CSVファイルの作法 もご参照ください。
e-Statで2020年11月25日から12月1日まで意見照会されていた「統計表における機械判読可能なデータ作成に関する表記方法案」が2020年12月18日に統計表における機械判読可能なデータの表記方法について(←リンク切れ)の統計表における機械判読可能なデータ作成に関する表記方法(PDF、2020-12-17作成)にまとめられた。また、総務省の統計表における機械判読可能なデータの表記方法の統一ルールの策定(2020-12-18)からも統計表における機械判読可能なデータ作成に関する表記方法(PDF、2020-12-16作成)がリンクされたが、これら2つは実質同じもののようである。e-Statには2020-12-25付で「統計表における機械判読可能なデータの表記方法」に関する 「政府統計の総合窓口(e-Stat)」の機能改修についてというページができ、そこからも上記PDF(2020-12-16作成)がリンクされている。これらを引用しつつ、コメントする。
なお、これらのPDFには「第1章 機械判読可能なデータの作成 ~Excel 形式による統計表の作成~」しかない。
Excelならxlsではなくxlsx形式にすべきことや、パーマリンクを付けてほしいことを、意見照会では書いたが、反映されなかった。なお、CSVの文字コードは現在はShift JISが多いが、今後は国際化を考えてUTF-8にするべきである。本来ならBOMなしUTF-8が望ましいが、日本語環境のExcelはBOMなしUTF-8で文字化けするので、当面はBOM付きUTF-8を許容する。なお、JSONはBOMなしUTF-8にしなければならない。
