2019年7月31日に,平成31年度全国学力テスト(正確には「全国学力・学習状況調査」)の結果が国研のこのページで公開された。例によって都道府県別平均正答率(%)は丸めて整数にしてある。そこで,都道府県ごとの正答数の度数分布のExcelファイルから精密な正答率を求めてCSV形式にした。
まず,報告書・調査結果資料からリンクされているファイル群を全部ダウンロードする(これはPythonではなくUNIXのコマンドである)。実際に全部を使うわけではないので,もっと絞ることも可能であるが,とりあえず:
wget --timestamping --recursive --no-parent --wait=1 \
https://www.nier.go.jp/19chousakekkahoukoku/index.html
必要なファイル名のリストを得るには pathlib と正規表現ライブラリ re を使う:
import pathlib, re
path = pathlib.Path("www.nier.go.jp/19chousakekkahoukoku/factsheet/19prefecture-City")
names = sorted([p for p in path.glob("**/*.xlsx") if re.search(r"/\d\dp_19r\.xlsx$", str(p))])
まず小学校についてExcelファイルを読んで平均正答率を計算する:
from openpyxl import load_workbook
import numpy as np
def f(n):
wb = load_workbook(n, read_only=True)
ws = wb.worksheets[0]['AE8:AE22']
n = len(ws)
x = np.array([ws[i][0].value for i in range(n)])
koku = (x @ np.arange(n)[::-1]) / np.sum(x) * (100 / (n-1))
ws = wb.worksheets[1]['AE8:AE22']
n = len(ws)
x = np.array([ws[i][0].value for i in range(n)])
san = (x @ np.arange(n)[::-1]) / np.sum(x) * (100 / (n-1))
return [koku, san]
sho = np.array([f(n) for n in names])
同様に中学校も:
names = sorted([p for p in path.glob("**/*.xlsx") if re.search(r"/\d\dm_19r\.xlsx$", str(p))])
def f(n):
wb = load_workbook(n, read_only=True)
ws = wb.worksheets[0]['AE8:AE18']
n = len(ws)
x = np.array([ws[i][0].value for i in range(n)])
koku = (x @ np.arange(n)[::-1]) / np.sum(x) * (100 / (n-1))
ws = wb.worksheets[1]['AE8:AE24']
n = len(ws)
x = np.array([ws[i][0].value for i in range(n)])
suu = (x @ np.arange(n)[::-1]) / np.sum(x) * (100 / (n-1))
ws = wb.worksheets[2]['AE8:AE29']
n = len(ws)
x = np.array([ws[i][0].value for i in range(n)])
ei = (x @ np.arange(n)[::-1]) / np.sum(x) * (100 / (n-1))
return [koku, suu, ei]
chu = np.array([f(n) for n in names])
水平方向に結合する:
shochu = np.hstack((sho, chu))
CSV形式で保存(Excelや「メモ帳」で文字化けしないようにBOM付きUTF-8,行末CRLF):
import pandas as pd
pd.DataFrame(shochu).to_csv("atest2019.csv", index=False,
encoding="utf_8_sig", line_terminator="\r\n",
header=["小国","小算","中国","中数","中英"])
結果は atest2019.csv として置いておく。
都道府県名は特に付けていない。必要なら次のリストを使う:
kenmei = ["北海道", "青森県", "岩手県", "宮城県", "秋田県", "山形県",
"福島県", "茨城県", "栃木県", "群馬県", "埼玉県", "千葉県", "東京都",
