[2020-01-21追記] このページの最初のグラフと同じもの(都道府県名がなくマーカーだけの散布図)が2020-01-19の大学入試センター試験「数学I」「数学I・数学A」に出た。いっしょに出ている「男の市区町村別の平均寿命の箱ひげ図」は厚労省平成27年市区町村別生命表の概況からリンクされている ckts15-06.xls のデータを描いたものと思われる。この箱ひげ図の中で際立って長い「P10」は大阪府である(大阪市西成区の男の平均寿命73.5歳)。
[2020-01-24追記] 上記Excelファイルをパースするのはかなり面倒。裏 RjpWiki さんのこの記事参照。また,センター試験に出てきた平均寿命の箱ひげ図をExcelとPythonで作ってみるにも書かれているように,e-Statのこちらのページにある Excel ファイルから0歳の余命をとるほうが楽かもしれない。
今日(2018-04-02)の日経新聞に地域格差、最大で3.1歳という記事があった。「平均寿命の延びは都道府県で格差がある」と題した図が付いており,都道府県別平均寿命(男女合計)を,横軸に1990年,縦軸に2015年をとってプロットしてある。「東京大学大学院国際保健政策学教室のデータをもとに作成」と書かれているが,e-Statか厚労省のデータに違いない。e-Statを探したが見つからず(要確認),厚労省を探すと平成27年都道府県別生命表の概況というページがあった。ここに「図表データのダウンロード」という項目があり,Excelファイル tdfk15-09.xls がダウンロードできるようになっている(デフォルト .xls な Excel 2003 は2014年4月9日にサポート終了したはずだが・・・)。
このExcelファイルのシート「表5-1」に平均寿命の推移(男),「表5-2」に平均寿命の推移(女)が載っている(年が元号だけで書かれている!)。「表5-1」では,平成27年(2015年)の都道府県・平均寿命はセル範囲 T7:U54 に書き込まれている(途中に空行があるが,これは平成7年(1995年)の兵庫県に括弧書きの数値を付けたためである。これもまずいやり方だ)。これをRで読み出そう:
library(readxl)
m2015 = read_excel("tdfk15-09.xls", "表5-1", "T7:U54", col_names=FALSE)
不完全な行(空行など)を削除する:
m2015 = na.omit(m2015)
都道府県はJIS順(北海道〜沖縄)ではなく,年ごとに平均寿命の長い順に並べてある。しかも,都道府県名をよく見ると,「滋 賀」や「長 野」のように,途中に全角空白が入ったものが多い。「均等割り」のつもりだろうが,このような空白は外す必要がある:
m2015[[1]] = sub(" ", "", m2015[[1]])
これでデータクレンジング完了である。「表5-2」の2015年女も同様に行う。こちらにも空行はあるが,たまたま最下行なので,気にしなくてよい:
f2015 = read_excel("tdfk15-09.xls", "表5-2", "T7:U53", col_names=FALSE)
f2015[[1]] = sub(" ", "", f2015[[1]])
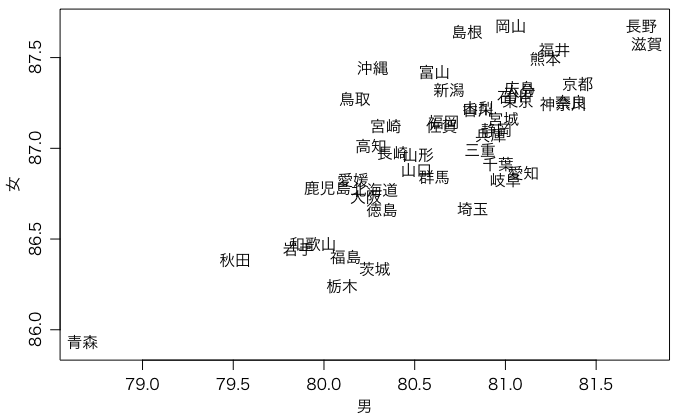
まず,これらをマージして,男を横軸,女を縦軸にとって,プロットしてみる:
a = merge(m2015, f2015, by.x=1, by.y=1)
par(mgp=c(2,0.8,0)) # 軸マージン(デフォルト: c(3,1,0))
plot(a[[2]], a[[3]], type="n", xlab="男", ylab="女", asp=1)
text(a[[2]], a[[3]], a[[1]])
日経の記事では1990年と比較しているが,厚労省のデータにないので,平成7年(1995年)を使うことにする:
m1995 = read_excel("tdfk15-09.xls", "表5-1", "K7:L54", col_names=FALSE)
m1995 = na.omit(m1995)
m1995[[1]] = sub(" ", "", m1995[[1]])
f1995 = read_excel("tdfk15-09.xls", "表5-2", "K7:L53", col_names=FALSE)
f1995[[1]] = sub(" ", "", f1995[[1]])
b = merge(m1995, f1995, by.x=1, by.y=1)
さきほどと同様に1995年だけプロットしてもいいのだが,1995年と2015年を同時にプロットするほうがおもしろい。
plot(c(a[[2]],b[[2]]), c(a[[3]],b[[3]]), type="n", xlab="男", ylab="女", asp=1)
text(b[[2]], b[[3]], b[[1]], col="blue")
text(a[[2]], a[[3]], a[[1]])
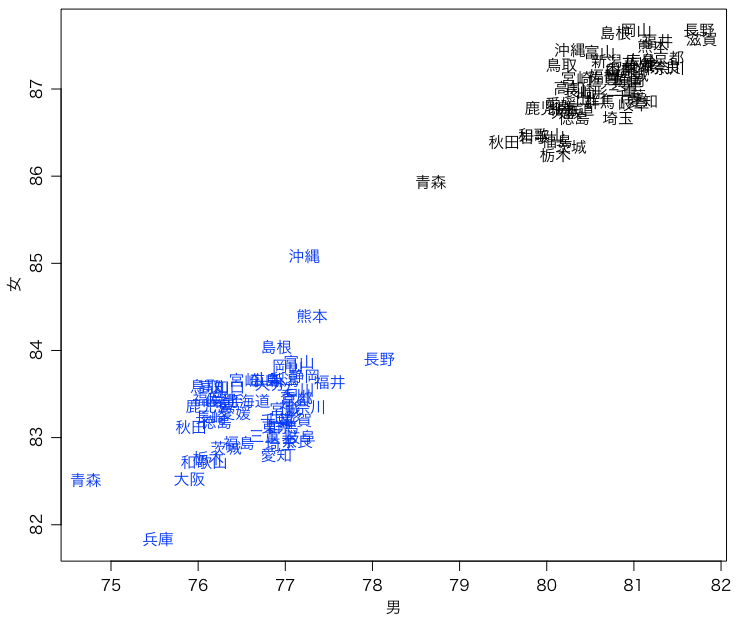
青が1995年である。2015年の最悪の都道府県でも,1995年の最良の都道府県よりずっと良いことがわかる。また,都道府県の分散も小さくなっているように見える。
日経のグラフに近いものは,次のようにして描ける。ただし,ここでは男女の人数比を考えず単純平均した:
a[[4]] = (a[[2]] + a[[3]]) / 2
b[[4]] = (b[[2]] + b[[3]]) / 2
c = merge(a, b, by.x=1, by.y=1)
plot(c[[7]], c[[4]], type="n", xlab="1995年", ylab="2015年", asp=1)
text(c[[7]], c[[4]], c[[1]])
abline(v=(76.70+83.22)/2)
abline(h=(80.77+87.01)/2)
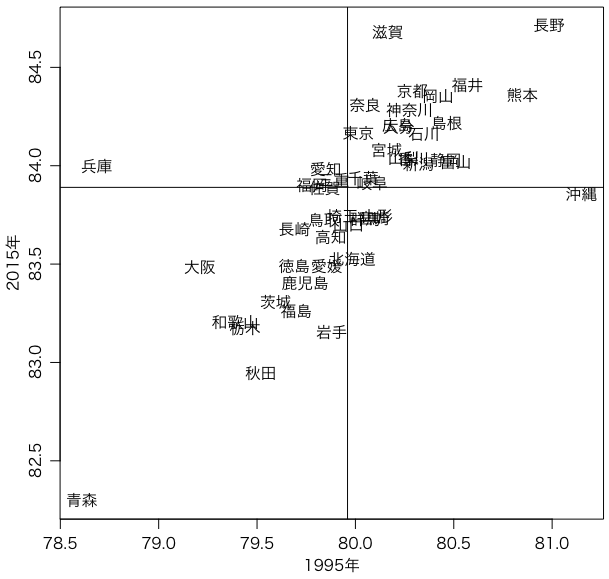
日経の図とは,やや印象が違うようだ。なぜだろう?
「日経の図とは,やや印象が違うようだ。なぜだろう?」と書いたところ,日経のデータは Nomura et al. から取ったものではないかと教えていただいた。その supplementary appendix(PDF)に1990年・2015年のデータが載っているようだ。
PDFからデータを取り出すには,いろいろな方法があるだろうが,ここでは pdftotext コマンドを使ってテキスト化してRubyスクリプトで整形する方法を使う。
pdftotext -raw mmc1.pdf
とすると,mmc1.txt というテキストファイルが生成される。その中の「Web Table 2」あたりの下の「Japan」という行から「B (Men)」の直前までを切り出して,次の「やっつけ」RubyスクリプトでCSV化する:
#! /usr/bin/env ruby -w
# coding: utf-8
print "Pref,M1990,M2015,Mchange,L1990,L2015,Lchange,H1990,H2015,Hchange"
while line = gets
next if line =~ /\x0C/
line.strip!
line.gsub!(/·/, ".")
line.gsub!(/Ô/, "O")
line.gsub!(/ +/, ",")
if line =~ /^[A-Z]/
print "\n", line
elsif line =~ /^[^(]/
print ",", line
end
end
puts
同様なものが3組あり,それぞれ「A (Both sexes combined)」「B (Men)」「C (Women)」となっている。念のため,生成したCSVファイルを mmc1WT2A.csv, mmc1WT2B.csv, mmc1WT2C.csv として置いておく。これを使ってプロットしてみる:
x = read.csv("mmc1WT2A.csv", as.is=TRUE)
kenmei = c("北海道", "青森", "岩手", "宮城", "秋田", "山形", "福島", "茨城",
"栃木", "群馬", "埼玉", "千葉", "東京", "神奈川", "新潟", "富山",
"石川", "福井", "山梨", "長野", "岐阜", "静岡", "愛知", "三重",
"滋賀", "京都", "大阪", "兵庫", "奈良", "和歌山", "鳥取", "島根",
"岡山", "広島", "山口", "徳島", "香川", "愛媛", "高知", "福岡",
"佐賀", "長崎", "熊本", "大分", "宮崎", "鹿児島", "沖縄")
y = data.frame(kenmei, x[-1,])
plot(y$L1990, y$L2015, type="n", xlab="1990年", ylab="2015年", asp=1)
text(y$L1990, y$L2015, y$kenmei)
abline(v=x$L1990[1])
abline(h=x$L2015[1])
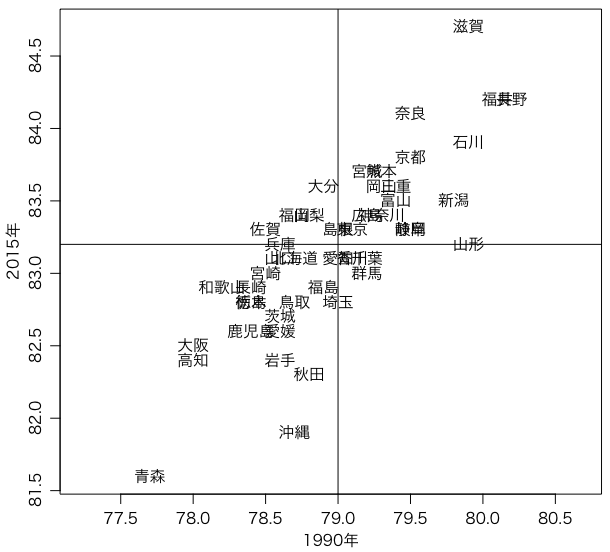
これで日経の図とほぼ同じになった(日経の図は残念ながら asp=1(アスペクト比を1にする)に相当することをしていないので,これを縦に潰したような図になってしまっている)。