[追記] パーマリンクについては、e-Statでユーザ登録してログインした状態でダウンロードしたデータはダッシュボードの「ダウンロード履歴」に表示されるが、そのURLを(データのランディングページの)パーマリンクと考えてよいということを教えていただいた。詳しくは e-Stat 参照。
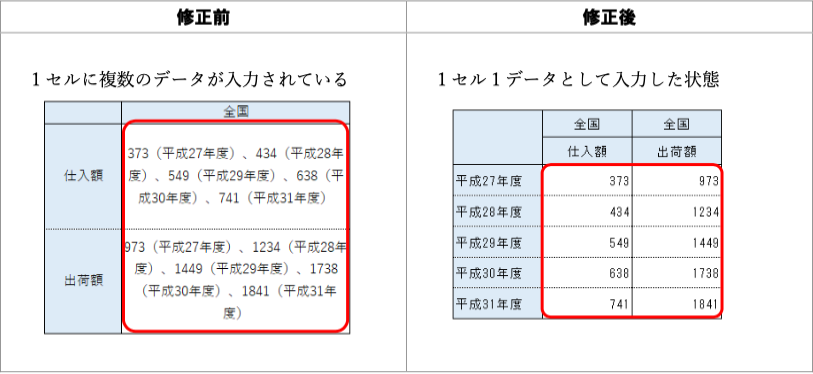
改善案:セル結合や2行のヘッダは避けたい。最初の列には「年度」という列名が欲しい。年度は西暦で単位なしにしたい。
| 年度 | 仕入額 | 出荷額 |
|---|---|---|
| 2015 | 373 | 973 |
| 2016 | 434 | 1234 |
| 2017 | 549 | 1449 |
| 2018 | 638 | 1738 |
| 2019 | 741 | 1841 |
上と同じ形のExcelファイルを tables-1-2-ex1.xlsx として置いておく。このExcelファイルはPythonで簡単に読める:
import pandas as pd
df = pd.read_excel("https://okumuralab.org/~okumura/python/data/tables-1-2-ex1.xlsx")
df
年度 仕入額 出荷額
0 2015 373 973
1 2016 434 1234
2 2017 549 1449
3 2018 638 1738
4 2019 741 1841
このページにあるHTMLの表をPythonでスクレイプするのも、同様に簡単である:
tables = pd.read_html("https://okumuralab.org/~okumura/python/tables.html")
tables[0]
年度 仕入額 出荷額
0 2015 373 973
1 2016 434 1234
2 2017 549 1449
3 2018 638 1738