"神奈川県", "新潟県", "富山県", "石川県", "福井県", "山梨県", "長野県",
"岐阜県", "静岡県", "愛知県", "三重県", "滋賀県", "京都府", "大阪府",
"兵庫県", "奈良県", "和歌山県", "鳥取県", "島根県", "岡山県", "広島県",
"山口県", "徳島県", "香川県", "愛媛県", "高知県", "福岡県", "佐賀県",
"長崎県", "熊本県", "大分県", "宮崎県", "鹿児島県", "沖縄県"]
ついでに,各科目の正答数分布(全国,国・公・私立)をリストの形で挙げておく。それぞれ正答数0問,1問,2問,…の生徒(児童)数を並べたものである:
mkokugo = [6341, 15894, 25438, 36646, 50880, 69370, 95185, 127786,
166953, 203279, 179498]
msuugaku = [8047, 19454, 31928, 40278, 46123, 50376, 53171, 56251,
59513, 64337, 70933, 79772, 89387, 96414, 95775, 78450,
37160]
meigo = [823, 1247, 3937, 9029, 16811, 27252, 38040, 48720, 59644,
70950, 79952, 87227, 89056, 88087, 84676, 77895, 67556,
54606, 38438, 22741, 9326, 1237]
pkokugo = [12397, 17864, 25613, 33122, 41213, 50515, 61704, 74986,
90369, 106214, 119035, 128841, 125067, 102322, 51240]
psansuu = [2483, 6363, 16106, 27530, 38028, 48859, 61497, 74694,
91659, 108309, 125896, 139305, 137438, 109090, 53222]
ついでに主成分分析をしてみる:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.decomposition import PCA
import pandas as pd
kenmei = ["北海道", "青森", "岩手", "宮城", "秋田", "山形", "福島", "茨城",
"栃木", "群馬", "埼玉", "千葉", "東京", "神奈川", "新潟", "富山",
"石川", "福井", "山梨", "長野", "岐阜", "静岡", "愛知", "三重",
"滋賀", "京都", "大阪", "兵庫", "奈良", "和歌山", "鳥取", "島根",
"岡山", "広島", "山口", "徳島", "香川", "愛媛", "高知", "福岡",
"佐賀", "長崎", "熊本", "大分", "宮崎", "鹿児島", "沖縄"]
df = pd.read_csv("https://okumuralab.org/~okumura/python/data/atest2019.csv")
pca = PCA(n_components=2)
y = pca.fit_transform(df)
plt.clf()
plt.xlim(min(y[:,0]), max(y[:,0]))
plt.ylim(min(y[:,1])-0.2, max(y[:,1])+0.2)
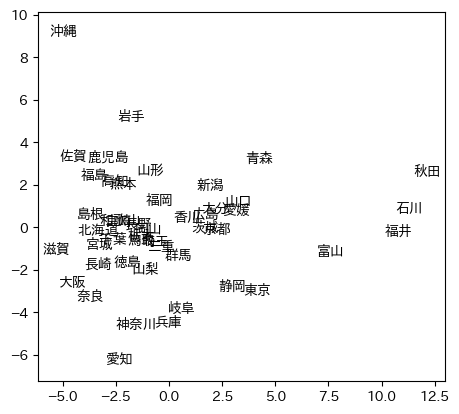
for i in range(47):
plt.text(y[i,0], y[i,1], kenmei[i],
horizontalalignment='center', verticalalignment='center')
plt.axis('scaled')
plt.savefig('atest2019pca1.png', bbox_inches="tight")
各主成分の分散の割合は pca.explained_variance_ratio_ で調べられる。第一主成分61.8%,第二主成分26.6%である。回転後の座標軸は次の通り:
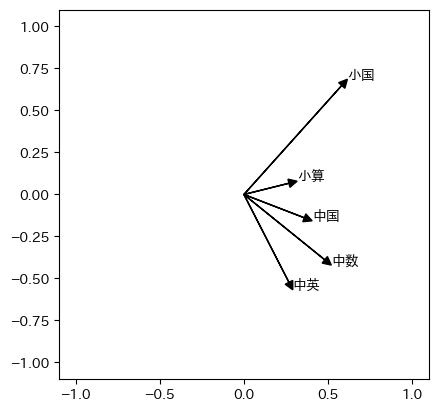
r = pca.components_
plt.clf()
plt.xlim(-1, 1)
plt.ylim(-1, 1)
for i in range(5):
plt.arrow(0, 0, r[0,i], r[1,i], head_width=0.05,
head_length=0.05, length_includes_head=True, color='black')
plt.text(r[0,i], r[1,i], df.columns[i])
plt.axis('scaled')
plt.savefig('atest2019pca2.png', bbox_inches="tight")
Last modified: