Spurious Correlations のようなネタは多い。時系列データの相関係数について書かなきゃ,と思っていたところに,裏RjpWikiに時系列データと時間の相関についてという記事が出たので,私もやってみた。
要は,時系列データは rnorm(n) のようなホワイトノイズではなく,cumsum(rnorm(n)) のようなランダムウォークに近いので,大きな相関係数が出やすくなる。
sim1 = function(n=40) { x = rnorm(n); y = rnorm(n); cor(x, y) }
sim2 = function(n=40) { x = cumsum(rnorm(n)); y = cumsum(rnorm(n)); cor(x, y) }
r1 = replicate(1000000, sim1())
r2 = replicate(1000000, sim2())
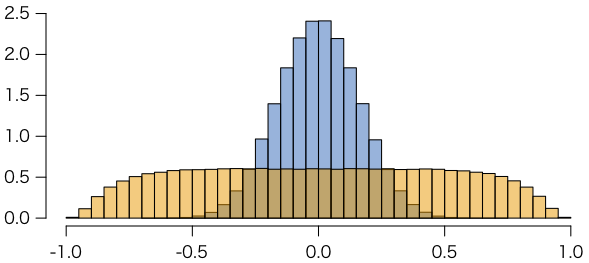
hist(r1, col="#0068b780", freq=FALSE, xlim=c(-1,1), xlab="", ylab="", main="")
hist(r2, col="#f3980080", freq=FALSE, add=TRUE, breaks=40, xlab="", ylab="", main="")
横軸が相関係数,青はホワイトノイズ,オレンジはランダムウォークである。
実際の時系列データはさらに長期のトレンドがある(例えばインターネットの普及率は増え続ける)。したがって,大きな相関係数はこれよりさらに出やすくなるであろう。なお,上記の裏RjpWiki記事は片方が完全にトレンドだけのデータ x = 1:n である。