2019年7月21日の参院選比例代表で選管が山田太郎と山本太郎を混同する事故があった。山田太郎票515票を山本太郎票に 職員思い込みで富士宮市選管集計ミス:「22日に発表した確定票は山本氏1453票、山田氏0票だったが、訂正後は山本氏938票、山田氏515票になる」。
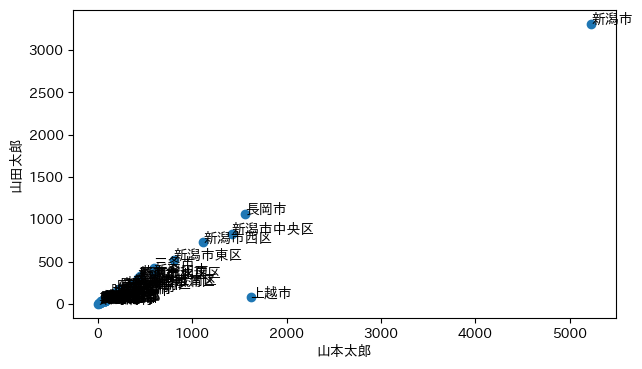
上越市でも同様の疑念がある。新潟・上越市でも山田太郎氏の票少なく 選管「開票は適正」によれば,「公職選挙法に基づく訴訟を起こされない限り、票の再確認はできない」とのこと。
新潟県の開票区ごとの山田票,山本票をCSVにした niigata2019.csv を置いておく(BOM付きUTF-8,行末CRLF)。
これを読んでプロットしてみよう。両軸の目盛が等しくなるようにした。
import matplotlib.pyplot as plt
import pandas as pd
niigata = pd.read_csv("niigata.csv")
plt.figure(figsize=[7, 4])
plt.plot(niigata["山本太郎"], niigata["山田太郎"], "o")
plt.axis('equal')
for i, v in niigata.iterrows():
plt.text(v["山本太郎"], v["山田太郎"], v["開票区名"])
plt.xlabel("山本太郎")
plt.ylabel("山田太郎")
plt.savefig('190724a.png', bbox_inches="tight")
ついでに三重県も調べてみた。データは mie2019.csv である(BOM付きUTF-8,行末CRLF)。
plt.figure(figsize=[7, 4])
plt.plot(mie["山本太郎"], mie["山田太郎"], "o")
plt.axis('equal')
for i, v in mie.iterrows():
plt.text(v["山本太郎"], v["山田太郎"], v["開票区名"])
plt.xlabel("山本太郎")
plt.ylabel("山田太郎")
さらに,四日市市以外の傾向を直線で書き込んでみる:
plt.plot([0, mie["山本太郎"][mie["開票区名"] != "四日市市"].sum()],
[0, mie["山田太郎"][mie["開票区名"] != "四日市市"].sum()],
scalex=False, scaley=False)
plt.savefig('190724b.png', bbox_inches="tight")
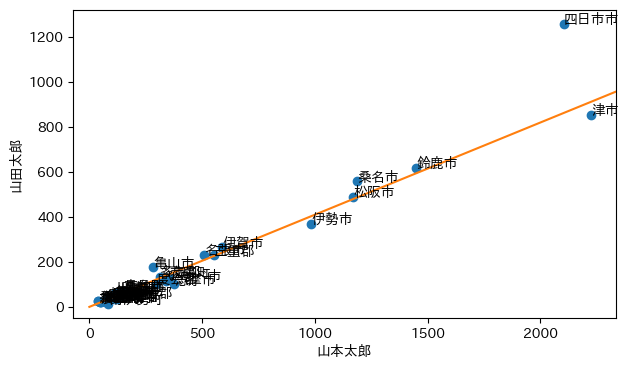
四日市市は外れ値といえるであろうか。
両対数グラフにしてみる:
plt.figure(figsize=[5, 5])
...
plt.xscale('log')
plt.yscale('log')
plt.savefig('190724d.png', bbox_inches="tight")
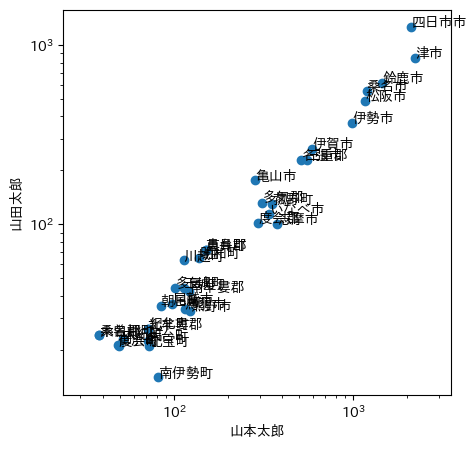
対数にすると,人口の少ない(したがって統計誤差の大きい)開票区の誤差が強調されて,大都市が目立たなくなってしまうのであろう。
両候補の得票率でもプロットしてみよう。
plt.plot(mie['山本太郎']/mie['投票者数'], mie['山田太郎']/mie['投票者数'], "o")
for i, v in mie.iterrows():
plt.text(v["山本太郎"]/v['投票者数'], v["山田太郎"]/v['投票者数'], v["開票区名"])
plt.axis('equal')
plt.xlabel("山本太郎得票率")
plt.ylabel("山田太郎得票率")
plt.savefig('190724c.png', bbox_inches="tight")
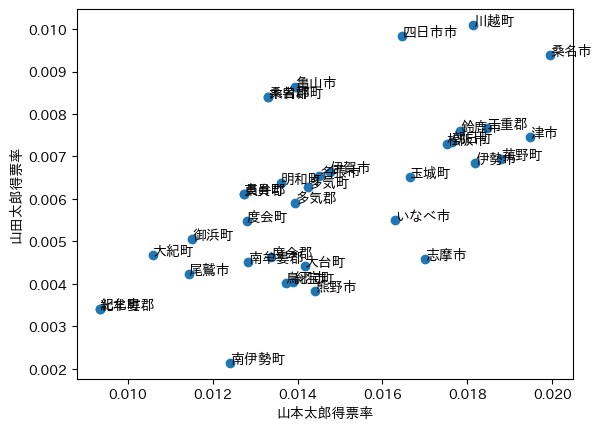
四日市市が目立たなくなってしまった。これは,人口の少ない(したがって統計誤差の大きい)開票区がランダムに散らばったためであろう。
要は,グラフの描き方で印象が変わってしまうので,注意しなければならないということである。
[2019-07-25追記] 新潟県上越市の場合は,両対数グラフにしたり得票率にしたりすることで埋没しないほどの大きな違いがある:
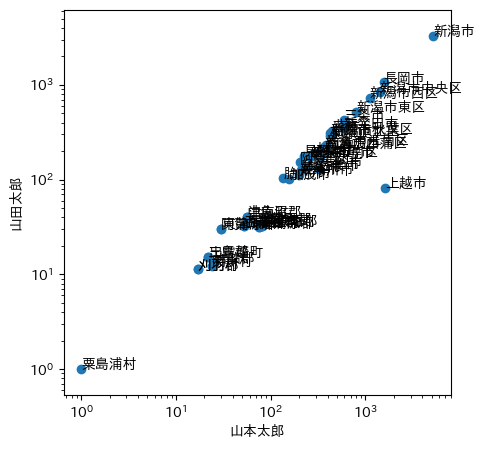
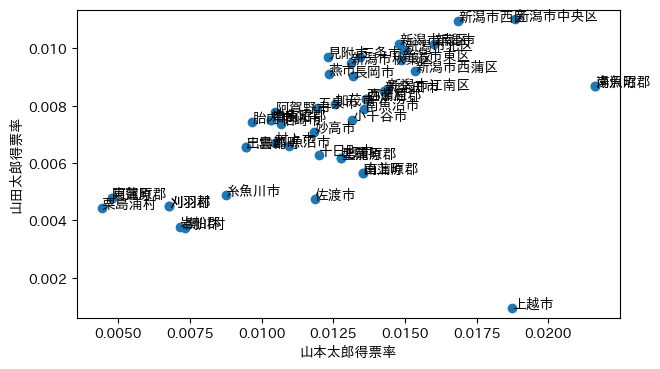
[2019-08-07追記] 同じ参院選で,大阪府堺市美原区でも,少なくとも4人が投票したはずの共産党の山下芳生(よしき)候補が得票0だという(朝日新聞 投票した候補者の得票0 再調査要求…選管「できない」 など参照)。数え間違いはいたるところで起こっているのかもしれない。
Last modified: