Fisher の有名な「あやめ」(iris、アイリス)のデータをプロットしてみます。データは Seaborn にも入っていますが、ここでは後で scikit-learn を使うので、そちらからロードします:
from sklearn.datasets import load_iris iris = load_iris()
ざっとプロットしてみます:
import matplotlib.pyplot as plt plt.scatter(iris.data[:,0], iris.data[:,1], c=iris.target)
もっと丁寧に:
markers = ['o', '^', 'v']
for i in range(3):
d = iris.data[iris.target == i, :]
plt.plot(d[:,0], d[:,1], 'o', fillstyle='none', marker=markers[i])
plt.xlabel('sepal length (cm)')
plt.ylabel('sepal width (cm)')
plt.legend(iris.target_names)
印刷用には 'o' を 'ko' にすれば黒になります。
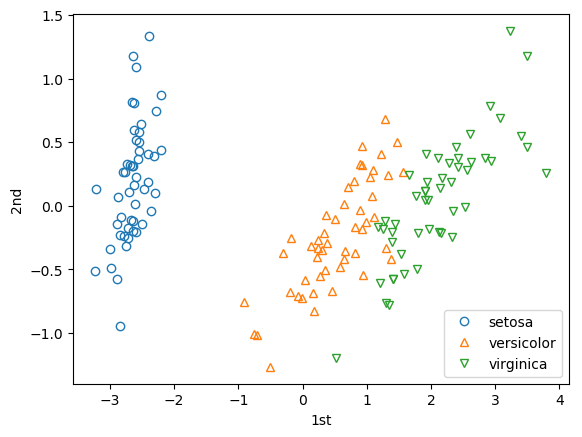
主成分分析(PCA)で2次元にしてからプロットしてみます:
from sklearn.decomposition import PCA
x = PCA(n_components=2).fit_transform(iris.data)
for i in range(3):
d = x[iris.target == i, :]
plt.plot(d[:,0], d[:,1], 'o', fillstyle='none', marker=markers[i])
plt.xlabel('1st')
plt.ylabel('2nd')
plt.legend(iris.target_names)
次のようにすれば主成分ごとの分散の割合がわかります:
pca = PCA(n_components=2) x = pca.fit_transform(iris.data) pca.explained_variance_ratio_
出力は array([0.92461872, 0.05306648]) のようになります。第1主成分92%、第2主成分5%ほどの寄与があります。
PCAする前に変数ごとに標準化するか、あるいはここの「Scaling vs Whitening」にあるように PCA(n_components=2, whiten=True) するといいかもしれません。標準化は次のようにします:
from sklearn import preprocessing t = preprocessing.scale(iris.data) x = PCA(n_components=2).fit_transform(t)
3次元ならどうなるでしょうか:
x = PCA(n_components=3).fit_transform(iris.data)
fig, ax = plt.subplots(figsize=(10,10), subplot_kw=dict(projection="3d"))
ax.scatter(x[:,0], x[:,1], x[:,2], c=iris.target)
ax.set_xlabel("1st")
ax.set_ylabel("2nd")
ax.set_zlabel("3rd")
対話型の環境なら、マウスでぐりぐりできます。
from sklearn.tree import DecisionTreeClassifier, export_graphviz
model = DecisionTreeClassifier(max_depth=3)
model.fit(iris.data, iris.target)
export_graphviz(model, "tree.dot",
feature_names=iris.feature_names,
class_names=iris.target_names)
これで tree.dot というテキストファイルができます。これを画像に変換するには Graphviz を使います。Mac へのインストールは brew install graphviz でできます。Graphviz の dot コマンドを使っていろいろな画像に変換できます:
dot -Tpng tree.dot -o tree.png dot -Tpdf tree.dot -o tree.pdf dot -Tsvg tree.dot -o tree.svg

Seaborn の iris データはデータフレームの形になっていますが、scikit-learn のものをデータフレームにするには次のようにする必要があります:
import pandas as pd df = pd.DataFrame(iris.data, columns=iris.feature_names) df['species'] = iris.target # または df['species'] = iris.target_names[iris.target]
次のようなことを試してみてください。
df.shape
df.info()
df.head()
df.describe()
df.isnull().sum() # 列ごとの欠測値の数を調べる
df.groupby('species').size()
df.corr()