4 2019 741 1841
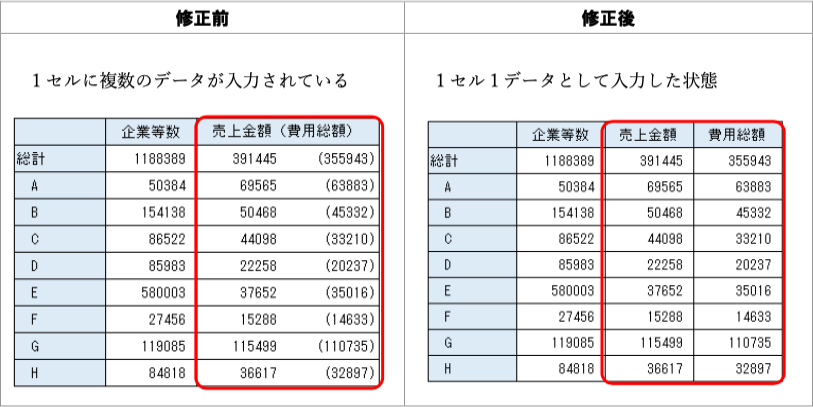
改善案:最初の列に列名が欲しい。項目名のスペースによるインデントは避ける(これは下のチェック項目1-5の例2で書かれている)。「総計」は計算できるので、なくてもよい。
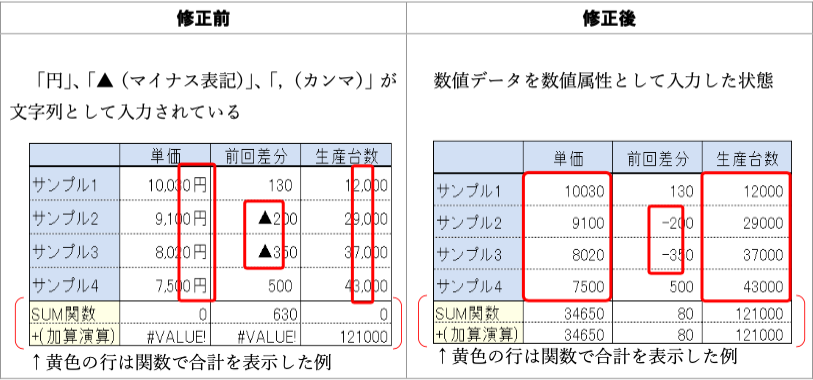
改善案:最初の列に列名が欲しい。
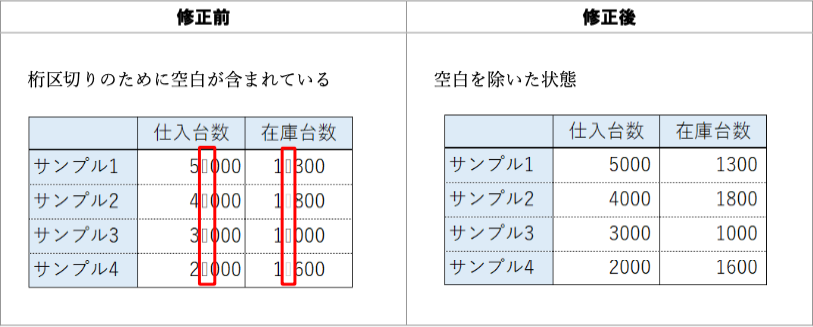
改善案:最初の列に列名が欲しい。
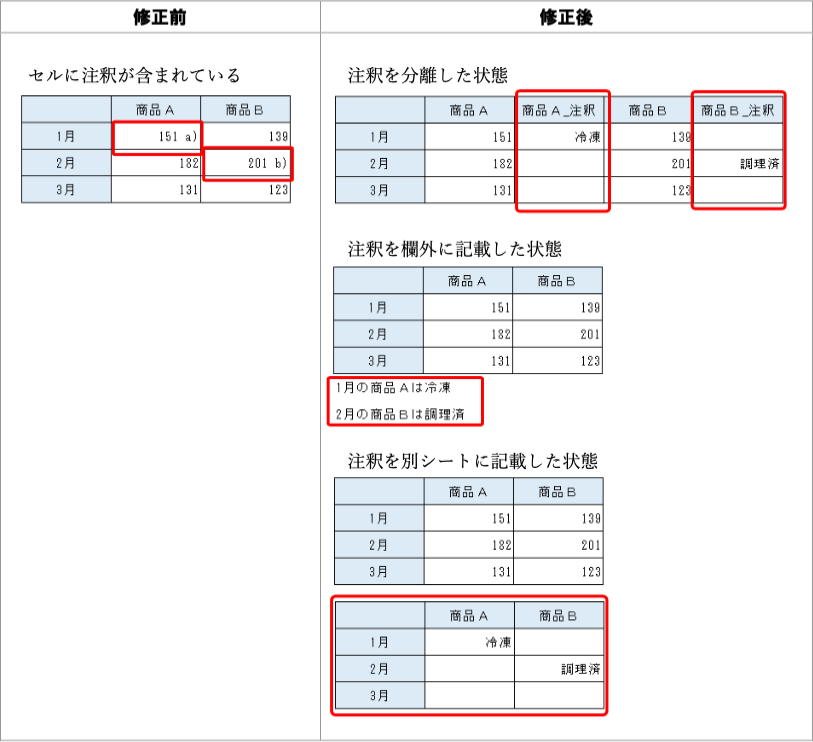
改善案:最初の列に列名が欲しい。「1月」「2月」「3月」は2019-01、2019-02、2019-03のように年を併記するほうがわかりやすい(いずれにしても数値に「月」などは付けない)。「商品A」は「商品A」のようにいわゆる半角で統一したい。
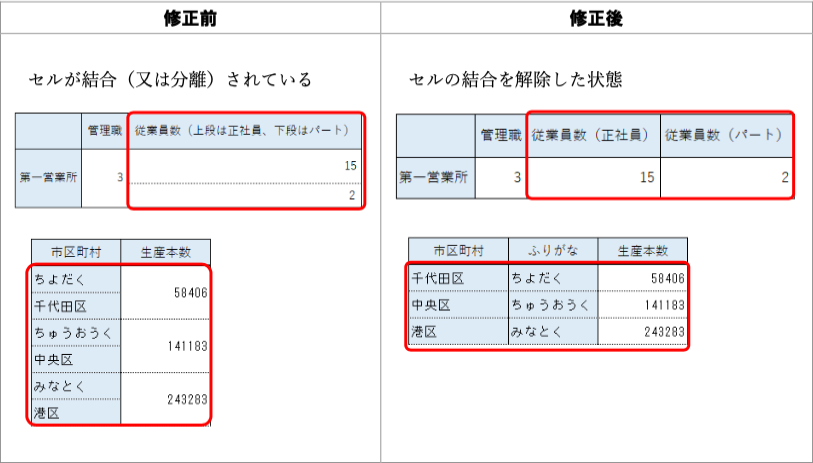
改善案:最初の列に列名が欲しい。
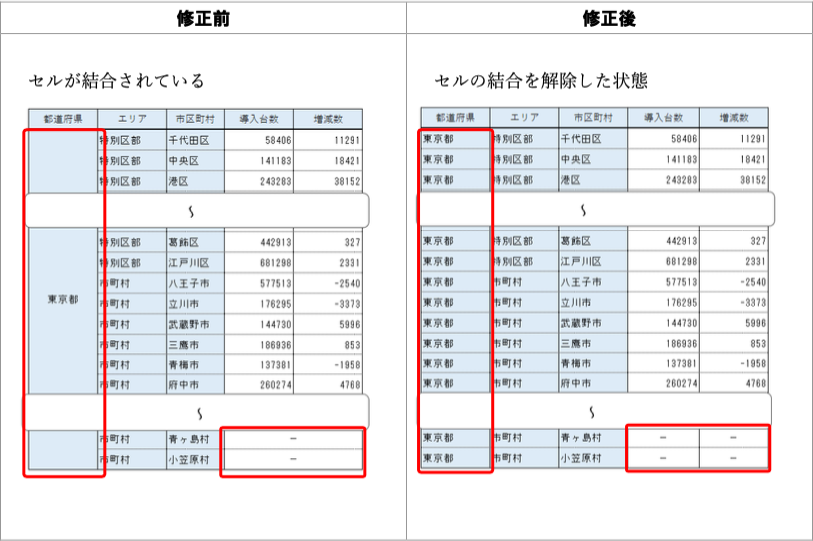
改善案:欠測値を表すのに「−」が使われているが、「−」と区別がつきにくい文字がたくさんあり、不統一を招きかねない。欠測値を表す方法については下の「チェック項目1-13」とその改善案を参照されたい。
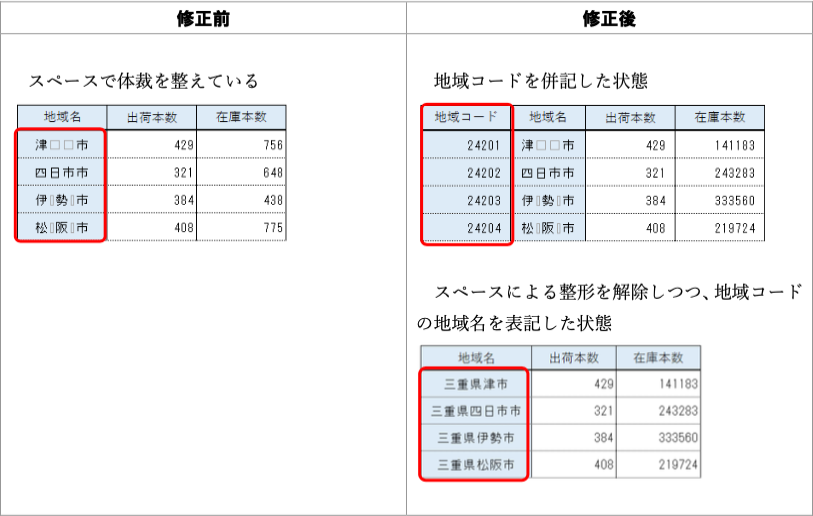
改善案:地域コードを併記してもスペースによる整形は好ましくない。どうしても整形したいなら、Excelのセルの書式設定→配置→水平方向の配置を「均等割り付け(インデント)」とし、インデント幅(左右の空き)を適宜設定する。
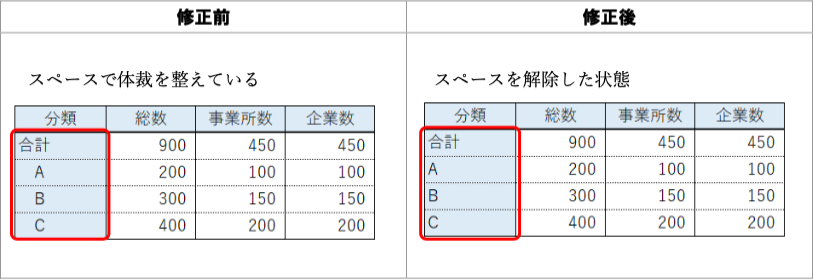
改善案:「合計」はなくてもよい。
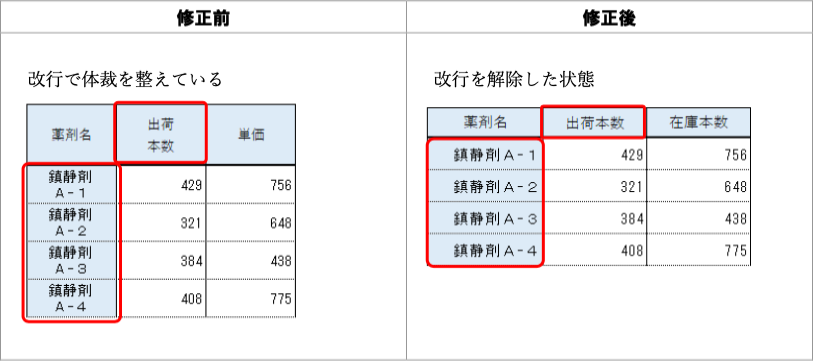
改善案:可能ならば全角「A-1」などはいわゆる半角(ASCIIの範囲)の「A-1」などで統一する。
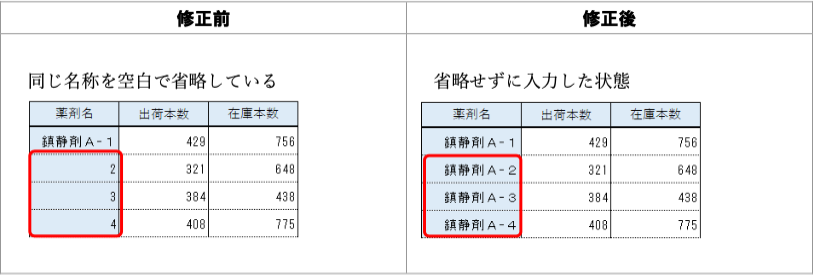
改善案:同上。なお、「〃」のような省略記号を使わないようにということも入れたらよいのではないかというご提案をツイッターでお聞きした。
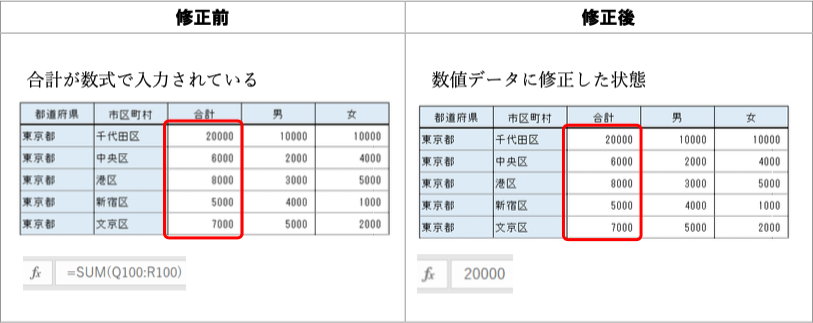
改善案:なし。

改善案:可能ならば全角は半角に統一する。
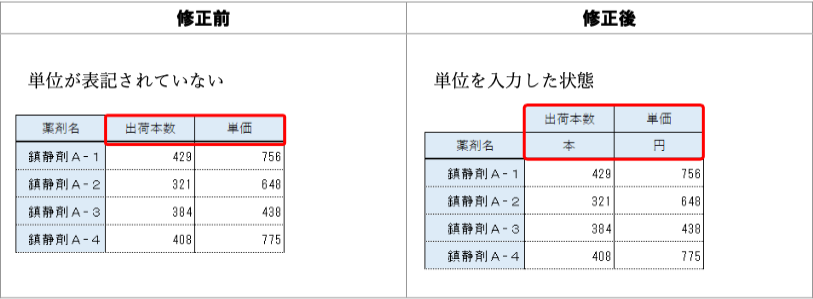
改善案:ヘッダ行は1行に統一する。単位は括弧書きにするか、別の説明文に入れる。
| 薬剤名 | 出荷本数(本) | 単価(円) |
|---|---|---|
| 鎮静剤A-1 | 429 | 756 |
| 鎮静剤A-2 | 321 | 648 |
| 鎮静剤A-3 | 384 | 438 |
| 鎮静剤A-4 | 408 | 775 |
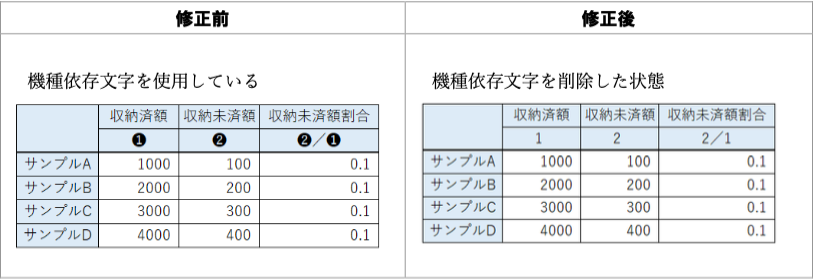
改善案:「機種依存文字」というのはShift JIS時代の名残りであり、Unicodeでは「機種依存文字」は事実上存在しないと考えてよい。必要に応じてどんな文字でも使ってかまわない。ただ、入力のしやすさを考えれば、簡単な文字で済ませるほうがよい。1や2は数値のように見えるのでaやbとする。
| 品名 | 収納済額(a) | 収納未済額(b) | 収納未済額割合(b/a) |
|---|---|---|---|
| サンプルA | 1000 | 100 | 0.1 |
| サンプルB | 2000 | 200 | 0.1 |
| サンプルC | 3000 | 300 | 0.1 |
| サンプルD | 4000 | 400 | 0.1 |
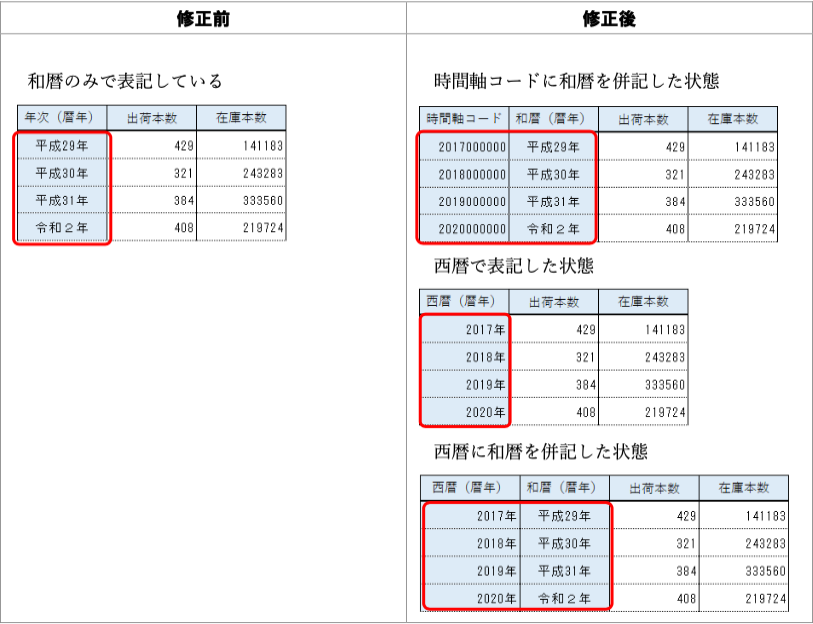
改善案:e-Statの時間軸コードはそのままではRやPythonで扱えないので、特に理由がない限り、通常の日付表記(2020、2020-12、2020-12-31など)に統一していただければありがたい。あるいは年と月を別の行にしてもよい。いずれにしても数値に「年」などは付けない。「2006年度4〜9月期」のような複雑な場合は、幅が一定(半期ごと)であれば始値「2006-04」だけ、幅が不定であれば始値と幅または始値と終値の2欄に分ける。
| 年 | 出荷本数 | 在庫本数 |
|---|---|---|
| 2017 | 429 | 141183 |
| 2018 | 321 | 243283 |
| 2019 | 384 | 333560 |
| 2020 | 408 | 219724 |
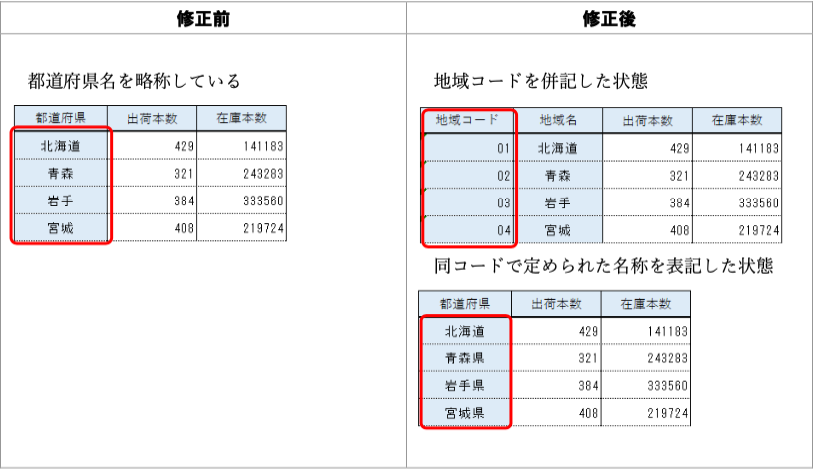
改善案:なし。
「集計した結果がゼロ、表章桁未満」は 0、「集計に必要なデータがない」は ***、「秘匿データ」は X で表す。

改善案:欠測値を *** で表すのは、それで統一されていれば問題ないが、Excelでグラフを描く場合に 0 と扱われる点に注意しなければならない。別の案として、ExcelでもPython(pandas)でも欠測値の意味になる #N/A はどうか。CSVの場合は # 以下がコメントと解釈されないように "#N/A" のようにダブルクォートで囲む。Excelで合計や平均を求める際には =SUMIF(範囲,"<>#N/A") や =AVERAGEIF(範囲,"<>#N/A") のようにして計算する。
