データフレーム化している
- WebAPI - e-Stat を使って統計情報を取得してみる - Qiita:Pythonでe-StatのXMLをパースし,グラフを描いている
まず,R標準のデータフレーム形式に直し,CSVで書き出すところまでやってみる。さきほど得たXMLファイルを 0003033021.xml とする。実際のデータ行は <VALUE> ... </VALUE> で表されているので,まずは //VALUE を取得する。各行の属性は,男女が cat01,年齢階級が cat02 に,という具合に入っているが,属性値は 000,001 といったコードで表されており,例えば cat01 の各コードの意味は <CLASS_OBJ id="cat01"> ... </CLASS_OBJ> の中に入っており,001 の意味は <CLASS code="001" name="男" level="1"/> から「男」だとわかる。これらを組み合わせて元の表を復元しなければならない。けっこうややこしい作業である(最初からCSVで用意してくれればいいのに!)が,Rでは次のようにエレガントに書ける:
library(XML)
doc = xmlParse("0003033021.xml")
items = getNodeSet(doc, "//VALUE")
foo = function(x) {
n = getNodeSet(doc, paste0("//CLASS_OBJ[@id='", x, "']/CLASS"))
tbl = sapply(n, xmlGetAttr, "name")
names(tbl) = sapply(n, xmlGetAttr, "code")
tbl[sapply(items, xmlGetAttr, x)]
}
cat01 = foo("cat01")
cat02 = foo("cat02")
cat03 = foo("cat03")
area = foo("area")
time = foo("time")
value = as.numeric(sapply(items, xmlValue))
df = data.frame(cat01, cat02, cat03, area, time, value)
write.csv(df, file="0003033021.csv", row.names=FALSE)
JSONの場合も同様である。基本は次のようにしてデータフレームを得る。列名・属性名をコードから名前に変換する部分は省略する。
library("jsonlite")
json = fromJSON("0003033021.json")
df = json$GET_STATS_DATA$STATISTICAL_DATA$DATA_INF$VALUE
実際のデータ解析
以上でR標準のデータフレーム形式にできた。まず中を調べる:
> summary(df)
cat01 cat02 cat03 area
総数(男女別):660 総数(年齢): 18 総数(国籍):990 全国 :660
男 :660 0歳 : 18 日本人 :990 全国市部:660
女 :660 1歳 : 18 全国郡部:660
2歳 : 18
3歳 : 18
4歳 : 18
(Other) :1872
time value
2010年:1980 Min. : 43
1st Qu.: 78475
Median : 544500
Mean : 1606972
3rd Qu.: 897575
Max. :128056000
サブセットにしないと扱いにくい。
df1 = subset(df, cat01=="男" & cat03=="日本人" & area=="全国")
df2 = subset(df, cat01=="女" & cat03=="日本人" & area=="全国")
これで df1 の cat02(年齢)と value(値)をグラフにすればいいはずだが,cat02 を列挙してみると,こんな具合である:
> df1$cat02
[1] 総数(年齢) 0歳 1歳
[4] 2歳 3歳 4歳
……(中略)……
[100] 98歳 99歳 100歳以上
[103] 不詳 (再掲)15歳未満 (再掲)15~64歳
[106] (再掲)65歳以上 (再掲)75歳以上 (再掲)85歳以上
[109] (再掲)平均年齢 (再掲)年齢中位数
110 Levels: 総数(年齢) 0歳 1歳 2歳 3歳 4歳 5歳 6歳 7歳 8歳 9歳 10歳 ... (再掲)年齢中位数
「0歳」から「100歳以上」を取り出すには,配列の引数を [2:102] に限ればよい。まずは簡単なプロット(右端は「100以上」):
> plot(0:100, df2$value[2:102], type="o", xlab="Age", ylab="Population")
> points(0:100, df1$value[2:102], pch=16, type="o")
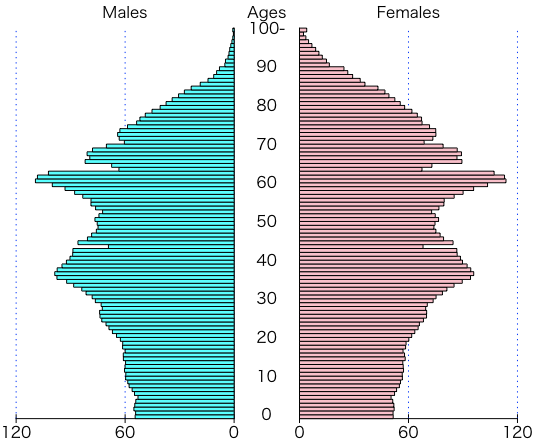
きれいな人口ピラミッドを描くには,中澤 港 先生の pyramid パッケージを使う(横軸の単位は「万人」):
> install.packages("pyramid")
> library(pyramid)
> pyramids(df1$value[2:102]/10000, df2$value[2:102]/10000, c(0:99,"100-"), Cstep=10, Laxis=c(0,60,120))