| 都道府県 | サンプル1 | サンプル2 |
|---|---|---|
| 北海道 | 52954 | 44940 |
| 青森県 | #N/A | #N/A |
| 岩手県 | 6566 | 5933 |
| 宮城県 | #N/A | #N/A |
tables = pd.read_html("https://okumuralab.org/~okumura/python/tables.html")
tables[4]
都道府県 サンプル1 サンプル2 0 北海道 52954.0 44940.0 1 青森県 NaN NaN 2 岩手県 6566.0 5933.0 3 宮城県 NaN NaN
ほかに(特にRで読む場合は)NA もよく使われる。-(U+002D HYPHEN-MINUS)を使ってもいいが、‐(U+2010 HYPHEN)、—(U+2014 EM DASH)、―(U+2015 HORIZONTAL BAR)、−(U+2212 MINUS SIGN)、─(U+2500 BOX DRAWINGS LIGHT HORIZONTAL)、ー(U+30FC KATAKANA-HIRAGANA PROLONGED SOUND MARK)、一(U+4E00 漢数字の「一」)、-(U+FF0D FULLWIDTH HYPHEN-MINUS)などの類似文字が多いので気を付ける。
ところでこの最後のデータだが、次のように縦長にするほうがよいことが多い(データの整然化 参照)。
| 地域 | サンプル | 個数 |
|---|---|---|
| 北海道 | 1 | 52954 |
| 北海道 | 2 | 44940 |
| 岩手県 | 1 | 6566 |
| 岩手県 | 2 | 5933 |
Last modified: